
文章目录
jTrans: Jump-Aware Transformer for Binary Code Similarity Detection
core:将控制流信息嵌入到transformer的解决方案
background
Binary code similarity detection(BCSD)可以识别两个二进制代码片段之间的相似程度,这有着广泛的应用,包括已知的漏洞发现,恶意软件检测和聚类,软件剽窃检测,补丁分析,以及软件供应链分析。(应用与价值)
在机器学习应用到该领域之前,传统的bcsd严重依赖于手工提取的cfg特征,它可以捕获句法知识,如bindiff采用图同构技术来计算两个函数的cfg之间的相似性,但这种相似性可能会根据编译器的优化而改变,而注入bingo等方案通过计算cfg片段的相似性来实现对cfg变化的更大稳健性。这些手工特征很难捕捉到二进制代码的精确语义,因此仅具备较低的准确性。
而机器学习的最先进方案是SOTA,一般来讲,这些解决方案是将目标二进制代码嵌入到向量中,并计算函数在向量空间的相似度。
一些解决方案使用nlp的语言模型来模拟汇编语言,如asm2vec等,而另一些解决方案则使用gn来学习cfg的表示方法并计算其相似性。也存在同时结合两种方法的方案,使用nlp学习基本快的表示,并通过gnn来处理cfg中的基本快特征。尽管性能有所提升,但现有的方法有几个局限性。
- 基于nlp的汇编语言建模只考虑了指令顺序徐和它们之间的关系,有关程序实际执行的控制流信息没有被考虑,因此仅依靠nlp的方法将缺乏对分析的二进制文件的语义理解,而且也不能很好的适应代码中可能出现的重大变化,这些变化是编译器所带来的结果。
- 仅依靠cfg会错过每个基本块中指令的语义,使用gnn来处理cfg只能捕获结构信息,一般来讲,gnn相对难以训练和并行使用。
- 现有解决方案所使用的数据集不够大不够多样化,缺乏一个共同的大型基准。
jTrans,一个基于transformer的新型模型,旨在解决上述问题,并支持现实世界的二进制相似性检测。将捕获指令于一的nlp模型和控制流信息的cfg结合起来,推断二进制代码的表示。将控制流信息融合到transformer架构中。
Problem definition
问题的正式定义,bcsd是一个计算二元函数相似度的基本任务,可用于以下3种情况:
- 一对一,返回一个源函数与目标函数的相似度分数
- 一对多,返回目标函数与函数池中所有函数的相似度分数
- 多对多,根据相似度将函数池分为若干组
研究重点在一对多情况。
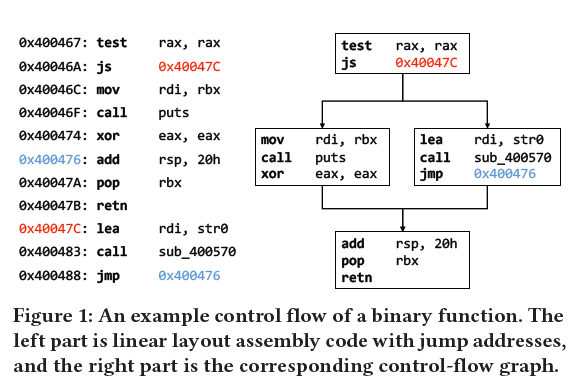
下图所示了一个二进制函数的例子,左边是线性的汇编指令,右边是cfg控制流图;
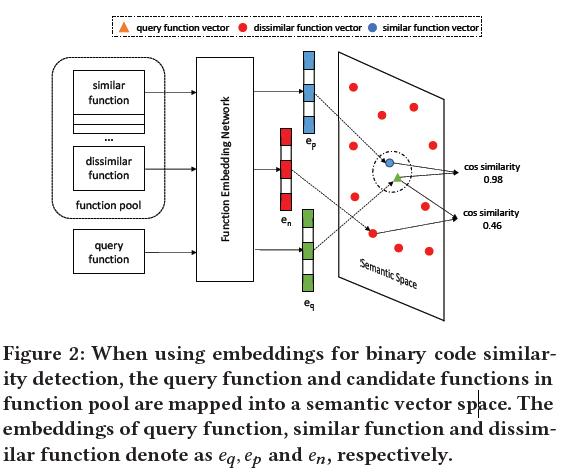
二进制相似性判断的大致流程如下:
overview
jtrans基于transformer-encoder架构,包括几个重要的变化,旨在对二进制分析这一挑战性的领域更加有效。
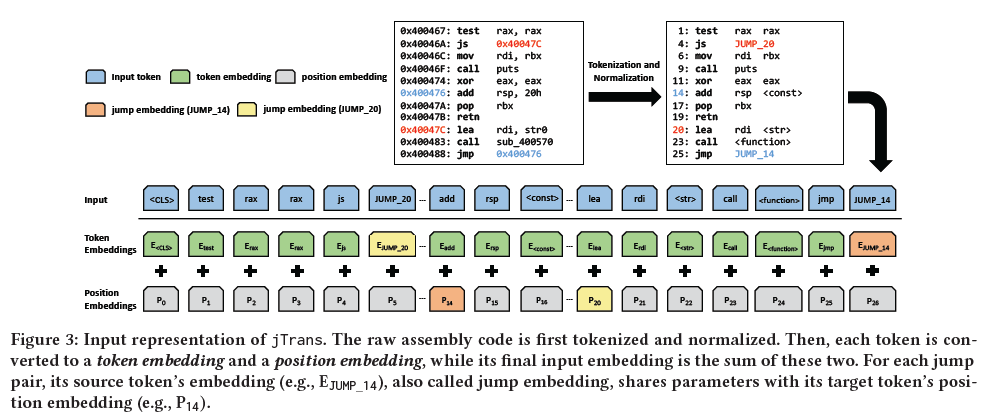
- 对汇编指令进行预处理,使其包含程序的跳转关系,即控制流信息。修改transformer的单个输入标记的嵌入,使跳转的起点和终点位置在语义上相似
- Masked language model(MLM)要求根据邻居的内容来预测屏蔽的标记内容,从而迫使模型对指令之间的关系形成上下文理解。增加辅助训练任务,要求模型理解跳转指令的目标。
应用BERT存在以下两个难点:
- 词汇外的token,jtrans只能在固定词汇表上进行训练,不包括在词汇表中的token需要以一种能够使转换器有效处理的方式进行表示。
- 对jump指令进行建模,在预处理后,源token与目标token之间的有效信息所剩极少,bert很难推断它们之间的关联关系,这使得上下文推断更加困难。
Preprocessing
为了减轻oov问题,使用ida pro产生汇编指令序列,然后应用以下表计划策略来规范和减少词汇量:
- 使用操作码和操作数作为token
- 使用代替字符串
- 使用代替常量值
- 外部函数调用保留,内部函数调用代替为
- 对于每个跳转对,使用jump_XXX替换源标记
Modeling Jump Instruction
引入位置编码使模型确定标记之间的距离,并且修改位置编码机制以反映跳跃指令的效果,通过参数贡献使他们具有很强的上下文联系(即使不像两个连续的标记那样接近)
只关注直接跳转指令,间接跳转识别是一个公开挑战,无法处理。
框架如下所示:
微调
为了使相同的函数对距离最小,使不相同的函数对距离最大,通过对比学习的目标函数微调训练。
dataset
创建了一个超大型数据集
evaluation
compare model
Genius[21]。该基线是一种非深度学习方法。Genius以归属控制流图的形式提取原始特征,并使用位置敏感散列(LSH)来生成用于漏洞搜索的数字向量。我们根据其官方代码2实现了这个基线。
Gemini [59]. 这个基线为每个基本块提取手工制作的特征,并使用GNN来学习被分析函数的CFG表示。我们根据其官方Tensorflow代码3实现了这一方法,并在整个评估过程中使用其默认参数设置。
SAFE[43]。这个基线采用了一个带有注意力机制的RNN架构来生成分析函数的表示,它接收汇编指令作为输入。我们根据其官方的Pytorch代码4和默认的参数设置来实现这一基线。
Asm2Vec[14]。该方法使用CFG上的随机行走来采样指令序列,然后使用PV-DM模型来共同学习函数和指令标记的嵌入。这种方法不是开源的,因此我们使用了一个非官方的实现5。我们使用了它的默认参数设置。
GraphEmb[44]。这个基线使用word2vec[45]来学习指令标记的嵌入。接下来,它使用RNN为每个基本块生成独立的嵌入,最后使用structure2vec[7]来结合嵌入并生成分析函数的表示。为了使这个基线可以扩展到像BinaryCorp-26M这样大的数据集,我们使用Pytorch重新实现了作者的原始Tensorflow源代码6。
OrderMatters[62]。这种方法结合了两种类型的嵌入。第一种嵌入类型使用BERT为每个基本块创建一个嵌入,然后使用GNN将所有这些嵌入结合起来,生成最终的表示。第二种类型的嵌入是通过在CFG上应用CNN获得的。然后,这两种嵌入被串联起来。这种方法不是开源的,其在线黑盒API7不能满足本研究的需要。我们使用报告中的超参数自行实现。
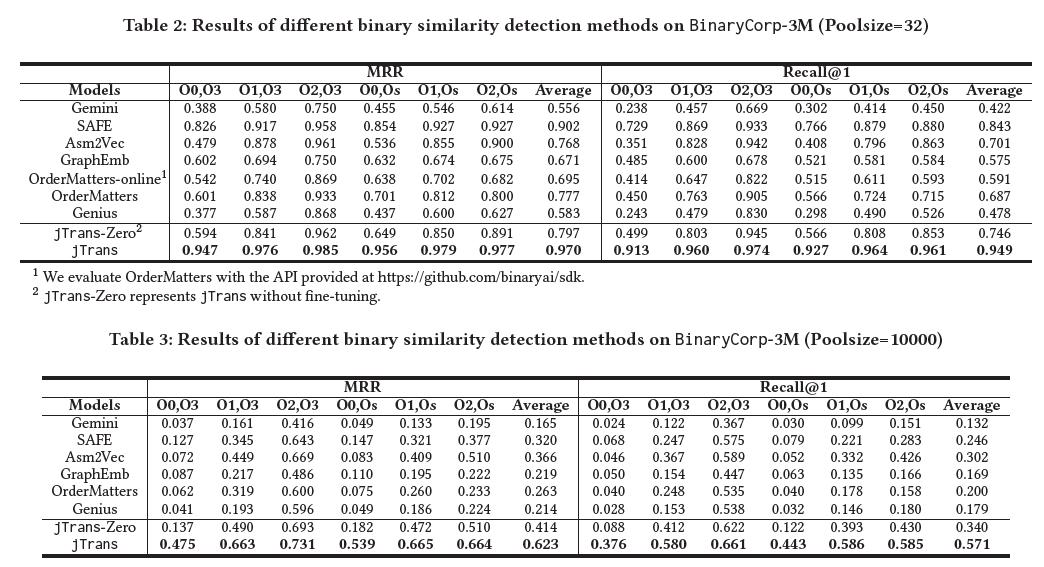
Performance
版权归原作者 西杭 所有, 如有侵权,请联系我们删除。