
目录
随着近期ChatGPT的火热,引发各行各业都开始讨论AI,以及AI可以如何应用到各个细分场景。为了不被时代“抛弃”,我也投入了相当的精力用于研究和探索。但在试验的过程中,我的直观感受是,NLP很厉害,但GPT并不好用,反倒是BERT更加顺手,如臂使指。
同样是大语言模型,那引爆AI浪潮的,为什么是GPT,而不是BERT呢?尝试对这个话题进行一下探讨。
BERT和GPT简介
Encoder-Decoder是NLP中的经典架构:Encoder对文本进行编码,输出Embedding;Decoder基于Embedding进行计算,完成各种任务,得到输出。示例如下:

之所以会诞生这种架构,个人认为,是因为对文本进行特征工程,转化为机器可以处理的向量,是一件反人类的事情。因此,专门设计了Encoder来完成这个工作。
2017年,Google提出了Transformer,在性能、结果、稳定性等多个方面都优于RNN模型,使得NLP领域进入了下一个阶段。紧接着2018年,Google基于Transformer架构,提出了BERT,将“预训练”这一模式发扬光大。而随着OpenAI炼丹多年,发布了ChatGPT,将NLP带入大众视野,使得GPT变成了当前的主流。
BERT和GPT的实现原理,简单来说就是:BERT是Encoder-only,即上图的左半边;GPT是Decoder-only,即上图的右半边。
具体来说,BERT的最终输出其实是Embedding,它并不关注任务具体是什么。而这个Embedding足够好用,使得其可以通过拼接其他算法,完成各种任务(比如基于Embedding去分类)。
而GPT则是有固定任务的,predict next word。GPT的工作模式,就是通过不断的predict next word,拼接成完整的语句,得到结果。这就是所谓的“生成式”。
各类NLP算法的工作范式如下:

三个阶段的NLP技术范式。引用自:关于ChatGPT:GPT和BERT的差别(易懂版) - 知乎
BERT和GPT核心差异
BERT的核心产出是Embedding。在接触之后,Embedding的效果可以用“惊艳”来形容。下面基于几个具体示例来展示Embedding的强大之处:
TransE
在知识图谱中,有一种基于距离的模型,可以用来完成两个实体间关系的挖掘和构建。其大致效果如下:
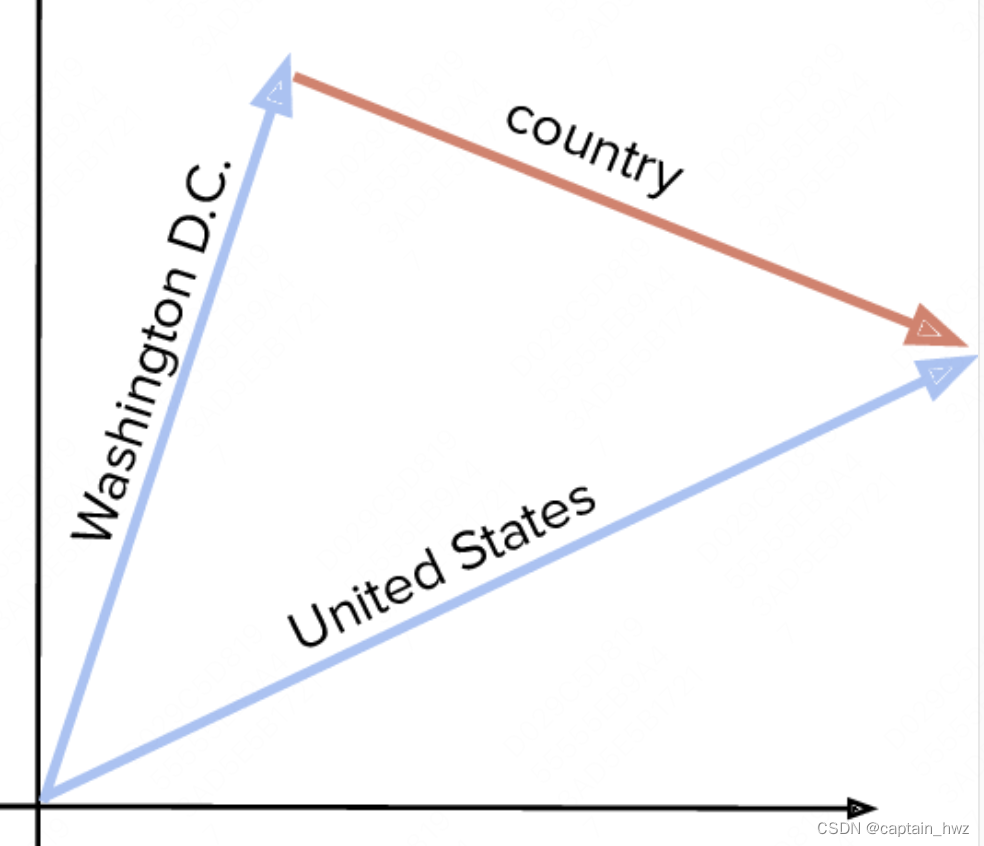
Washington和US作为两个实体,被Embedding后,形成了一个类似于力矩的空间,可以轻松完成各种加减运算,得到目标结果。
KeyBert
类似的,在文本摘要任务中,有一种基于余弦相似度的算法。其原理和TransE类似,在Embedding把文本进行向量化表示的情况下,Embedding之间的余弦相似度就等同于词义之间的相似度。
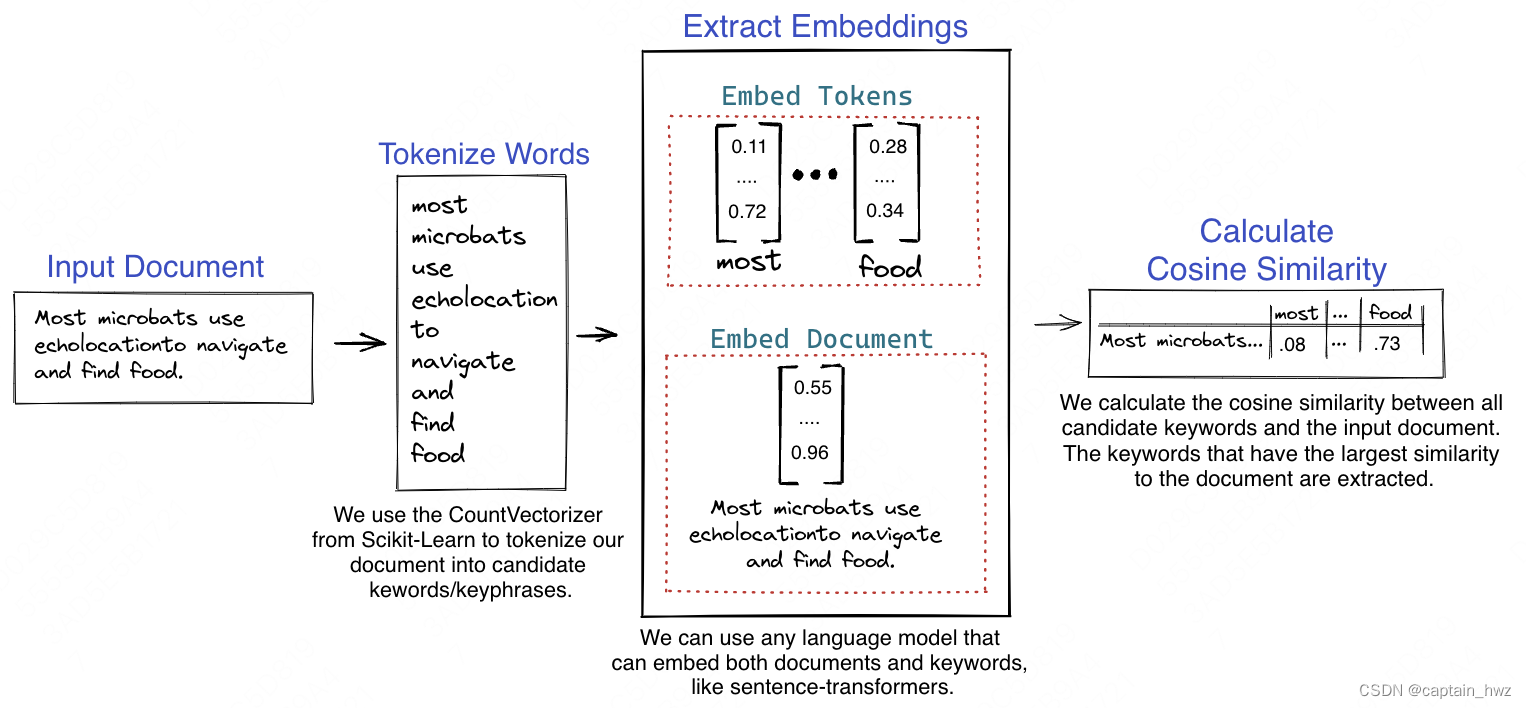
机器擅长于处理向量的各种运算,但语言是一种非结构化的信息,这是两者之间最大的GAP。为了调和这个GAP,我们设计了各种各样的编程语言,由人来完成自然语言到机器语言的转化工作。但Embedding的出现,让机器能够自己将自然语言进行向量化表示,并且向量化结果还能够匹配人类所理解的各种语言和认知逻辑,这也是我认为机器理解人类世界的关键所在。
与BERT专注于编码不同,GPT专注于回答问题。我认为这也是GPT的Decoder-only架构在结果表现上最核心的优势:
- 对于BERT来说,Encoder生产完Embedding只是第一步,还需要嵌套一层其他算法,才能完成具体任务。而由于Embedding比较好用,往往又不倾向于再叠加更复杂的算法,基本都是一个线性层+softmax搞定。
- 对于GPT来说,则不关注中间过程,直接回答结果。因此,在同等参数量级情况下,理论上Decoder-only会有更多的资源投入到完成任务中去,所以会获得更好的结果表现。
因此,ChatGPT表现出了通用智能的效果(完成任务能力更强),而BERT仍然需要经过特定领域的fine-tuning(每个领域下的embedding逻辑并不通用),才能完成应用。
关于为什么现在LLM都在搞Decoder-only,知乎上有相关讨论(为什么现在的LLM都是Decoder only的架构? - 知乎),但没有明确结论。基于讨论内容,个人倾向于判断,各种架构在结果上其实是没有太大差异的,纯粹是因为现在大家都追求高效&通用,所以更适合Decoder-only来进行处理。
进一步展开,BERT和GPT的核心差异,我认为在于这个中间结果,Embedding。
 当大家都在讨论GPT随着参数量的扩增,出现智能的“涌现”时,我尝试去思考了一个问题:为什么没人去扩增BERT的参数量?搜索良久不得答案后,我想到了一个可能:“够用了”。
当大家都在讨论GPT随着参数量的扩增,出现智能的“涌现”时,我尝试去思考了一个问题:为什么没人去扩增BERT的参数量?搜索良久不得答案后,我想到了一个可能:“够用了”。
Embedding是为了具体任务而生的,不同场景下,同一个词会展现为不同的词性,因此需要通过fine-tuning来让BERT迁移到不同的领域中去。而当模型只是为了完成某个特定领域的任务,扩增参数就变得完全没有必要了。而反过来,Embedding也限制了BERT只能成为特定领域的专家工具,具备较高的使用门槛,因此很难得到普及。
GPT的优势
OpenAI最大的功劳,应该是设计出了对话模式,大幅度降低了AI的“体验”门槛(注意,是体验,不是应用),从而让各行各业都开始关注AI的变化和可能。
那么,冷静下来思考,GPT的强大之处到底是什么呢。是GPT能够处理非结构化的文本信息吗?是GPT所拥有的庞大知识储备吗?我认为,这都不是GPT的独有能力,BERT增加参数量和训练量后应该同样能够做到。

而人们真正感到兴奋的,应该是GPT展现出来的创造能力。在这之前,机器无法取代人类的场景,基本都是多领域融合的问题。比如写文档、编程,不是仅仅会打字和懂语法就够了,你还得理解背后的业务逻辑,才能够完成。(类比于翻译,虽然也会涉及一定的专业背景,但即使啥都不懂,依靠词典和例句,也能翻译个大概。所以过往机器能够完成翻译任务。)而这种多领域融合的创造能力,是GPT在结合“Transformer的知识储备”和“生成式的通用解题范式”,所带来的独有能力。
- BERT虽然也有强大的知识储备,但完成任务的模式相对固定。如果要处理复杂任务,还得训练同等量级的Decoder,反倒不如GPT的Decoder-only来得直接。
- RNN虽然是生成式的,但串型结构带来的效率瓶颈和遗忘问题,限制其了知识储备。
因此,GPT的这种创造力,可以大幅度扩展AI的应用场景,使得更多的人类工作被替代。
GPT的劣势
既然GPT拥有更好的通用性,那我们应该万物皆GPT嘛?我倒觉得大可不必。
ROI考量
任何能力的扩增,其实都会带来运算成本的增长,因此,我们需要在ROI上进行考量。
举个简单的例子,你要完成一个数学运算,是使用计算器合适,还是问GPT更合适呢?答案显然是前者,哪怕GPT增加插件模式,可以准确完成数学运算,但它的计算开销是远高于计算器本身的。同理,在流水线工作中,使用单一功能的机器,ROI也远高于雇一个人。

所以,越是固定的任务,其所需要的模型能力越低。明明有固定的输入输出模式,非得转成对话模式去做处理,多少有点“杀鸡用牛刀”的感觉了。
数据量限制
目前GPT(或者NLP领域)能够处理的输入长度都是有限制的。相比于其内部计算的百亿级参数,几千个token的输入长度,多少显得有点不够看了。
语言是一种非结构化信息,它的信息传输效率是远低于结构化的特征的。过去在进行推荐、分类等各种任务时,我们可以人工运算出十万维度的特征来,交由模型去进行处理。但在GPT模式下,如何把这十万维的特征以文本的形态输入GPT进去呢?又或者,可以在GPT之前增加一个Encoder来负责处理。但这样一来,通用性无法得到保障,很可能需要自己训练一个GPT,而不是直接使用大公司预训练好的模型。
 因此,GPT目前更擅长的,其实是引经据典,回答各种知识点性质的问题。而对于基于庞大输入完成的综合决策过程,并不适合使用GPT来解决。
因此,GPT目前更擅长的,其实是引经据典,回答各种知识点性质的问题。而对于基于庞大输入完成的综合决策过程,并不适合使用GPT来解决。
总结
本篇一定程度上是因面对GPT的过度吹捧,有感而发。个人认为,目前火热的不是GPT,而是ChatGPT把AI重新带回大众视野,引发了更多的AI应用尝试。
而这波热潮带给我的最大收益,是引发了NLP对于非结构化数据的处理能力的研究思考,应当能够解决过往很多数据处理的难题。
 至于GPT本身,因为接收输入的不足,我认为不足以作为一个线上功能去使用。(所以现在的产品形态基本都是Copilot,相当于更高阶版的搜索引擎。)但其展现的创造性潜力,确实值得我们保持关注和探索。
至于GPT本身,因为接收输入的不足,我认为不足以作为一个线上功能去使用。(所以现在的产品形态基本都是Copilot,相当于更高阶版的搜索引擎。)但其展现的创造性潜力,确实值得我们保持关注和探索。
版权归原作者 captain_hwz 所有, 如有侵权,请联系我们删除。