
LLM幻觉问题至今没有根治方案。RAG能缓解一部分,但成本高、架构复杂,而且只适用于有外部知识源的场景。而对于模型"应该知道但经常搞错"的那类问题,比如历史事件的时间线、人物履历的细节,RAG帮不上什么忙。
Chain-of-Verification(CoVe)的思路是既然模型会在生成时犯错,那就让它生成完之后再检查一遍自己的输出,把能发现的错误纠正掉,然后再给用户看。
听起来像是废话?关键在于"怎么检查"。
直接让模型审视自己刚写的东西,它大概率会坚持原有立场,这是确认偏差在作祟。CoVe的核心贡献是发现了一个绕过这个陷阱的方法:验证时必须把原始输出藏起来,让模型在"失忆"状态下重新回答事实性问题,然后用这些独立验证的答案去校对初稿。
某种意义上,这是给LLM装上了"系统2"思维:快思考先出初稿,慢思考再做验证。
工作流程:起草、规划、验证、修复
CoVe不是什么新的模型架构,它是一种提示编排模式,它把生成过程拆成四步:先让模型写初稿(这时候幻觉随便来),然后让它针对自己的初稿生成一组事实核查问题,接着独立回答这些问题,最后用验证过的事实重写原文。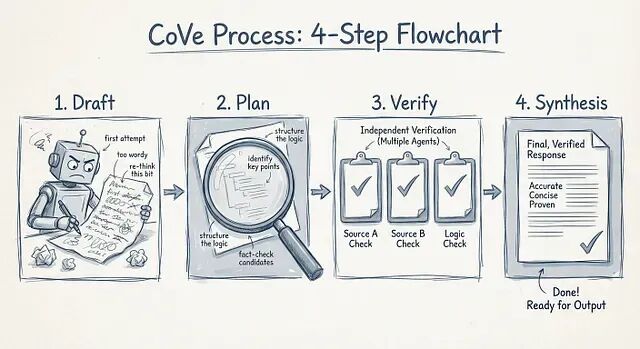
Factored:真正的关键
前面说的四步里,第一、二、四步都是常规提示工程,用思维链就能搞定,而第三步才是核心。
让LLM一边看着自己写的东西一边验证,会有一个问题,这个在学术上管这叫"sycophancy",也就是说模型会顺着自己的话往下说。草稿就在上下文窗口里摆着,概率分布会被带偏,模型倾向于认同自己刚编出来的东西。
所以最简单的解决办法是把上下文剥掉。
CoVe论文里发现,回答验证问题时必须把原始草稿藏起来。举个例子:如果你问"根据这个草稿,X是不是在1998年发生的?"模型八成会点头同意自己。但如果你只问"X是什么时候发生的?"它就得老老实实从训练权重里检索答案,没有偏差可言。
隔离验证问题就是逼模型去查自己的知识库,而不是复读自己刚说过的话。
代码实现
下面是CoVe流程的Python实现,封装成一个类。注意第三步里的CRITICAL注释,那就是Factored验证的精髓。
classChainOfVerification:
def__init__(self, llm):
self.llm=llm
defrun(self, query):
# Step 1: Baseline Generation
# Let the model hallucinate freely here.
draft_prompt=f"Question: {query}\nAnswer:"
draft=self.llm.generate(draft_prompt)
print(f"--- DRAFT ---\n{draft}\n")
# Step 2: Plan Verifications
# Ask the model to identify what needs checking.
plan_prompt=f"""
Context: {query}
Draft: {draft}
Task: Create a list of 3-5 verification questions to check the facts
in the draft. Output ONLY the questions.
"""
plan_text=self.llm.generate(plan_prompt)
questions=self.parse_questions(plan_text)
print(f"--- QUESTIONS ---\n{questions}\n")
# Step 3: Factored Verification (The Key Step)
verification_results= []
forqinquestions:
# CRITICAL: Do NOT include 'draft' in this prompt context.
# We want the raw model weights to answer this, uninfluenced by the previous lie.
verify_prompt=f"Question: {q}\nAnswer:"
# Low temperature is crucial here for factual retrieval
answer=self.llm.generate(verify_prompt, temperature=0)
verification_results.append((q, answer))
# Step 4: Final Synthesis
# Now we bring it all together.
verification_context=self.format_pairs(verification_results)
synthesis_prompt=f"""
Original Query: {query}
Draft Response: {draft}
Verification Data:
{verification_context}
Task: Rewrite the Draft Response to be fully accurate.
Remove any details contradicted by the Verification Data.
"""
final_response=self.llm.generate(synthesis_prompt)
returnfinal_response
defparse_questions(self, text):
return [line.strip() forlineintext.split('\n') if'?'inline]
defformat_pairs(self, pairs):
return"\n".join([f"Q: {q}\nA: {a}"forq, ainpairs])
CoVe和RAG该怎么选?
每次聊到CoVe,总有人问:为什么不直接用RAG?
两者解决的是不同问题。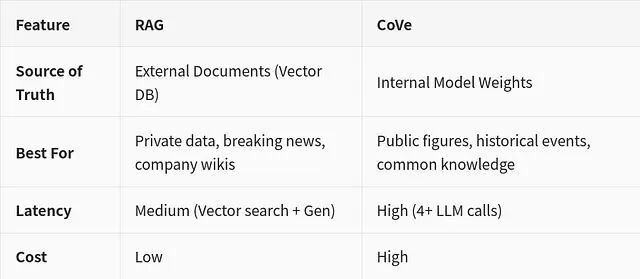
RAG适用于模型根本不可能知道答案的场景,比如你公司Q3的销售数据。CoVe适用于模型理论上应该知道、但可能搞混或偷懒的场景,比如按时间顺序列出纽约市历任市长。
而且研究表明两者可以混用:先用CoVe验证RAG检索回来的文档是否真的相关,再决定要不要用。代价是成本翻倍,但在医疗、法律这种高风险场景下,还是可行的。
从Vibe Coding到系统2代理
关注2026年初Agentic爆发的人,大概都听过"Ralph Wiggum"技术这个梗。
名字来自《辛普森一家》里那个喊着"我在帮忙!"却啥也没干成的角色。这技术的核心就是把LLM塞进一个while循环,让它反复尝试直到单元测试通过。暴力验证,Token消耗会爆表但最后确实能撞出正确答案。虽然听起来很好笑,实际上还挺管用。
工具增强版CoVe
opencode、OpenDevin、Windsurf这些现代自主代理已经在用"工具增强"版本的CoVe了。
它们不再只是问自己"这代码对不对",而是直接动手:先写代码,然后在沙盒里跑npm test或linter,读stderr输出,根据真实报错来修。
这就把CoVe的验证环节从概率猜测变成了确定性判断。
2026年的新拓扑:分支验证
最前沿的做法已经不是简单的线性循环了。是分支。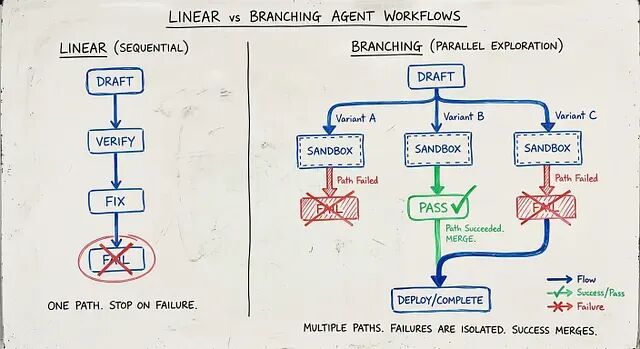
分支拓扑下,代理不是失败了就重试一次。它会同时提出三个修复方案,在三个隔离容器里并行跑,哪个能让构建变绿就提交哪个。
验证的消耗
这是2026年工程实践必须面对问题
Vibe Coding走系统1路线:快、便宜、但有20%左右的幻觉率,做原型够用。系统2代理反过来:慢、Token成本翻10倍、但可靠性过硬,生产环境离不开。
也就是说是拿计算资源换安心,当业务从聊天机器人升级到自主工程师,这笔成本不是能不能接受的问题,而是必须付的保险费——除非你想承担"Ralph Wiggum式"的风险,比如AI自己把数据库删了。
总结
CoVe的代价很明确:延迟。
生成初稿、生成问题、并行验证、综合重写,整套流程跑下来,Token消耗和响应时间基本翻四倍。对于实时聊天场景,这个延迟可能难以接受。但换个角度看,异步报告生成、代码审查、自动邮件起草这类任务,多等几秒换来输出可信度的大幅提升,这笔账怎么算都划算。
更值得关注的是CoVe带来的转变:过去几年,行业把大量精力投入到"如何让模型生成得更好"上——更大的参数、更多的数据、更精细的对齐。CoVe指向了另一个方向:与其追求一次生成就完美,不如承认模型会犯错,然后在架构层面把纠错机制build进去。
这和软件工程的演进路径很像。早期写代码追求一次写对,后来发现测试驱动开发、持续集成、灰度发布这些"验证优先"的实践才是规模化的正确姿势。
CoVe不会是终点,我们未来大概率会看到更多CoVe与RAG、外部工具、多模型交叉验证的组合方案。
作者:Digvijay Mahapatra