
该文章分享我在 Kaggle竞赛 LLM - Detect AI Generated Text 中拿到铜牌的解决方案和具体代码,以及如何在 Kaggle 平台上提交代码结果。
主要用了机器学习集成模型投票法以及TF-IDF特征表示,可以用作项目练手。
一、赛题介绍
地址:LLM - Detect AI Generated Text | KaggleLLM - Detect AI Generated Text | KaggleLLM - Detect AI Generated Text | Kaggle
1、任务描述
你能帮忙建立一个模型来识别哪篇文章是初中生和高中生写的,哪篇是用大型语言模型(LLM)写的吗?随着 LLM 的发展,许多人担心它们会取代或改变通常由人类完成的工作。学术界对 LLM 的担忧是它们可能造成剽窃。LLM 是在大量的文本和代码数据集上训练的,这意味着它们能够生成与人类编写的文本非常相似的文本。例如,学生可以使用LLM来生成不属于他们自己的论文。
大型语言模型 (LLM)能够生成难以与人类编写的文本区分开来的文本。这项竞赛要求参赛者开发一个机器学习模型,该模型可以准确检测论文是由学生还是 LLM 撰写的。竞赛数据集包括学生撰写的论文和由各种LLM生成的论文。
2、数据集
竞赛数据集包括大约 10,000 篇论文,其中一些由学生撰写,一些由各种大型语言模型 (LLM) 生成。比赛的目的是确定论文是否由 LLM 生成。
所有的文章都是根据七个论文提示之一而写的。在每个提示中,学生被指示阅读一个或多个源文本,然后写下答案。在生成论文时,相同的信息可能提供给 LLM。
请注意,这是一场代码竞赛。示例测试集中的数据只是虚拟数据,用于帮助生成解决方案。对提交的内容进行评分后,此示例测试数据将替换为完整的测试集。测试集中大约有 9,000 篇论文,包括学生撰写的和 LLM 生成的。
- {train|test}_essays.csv-
id- 每篇文章的唯一标识符。-prompt_id- 标识文章的响应提示。-text- 论文文本本身。-generated- 论文是由学生(0)撰写的,还是由 LLM (1)撰写的。此字段是目标字段,在测试集中不存在。 - train_prompts.csv - 论文是针对这些领域的信息而写的。 -
prompt_id- 每个提示的唯一标识符。-prompt_name- 提示的标题。-instructions- 给学生的指示。-source_text- 文章的文本是作为回应而写的,以 Markdown 格式。重要段落由同一行的段落前面的数字枚举,如 中所示。散文有时用数字来指代一个段落。每篇文章的标题前面都有一个标题,如 .当注明作者时,他们的名字将在标题后面给出。并非所有文章都有作者注明。一篇文章可能有类似 .0 Paragraph one.\n\n1 Paragraph two.``````# Title``````by``````## Subheading - sample_submission.csv - 格式正确的提交文件。有关详细信息,请参阅评估页面。
更详细的信息见赛题官网。
二、解决方案
该问题是一个二分类问题,即对一段文本判断是否由 LLM 生成。
在数据处理方面,我采用的处理方法是:先用 BPE 对数据进行分词,然后用 TF-IDF 进行特征表示。
模型方面,我集成了四个分类模型,采取投票法进行组合。
该方案在公榜上得分0.96,私榜上0.90。在比赛结束时拿到了铜牌。

让我们通过一个具体的例子来说明将经过 Byte Pair Encoding (BPE) 处理的文本数据应用于 TF-IDF 特征表示的过程。
假设我们有以下两个句子作为我们的文本数据:
句子1: "I like playing soccer." 句子2: "I like playing basketball."
首先,我们将这些句子进行 BPE 处理,得到如下的子词单元:
句子1: ["I", "like", "play", "ing", "soccer", "."] 句子2: ["I", "like", "play", "ing", "basketball", "."]
接下来,我们需要计算每个子词单元的 TF-IDF 值。假设我们有一个包含多个文本样本的文本集合,其中包含以上两个句子。我们可以使用这个文本集合来计算 TF-IDF 值。
首先,我们计算每个子词单元在每个句子中的词频(TF)。例如,在句子1中,"I"、"like"、"play"、"ing"、"soccer" 和 "." 的词频分别为 1、1、1、1、1 和 1。在句子2中,它们的词频分别为 1、1、1、1、1 和 1。
接下来,我们计算每个子词单元的逆文档频率(IDF)。IDF 值表示子词单元在整个文本集合中的重要性。一种常见的计算 IDF 的方法是使用以下公式:
IDF(t) = log(DF(t) / N)
其中,N 是文本集合中的文本样本总数,DF(t) 是包含子词单元 t 的文本样本的数量。
假设我们的文本集合中有 100 个文本样本,其中包含句子1和句子2。那么,子词单元 "I"、"like"、"play"、"ing"、"soccer" 和 "." 的逆文档频率可以计算如下:
IDF("I") = log(100/100) = 0
IDF("like") = log(100/100) = 0
IDF("play") = log(100/100) = 0
IDF("ing") = log(100/100) = 0
IDF("soccer") = log(100/1) ≈ 4.605
IDF(".") = log(100/100) = 0
最后,我们将 TF 和 IDF 相乘,得到每个子词单元在每个句子中的 TF-IDF 值。例如,在句子1中,"I"、"like"、"play"、"ing"、"soccer" 和 "." 的 TF-IDF 值分别为 0、0、0、0、4.605 和 0。在句子2中,它们的 TF-IDF 值分别为 0、0、0、0、0 和 0。
这样,我们就得到了经过 BPE 处理后的文本数据的 TF-IDF 特征表示。它是一个稀疏矩阵,每一行代表一个句子,每一列代表一个子词单元,而矩阵中的每个元素表示该子词单元在对应句子中的 TF-IDF 值。
请注意,这只是一个简化的例子,实际应用中可能涉及更多的文本样本和子词单元。
三、代码实现(附逐行代码)
1、导入相关库
# 导入 pandas 库,用于数据分析和处理
import pandas as pd
# 导入 json 库,用于处理 JSON 数据格式
import json
# 导入 sys 库,用于访问系统特定的参数和函数
import sys
# 导入 gc 库,用于控制垃圾回收器
import gc
# 导入 StratifiedKFold 类,用于执行分层 K 折交叉验证
from sklearn.model_selection import StratifiedKFold
# 导入 numpy 库,用于科学计算和线性代数
import numpy as np
# 导入 roc_auc_score 函数,用于计算特征曲线下的面积
from sklearn.metrics import roc_auc_score
# 导入 LGBMClassifier 类,用于训练和使用 LightGBM 模型
from lightgbm import LGBMClassifier
# 导入 TfidfVectorizer 类,用于将文本转换为 TF-IDF 特征
from sklearn.feature_extraction.text import TfidfVectorizer
# 从 tokenizers 库导入各种类和函数,用于创建和使用自定义分词器
from tokenizers import (
decoders,
models,
normalizers,
pre_tokenizers,
processors,
trainers,
Tokenizer,
)
# 导入 Dataset 类,用于以标准化的方式处理数据集
from datasets import Dataset
# 导入 tqdm 库,用于显示进度条
from tqdm.auto import tqdm
# 导入 PreTrainedTokenizerFast 类,用于使用 transformers 库中的快速分词器
from transformers import PreTrainedTokenizerFast
# 导入 SGDClassifier 类,用于训练和使用随机梯度下降模型
from sklearn.linear_model import SGDClassifier
# 导入 MultinomialNB 类,用于训练和使用多项式朴素贝叶斯模型
from sklearn.naive_bayes import MultinomialNB
# 导入 VotingClassifier 类,用于将多个分类器组合成一个
from sklearn.ensemble import VotingClassifier
2、加载数据集
'''
数据集介绍:
test_essays.csv:包含一组3篇需要分类为人工生成或机器生成的文章。
sample_submission.csv:演示了预期的提交文件格式,包含两列:id和label。
train_essays.csv:包含一个由1378篇文章组成的数据集,附带相应的标签(0表示人工生成,1表示机器生成)。该文件用作训练集,用于开发用于检测AI生成文本的机器学习模型。
'''
test = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/test_essays.csv')
# org_train = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/train_essays.csv')
train = pd.read_csv("/kaggle/input/daigt-v2-train-dataset/train_v2_drcat_02.csv", sep=',')
sub = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/sample_submission.csv')
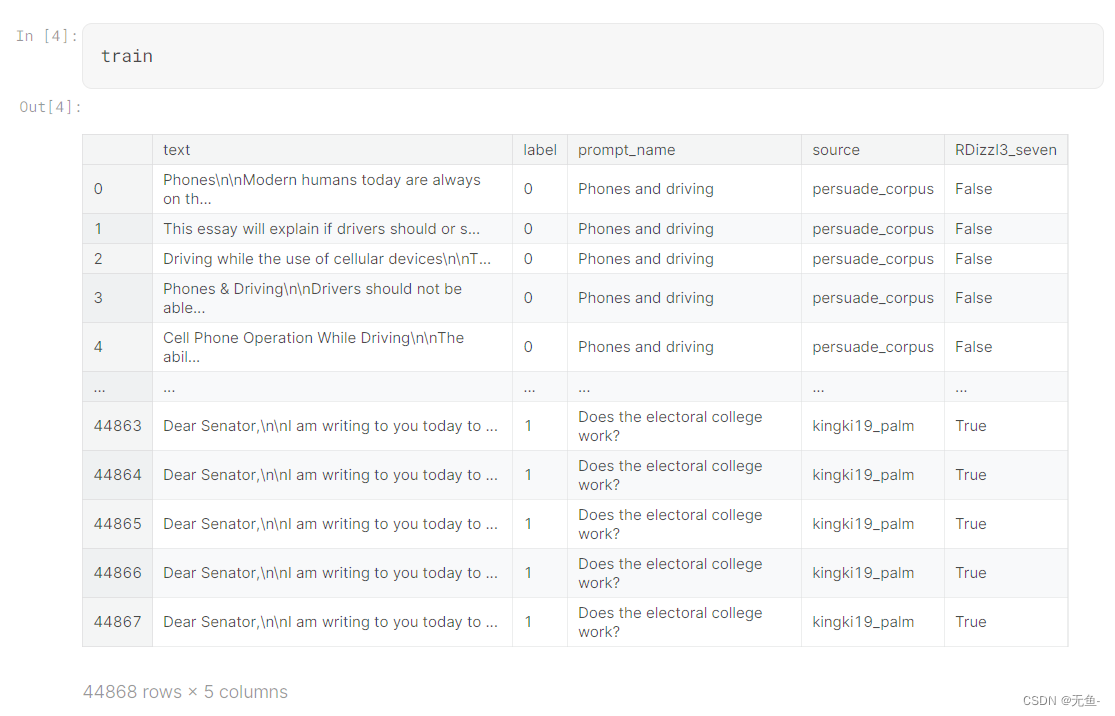
训练集如下图所示:
3、数据预处理:去重 + 分词
# 去重
train = train.drop_duplicates(subset=['text'])
train.reset_index(drop=True, inplace=True)
test = test.drop_duplicates(subset=['text'])
test.reset_index(drop=True, inplace=True)
# 将LOWERCASE标志设置为False。这意味着在分词之前,文本不会被转换为小写
LOWERCASE = False
# 下面的代码将VOCAB_SIZE设置为14000000。这意味着词汇表中的最大单词数将为1400万。
VOCAB_SIZE = 14000000
# 使用字节对编码分词器进行文本分词
# 使用字节对编码(Byte Pair Encoding,BPE)算法创建分词器对象
raw_tokenizer = Tokenizer(models.BPE(unk_token="[UNK]"))
# 通过应用Unicode标准化形式C(NFC)对文本进行标准化,并可选择将其转换为小写
raw_tokenizer.normalizer = normalizers.Sequence([normalizers.NFC()] + [normalizers.Lowercase()] if LOWERCASE else [])
# 通过将文本拆分成字节来进行预分词
raw_tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel()
# 定义用于下游任务的特殊标记
special_tokens = ["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"]
# 创建一个训练器对象,该对象将在给定的词汇表大小和特殊标记上训练分词器
trainer = trainers.BpeTrainer(vocab_size=VOCAB_SIZE, special_tokens=special_tokens)
# 从pandas数据框中加载测试数据集,并仅选择文本列
dataset = Dataset.from_pandas(test[['text']])
# 定义一个生成器函数,用于从数据集中生成文本批次
def train_corp_iter():
for i in range(0, len(dataset), 1000):
yield dataset[i : i + 1000]["text"]
# 使用训练器对象对文本批次进行分词器训练
raw_tokenizer.train_from_iterator(train_corp_iter(), trainer=trainer)
# 将原始分词器对象封装为与HuggingFace库兼容的PreTrainedTokenizerFast对象
tokenizer = PreTrainedTokenizerFast(
tokenizer_object=raw_tokenizer,
unk_token="[UNK]",
pad_token="[PAD]",
cls_token="[CLS]",
sep_token="[SEP]",
mask_token="[MASK]",
)
# 初始化一个空列表,用于存储测试集的分词后的文本
tokenized_texts_test = []
# 遍历测试集中的文本,并使用分词器对象对其进行分词
for text in tqdm(test['text'].tolist()):
tokenized_texts_test.append(tokenizer.tokenize(text))
# 初始化一个空列表,用于存储训练集的分词后的文本
tokenized_texts_train = []
# 遍历训练集中的文本,并使用分词器对象对其进行分词
for text in tqdm(train['text'].tolist()):
tokenized_texts_train.append(tokenizer.tokenize(text))
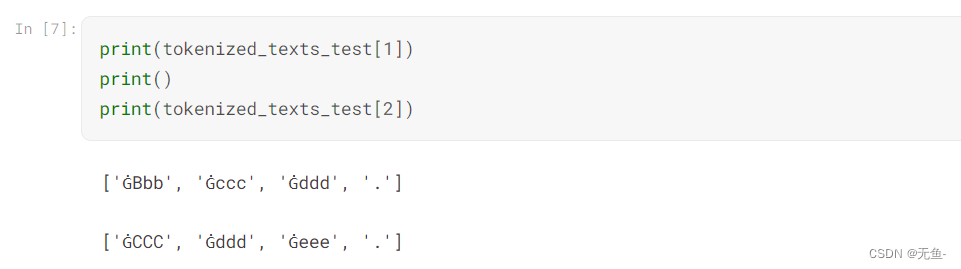
 在示例测试集上查看分词结果:
在示例测试集上查看分词结果:
4、特征工程:TF-IDF
# 定义一个返回输入文本的虚拟函数
def dummy(text):
return text
# 创建一个TfidfVectorizer对象,从文本中提取词的n-gram(3到5个词),不转换为小写或进行分词
vectorizer = TfidfVectorizer(ngram_range=(3, 5),
lowercase=False,
sublinear_tf=True,
analyzer='word',
tokenizer=dummy,
preprocessor=dummy,
token_pattern=None, strip_accents='unicode')
# 在测试集的分词文本上拟合向量化器
vectorizer.fit(tokenized_texts_test)
# 获取向量化器的词汇表,它是一个n-gram和它们的索引的字典
vocab = vectorizer.vocabulary_
# 打印词汇表
# print(vocab)
# 创建另一个TfidfVectorizer对象,使用之前向量化器获得的词汇表,但参数保持不变
vectorizer = TfidfVectorizer(ngram_range=(3, 5), lowercase=False, sublinear_tf=True, vocabulary=vocab,
analyzer='word',
tokenizer=dummy,
preprocessor=dummy,
token_pattern=None, strip_accents='unicode')
# 在训练集的分词文本上拟合和转换向量化器,并获取tf-idf值的稀疏矩阵
tf_train = vectorizer.fit_transform(tokenized_texts_train)
# 在测试集的分词文本上转换向量化器,并获取tf-idf值的稀疏矩阵
tf_test = vectorizer.transform(tokenized_texts_test)
# 删除向量化器对象以释放内存
del vectorizer
# 调用垃圾回收器以回收未使用的内存
gc.collect()
y_train = train['label'].values
5、模型选择:模型组合 + 投票法
# 定义一个函数,返回一个由四个分类器组成的集成模型
def get_model():
# 从catboost库中导入CatBoostClassifier
from catboost import CatBoostClassifier
# 创建一个Multinomial Naive Bayes分类器,平滑参数为0.0235
clf = MultinomialNB(alpha=0.0225)
# 创建一个Stochastic Gradient Descent分类器,最大迭代次数为9000,容差为3e-4,使用修改后的Huber损失函数,随机种子为6743
sgd_model = SGDClassifier(max_iter=9000, tol=1e-4, loss="modified_huber", random_state=42)
# 定义一个LightGBM分类器的参数字典
p = {
'verbose' : -1,
'n_iter' : 3000,
'colsample_bytree' : 0.7800,
'colsample_bynode' : 0.8000,
'random_state' : 6743,
'metric' : 'auc',
'objective' : 'cross_entropy',
'learning_rate' : 0.00581909898961407,
}
# 使用给定的参数创建一个LightGBM分类器
lgb=LGBMClassifier(**p)
# 创建一个CatBoost分类器,迭代次数为6000,学习率为0.003599066836106983,子样本比例为0.4,使用交叉熵损失函数,随机种子为6543
cat=CatBoostClassifier(iterations=3000,
verbose=0,
random_seed=42,
learning_rate=0.005599066836106983,
subsample = 0.35,
allow_const_label=True,
loss_function = 'CrossEntropy'
)
# 定义一个四个分类器的权重列表
weights = [0.1, 0.31, 0.28, 0.67]
# 创建一个投票分类器,使用软投票和并行处理,将四个分类器组合起来
ensemble = VotingClassifier(estimators=[('mnb',clf),
('sgd', sgd_model),
('lgb',lgb),
('cat', cat)
],
weights=weights, voting='soft', n_jobs=-1)
# 返回集成模型
return ensemble
# 调用get_model函数,并将返回的模型赋值给一个变量
model = get_model()
# 打印模型
print(model)

6、模型预测
# 检查测试文本值的长度
if len(test.text.values) <= 5:
# 如果长度小于等于5,将提交的数据框保存为csv文件
sub.to_csv('submission.csv', index=False)
else:
# 否则,将模型拟合于训练集的tf-idf矩阵和目标标签上
model.fit(tf_train, y_train)
# 调用垃圾回收器以回收未使用的内存
gc.collect()
# 使用模型预测测试集上正类别的概率
final_preds = model.predict_proba(tf_test)[:,1]
# 将预测的概率赋值给提交数据框的生成列
sub['generated'] = final_preds
# 将提交数据框保存为csv文件
sub.to_csv('submission.csv', index=False)
# 显示提交数据框
sub.head()
四、提交结果
该比赛是代码竞赛,意味着我们要提交的不是预测出来的结果,而是我们解决问题的完整代码。
所以我们需要先在 Kaggle 上该比赛的位置创建一个 notebook 并把我们的代码复制粘贴上去。
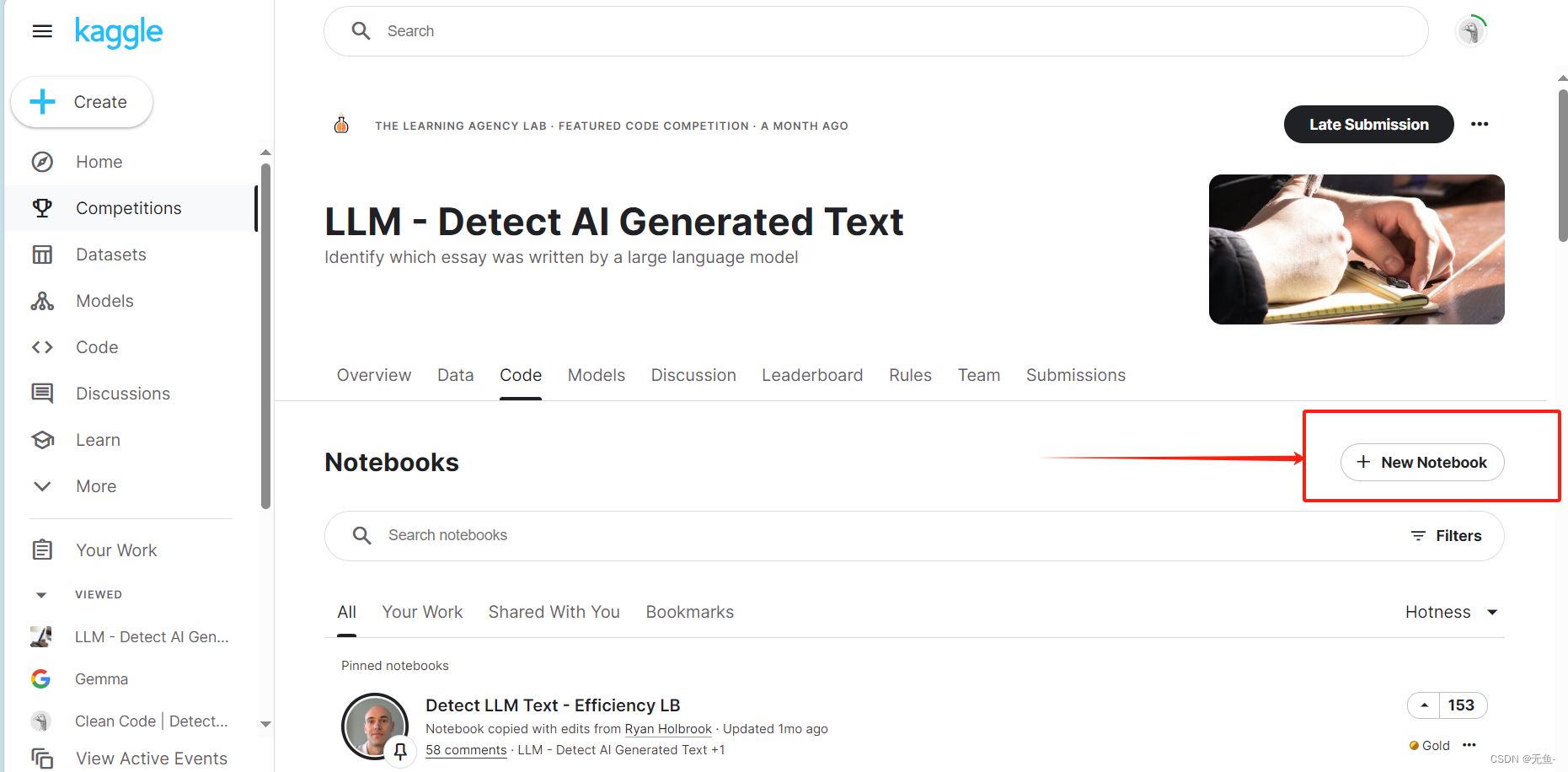
然后保存我们的代码。注意,在保存时会自动运行我们的代码,如果代码有bug就会保存失败。
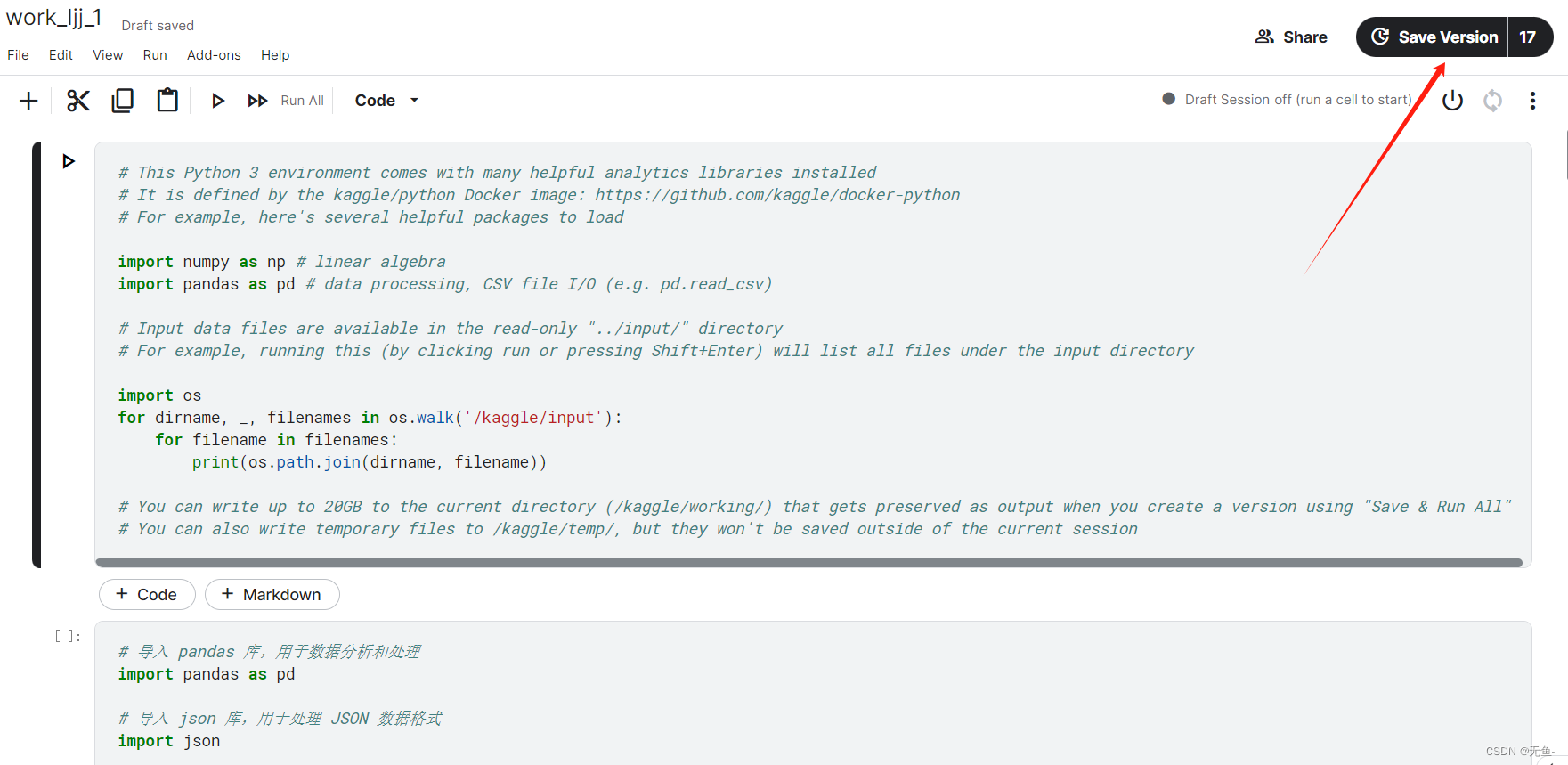
然后点击 Late Submission

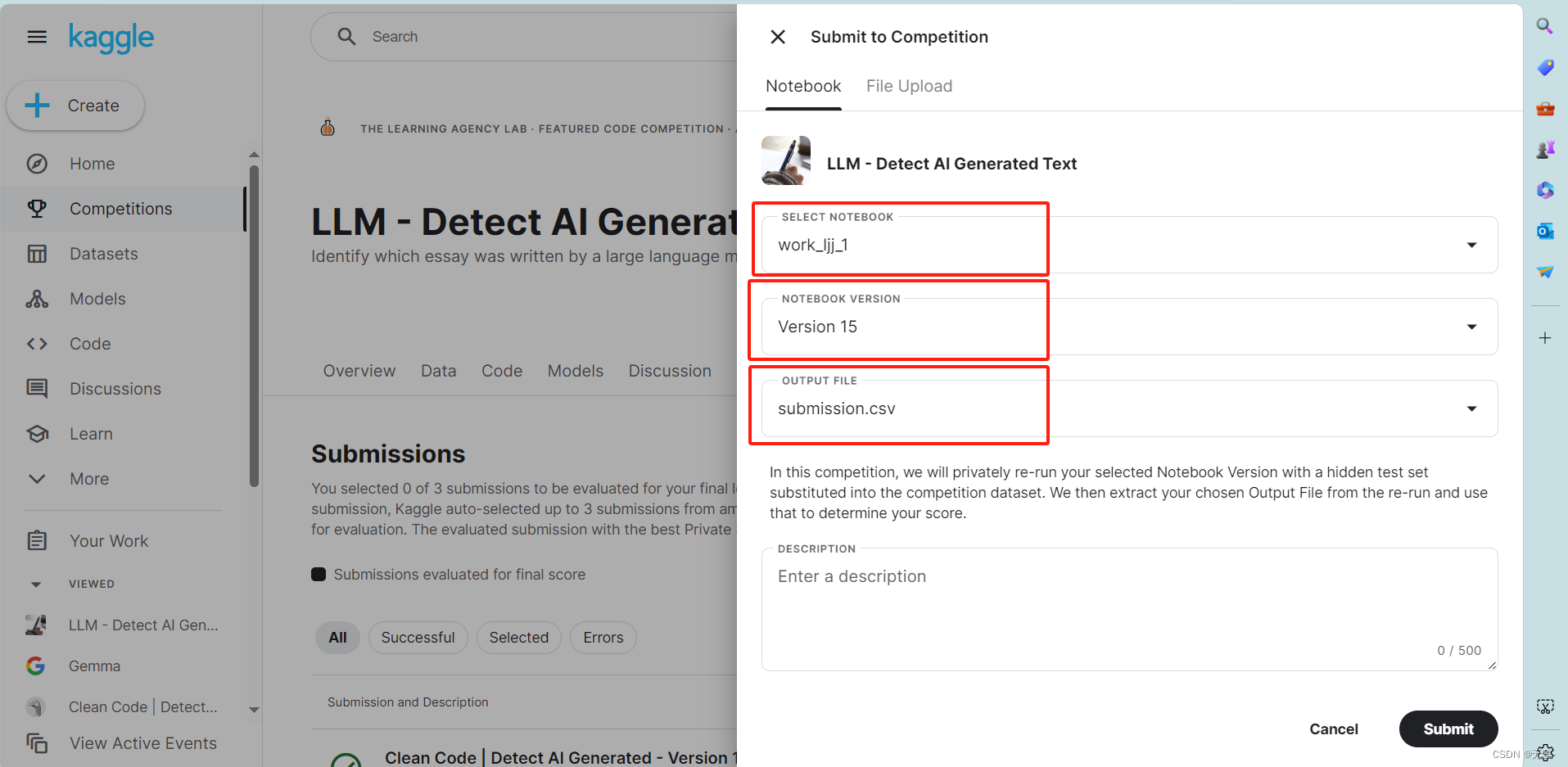
然后选择要提交的代码文件和版本。对于该比赛来说,模型需预测示例测试集的目标值并生成 一个结果文件(submission.csv),没有该文件则无法提交。
版权归原作者 无鱼- 所有, 如有侵权,请联系我们删除。