
一、NLP简介
在这个大数据时代,几乎所有事物都能用数据描述。数据可以大致分为三类。
第一类是用于传播的媒体数据,如图片、音频、视频等。这类数据一般不需要做处理,只需要存储和读取。
第二类是数字类数据,其价值很高。因为数字是有一定规律的,从已有数字中发现的规律可以用于预测未来的数据。这也是传统大数据处理与分析的主要方面。
第三类是自然语言数据。这类数据更贴近生活,对其进行统计和分析,可以让机器理解人的语言,实现机器与人的交流。就像智能手机中的语音助手一样,它们能听懂我们说的话,执行我们需要的操作,甚至能和我们进行简单的交流。因此,NLP是目前大数据处理和分析的新兴领域。
1、NLP的应用领域
NLP在实现人工智能的目标上划分为很多领域,在不同的领域中所起的作用也不同。下面简单了解一下NLP的7个主要应用领域。
(1)情感分析
可将情感分析简单理解为通过某人的言论分析出其对某个事物的观点或看法的倾向,多用于分析用户反馈(如电子商务网站的用户购物评价)来帮助企业进行决策。
(2)智能问答
智能问答常见的应用场景是客服机器人和智能语音助手。初级应用是根据用户提出的问题进行浅层的情感分析和关键词提取,然后返回指定的回复语句;中级应用是聊天功能;高级应用是还处于研究阶段的强人工智能,即能够真正推理和解决问题的智能机器。
(3)文摘生成
文摘生成是指利用计算机从原始文档中提取文摘,以全面地反映文档的核心思想,最终目标是将人类从繁杂的文本处理工作中解放出来。
(4)文本分类
在网络中充斥着大量的垃圾信息,文本分类可以过滤掉这部分垃圾信息。常见的应用场景是垃圾邮件和垃圾短信的识别和过滤。
(5)舆论分析
舆论分析主要用于社交媒体的舆论防控,如谣言监测和跟踪、立场分类和验证。
(6)知识图谱
人工智能在感知层方面进步很快,能感知到各种信息,但是在认知层上还有很大不足。机器可以感知到0℃,可以感知到水和冰,而知识图谱的作用就是将这三者串联起来,形成一个知识:水在0℃时会变成冰。可以将知识图谱理解为一个数据库,用户输入一个查询语句,知识图谱就会在库中查找与分析,判断用户想要的结果,再从库中取出来返回给用户。
(7)机器翻译
机器翻译能将一种语言的语句结合上下文等因素翻译成相同语义的其他语言的语句。相对于人工翻译来说,机器翻译在效率上有很大优势,在日常的网站翻译和普通文本翻译上有着不错的表现。但是机器翻译目前还做不到和人类一致的情感分析,因而在影视和文化行业的翻译及长文本翻译上还不能取代人工翻译。
2、NLP的基本流程
NLP的基本流程大致有两步:
第一步是自然语言理解(Nature Language Understanding,简称NLU),就是理解给定文本的含义或意图。
第二步是自然语言生成(Nature Language Generation,简称NLG),一般的NLG会按照一定的模板将数据返回给用户,而智能化的NLG则能将关键的信息要素使用各种合适的字符连接起来,形成用户能轻松阅读和理解的叙述语句返回给用户。
二、文本分词方法
文本分词能将文本拆分成最小粒度的单词,对NLU有着极大的作用。我们接触到的文本分词主要是英文分词和中文分词。英文文本的单词之间有空格作为界线,分词难度很小;而中文文本的词之间除了标点符号之外不存在明确的界线,分词难度较大。分词的效果直接影响对文本语义的理解,因此,选择一个成熟的分词算法就显得尤为重要。
实现中文分词的方法主要有以下3种。
1、基于词典的分词方法
基于词典的分词方法是指按照一定的策略从待分词文本中取出一个字符串与一个词典进行匹配,如果该字符串能在词典中找到,说明匹配成功,则将该字符串作为一个词切分出来。这种方法要求使用的词典包含的词条要足够多,这个词典也叫统计词典。
统计词典从词文本、词频和词性三个方面来描述一个词:词文本是词本身;词频是当前词文本重复出现的概率统计;词性描述了一个词的性质,中文分词词性对照表(中科院标准)见下表。
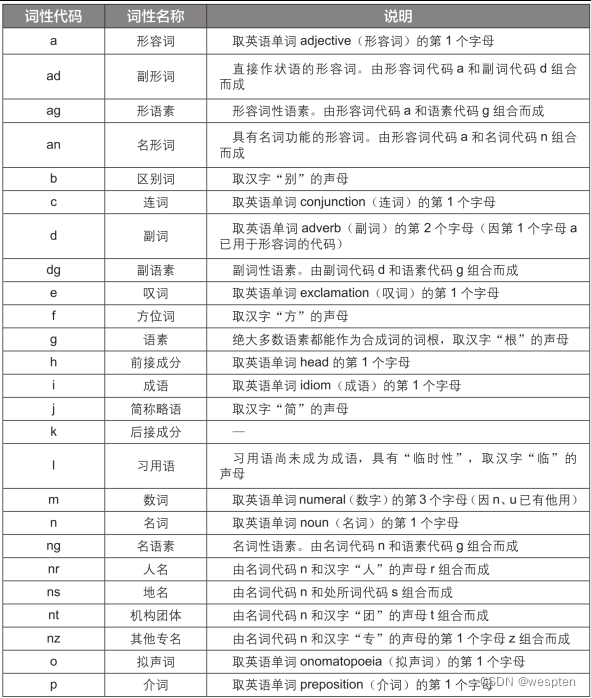
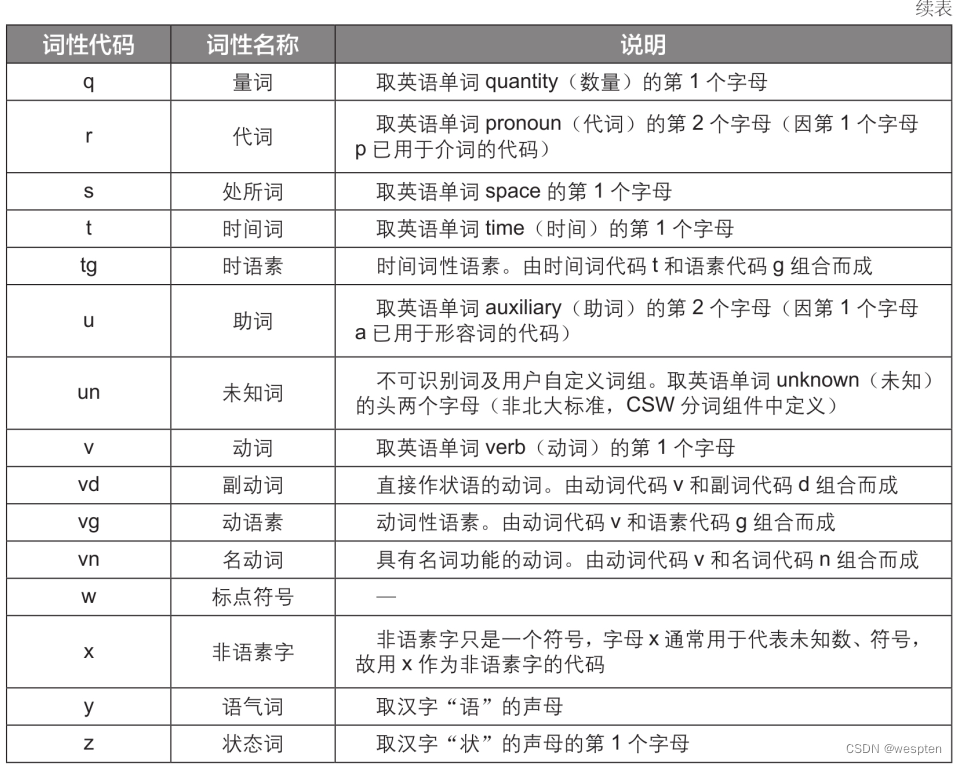
基于词典的分词方法又大致分为以下4种。
(1)正向最大匹配法
假设词典中最长词条的长度为m,按照从左向右的顺序从待分词文本中取出长度为m的字符串,与正序词典做匹配。如果在正序词典中能匹配到该字符串,则将该字符串从文本中切分出来,作为一个词;如果在正序词典中不能匹配到该字符串,就去掉该字符串的最后一个字符后再做匹配,直到匹配成功。
(2)逆向最大匹配法
逆向最大匹配法的基本原理与正向最大匹配法的基本原理基本相同,只不过它是按照从右向左的顺序从待分词文本中取出字符串,与逆序词典做匹配。如果匹配不成功,则去掉字符串的第一个字符后再做匹配,直到匹配成功。
(3)双向最大匹配法
双向最大匹配法同时做正向和逆向最大匹配,如果两者产生的结果不同,则使用进一步的技术来消除不同。
(4)最少切分法
最少切分法是指同时采用多种算法进行分词,然后比较分词结果,哪种方法的分词结果最少,就以哪种方法的结果作为最终结果。
2、基于统计的机器学习方法
在文本中,相邻的字一起出现的概率越高,说明这对字就越可能是一个词。通过大量的文本来训练一个机器学习模型,模型在训练过程中会记录在分词时遇到歧义的情况,随着模型被训练得越来越成熟,切分出的词会越来越精确,还可以对新词进行准确分词。
与基于词典的分词方法相比,这种方法的优点是不需要建立庞大的词典,还可以处理新词和有歧义的分词;缺点是需要大量文本和时间进行模型训练,而且不如基于词典的分词方法方便快捷和易于实现。
3、基于理解的分词方法
在分词过程中会遇到很多有歧义的词,例如,“大学生理发”应切分为“大学/生理/发”还是“大学生/理发”呢?基于理解的分词方法就是为了解决这一问题而设计的。消除歧义的常见方法有通过记录词语语义和上下文的语义词典来消除歧义;还有通过词义标注语料库训练一个消除歧义的模型,再使用训练成熟的模型来消除歧义。只要正确理解词语的语义,就能实现基于理解的分词。
三、jieba分词器
实际应用中,我们通常不需要自己建立词典和根据算法来编写分词程序,因为有许多现成的分词器可以使用。
1、jieba分词器简介
jieba分词器提供4种分词模式,并且支持简体/繁体分词、自定义词典、关键词提取、词性标注。下面简单介绍一下jieba分词器的基础知识。
1. 安装方法
jieba分词器支持多种编程语言,其Python模块兼容Python 2和Python 3版本,安装命令为“pip install jieba”。jieba模块安装包的体积较大,建议通过国内的镜像服务器安装。
2. 分词模式说明
jieba分词器支持4种分词模式:
(1)精确模式
该模式会试图将句子最精确地切分开,适合在文本分析时使用。
(2)全模式
该模式会将句子中所有可以成词的词语都扫描出来,速度也非常快,缺点是不能解决歧义问题,有歧义的词语也会被扫描出来。
(3)搜索引擎模式
该模式会在精确模式的基础上对长词语再进行切分,将更短的词切分出来。在搜索引擎中,要求输入词语的一部分也能检索到整个词语相关的文档,所以该模式适用于搜索引擎分词。
(4)Paddle模式
该模式利用PaddlePaddle深度学习框架,训练序列标注网络模型实现分词,同时支持词性标注。该模式在4.0及以上版本的jieba分词器中才能使用。使用该模式需要安装PaddlePaddle模块,安装命令为“pip install paddlepaddle”。
2、jieba分词器使用
代码文件:jieba分词器的基本用法.py
下面来讲解jieba分词器的基本用法,包括在不同模式下分词、标注词性、识别新词等。
1. 精确模式、全模式和Paddle模式分词
在Python中,主要使用jieba模块中的cut()函数进行分词,该函数返回的结果是一个迭代器。cut()函数有4个参数:第1个参数为待分词文本;参数cut_all用于设置使用全模式还是精确模式进行分词;参数use_paddle用于控制是否使用Paddle模式进行分词;参数HMM用于控制是否使用HMM模型识别新词。这里先讲解如何在精确模式、全模式和Paddle模式下分词。
将参数cut_all设置为True时,表示使用全模式进行分词。
演示代码如下:
1 import jieba
2 str1 = '我来到了西北皇家理工学院,发现这儿真不错'
3 seg_list = jieba.cut(str1, cut_all=True) # 使用全模式进行分词
4 print('全模式分词结果:', '/'.join(seg_list)) # 将分词结果拼接成字符串并输出
代码运行结果如下:
1 全模式分词结果:我/来到/了/西北/皇家/理工/理工学/理工学院/工学/工学院/学院/,/发现/这儿/真不/真不错/不错
将参数cut_all设置为False时,表示使用精确模式进行分词。
演示代码如下:
1 import jieba
2 str1 = '我来到了西北皇家理工学院,发现这儿真不错'
3 seg_list = jieba.cut(str1, cut_all=False) # 使用精确模式进行分词
4 print('精确模式分词结果:', '/'.join(seg_list))
参数cut_all的默认值是False,所以第3行代码也可改写为“seg_list = jieba.cut(str1)”。
代码运行结果如下:
1 精确模式分词结果:我/来到/了/西北/皇家/理工学院/,/发现/这儿/真不错
参数use_paddle设置为True和False时分别表示使用和不使用Paddle模式进行分词。但在调用cut()函数之前,需先调用enable_paddle()函数来启用Paddle模式。
演示代码如下:
1 import jieba
2 str1 = '我来到了西北皇家理工学院,发现这儿真不错'
3 jieba.enable_paddle() # 启用Paddle模式
4 seg_list = jieba.cut(str1, use_paddle=True) # 使用Paddle模式进行分词
5 print('Paddle模式分词结果:', '/'.join(seg_list))
代码运行结果如下:
1 Paddle模式分词结果:我/来到/了/西北皇家理工学院/,/发现/这儿/真不错
2. 词性标注
使用Paddle模式进行分词时还可以为切分出的词标注词性。
演示代码如下:
1 import jieba
2 import jieba.posseg as pseg
3 jieba.enable_paddle() # 启用Paddle模式
4 str2 = '上海自来水来自海上'
5 seg_list = pseg.cut(str2, use_paddle=True) # 使用posseg进行分词
6 for seg, flag in seg_list:
7 print(seg, flag)
代码运行结果如下:
1 上海 LOC
2 自来水 n
3 来自 v
4 海上 s
可以看到,分词结果的每个词语后都有一个词性代码。其中的LOC在词性对照表中没有出现,因为Paddle模式使用的是自有的词性对照表,具体见下表。
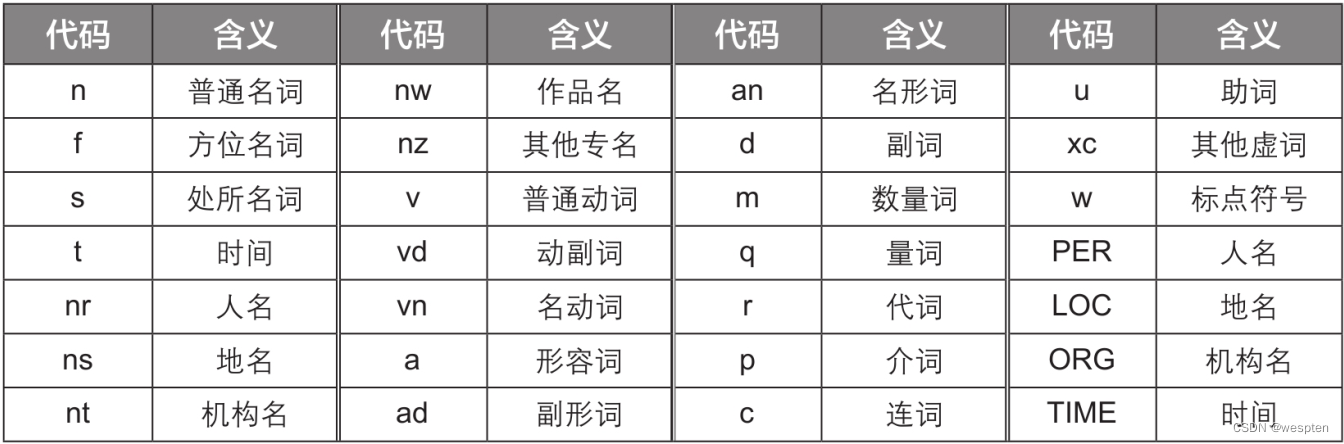
其中词性代码24个(小写字母),专名类别代码4个(大写字母)。
3. 识别新词
将cut()函数的参数HMM设置为True,即可使用基于汉字成词能力的HMM模型识别新词,即词典中不存在的词。假设待分词文本为“他知科技研发有限公司是一家互联网行业的公司”,其中有一个可能为新词的词语“他知”,为了验证新词识别效果,需要先查看jieba分词器的词典中是否存在这个词。
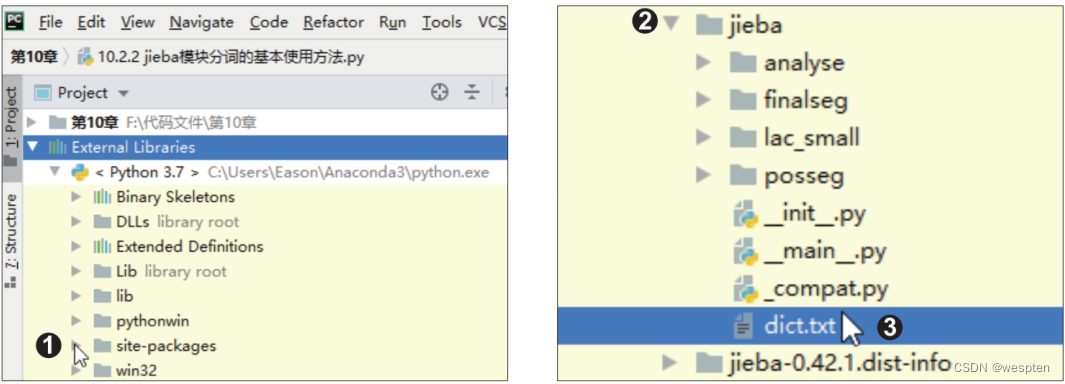
在PyCharm中找到pip命令安装模块的位置,也就是“site-packages”文件夹。
单击该文件夹左侧的折叠按钮将其展开,如下左图所示。在该文件夹下找到“jieba”文件夹,单击左侧的折叠按钮将其展开,可以看到一个“dict.txt”文件,它就是jieba分词器的词典,如下右图所示。
双击“dict.
txt”文件将其打开,按快捷键【Ctrl+F】打开搜索框,输入“他知”,可看到搜索结果为“0 results”,如下图所示,说明词典中没有这个词。
下面使用精确模式进行分词,并启用HMM模型识别新词。演示代码如下:
1 import jieba
2 str3 = '他知科技研发有限公司是一家互联网行业的公司'
3 seg_list = jieba.cut(str3, HMM=True) # 参数HMM的默认值是True,可以省略
4 print('精确模式分词结果:', '/'.join(seg_list))
代码运行结果如下。可以看到jieba分词器通过上下文判定“他知”是一个词并将其切分出来,说明新词识别成功。
1 精确模式分词结果:他知/科技/研发/有限公司/是/一家/互联网/行业/的/公司
4. 搜索引擎模式分词
如果要以搜索引擎模式进行分词,则要使用cut_for_search()函数。该函数只有两个参数:第1个参数为待分词文本;第2个参数为HMM,其含义与cut()函数的参数HMM相同。
使用cut_for_search()函数进行搜索引擎模式分词的演示代码如下:
1 import jieba
2 str1 = '我来到了西北皇家理工学院,发现这儿真不错'
3 seg_list = jieba.cut_for_search(str1)
4 print('搜索引擎模式分词结果:', '/'.join(seg_list))
代码运行结果如下:
1 搜索引擎模式分词结果:我/来到/了/西北/皇家/理工/工学/学院/理工学/工学院/理工学院/,/发现/这儿/真不/不错/真不错
3、调整词典
代码文件:调整词典.py、用户词典.txt
jieba分词器自带的词典内容已经非常丰富,但仍然不可能满足所有用户的需求,因此,jieba分词器还允许用户根据自己的需求调整词典,以提高分词的正确率。
1. 使用自定义词典
用户可以创建一个自定义词典,将jieba分词器的词典里没有的词添加进去,再在程序中加载自定义词典用于分词。
先不使用自定义词典,对一段文本以精确模式进行分词。
演示代码如下:
1 import jieba
2 seg_list = jieba.cut('心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
3 print('未加载自定义词典时的精确模式分词结果:\n', '/'.join(seg_list))
代码运行结果如下:
1 未加载自定义词典时的精确模式分词结果:
2 心灵感应/般地/蓦然回首/,/才能/撞见/那一/低头/的/温柔/;/也/最/是/那/一/低头/的/温柔/,/似/一朵/水/莲花/不胜/凉风/的/娇羞/;/也/最/是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
现在我们希望让“水莲花”作为一个名词被切出,让“一低头”作为一个形容词被切出。创建一个“用户词典.txt”文件,在文件中输入自定义的词。一个词占一行,每一行分词语、词频(可省略)、词性(可省略)三部分,用空格隔开,顺序不可颠倒,如下图所示。

随后就可以在代码中使用load_userdict()函数载入自定义词典进行分词。
演示代码如下:
1 import jieba
2 jieba.load_userdict('用户词典.txt') # 加载自定义词典
3 seg_list = jieba.cut('心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
4 print('加载自定义词典时的精确模式分词结果:\n', '/'.join(seg_list))
代码运行结果如下,可以看到将这段话按照自定义词典中的词进行了切分。
1 加载自定义词典时的精确模式分词结果:
2 心灵感应/般地/蓦然回首/,/才能/撞见/那/一低头/的/温柔/;/也/最/是/那/一低头/的/温柔/,/似/一朵/水莲花/不胜/凉风/的/娇羞/;/也/最/是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
**2. 动态修改词典 **
使用add_word()函数和del_word()函数可在程序中动态修改词典。需要注意的是,这两个函数对词典的修改只在当前程序的运行过程中生效。
(1)动态添加词
add_word()函数用于在词典中动态添加一个词。在加载前面创建的自定义词典的基础上,在程序运行过程中动态添加自定义的词“最是”。演示代码如下:
1 import jieba
2 jieba.load_userdict('用户词典.txt')
3 jieba.add_word('最是') # 添加词
4 seg_list = jieba.cut('心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
5 print('添加自定义词时的精确模式分词结果:\n', '/'.join(seg_list))
代码运行结果如下,可以看到除了自定义词典中的词,“最是”也作为一个词被切分出来。
1 添加自定义词时的精确模式分词结果:
2 心灵感应/般地/蓦然回首/,/才能/撞见/那/一低头/的/温柔/;/也/最是/那/一低头/的/温柔/,/似/一朵/水莲花/不胜/凉风/的/娇羞/;/也/最是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
(2)动态删除词
del_word()函数用于在词典中动态删除一个词。在加载前面创建的自定义词典的基础上,在程序运行过程中动态删除自定义的词“一低头”。
演示代码如下:
1 import jieba
2 jieba.load_userdict('用户词典.txt')
3 jieba.del_word('一低头') # 删除词
4 seg_list = jieba.cut('心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
5 print('删除自定义词时的精确模式分词结果:\n', '/'.join(seg_list))
代码运行结果如下,可以看到“一低头”因为被从词典中删除而没有被切分出来。此外,前面介绍add_word()函数时在代码中动态添加的“最是”也没有被切分出来,说明对词典的动态修改只在当前程序的运行过程中生效。
1 删除自定义词时的精确模式分词结果:
2 心灵感应/般地/蓦然回首/,/才能/撞见/那一/低头/的/温柔/;/也/最/是/那/一/低头/的/温柔/,/似/一朵/水莲花/不胜/凉风/的/娇羞/;/也/最/是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
3. 调节词频
要调整分词结果,除了使用自定义词典和动态修改词典,还可以调节词频。词频越大的词,被切分出来的概率就越大。使用suggest_freq()函数可以调节单个词的词频,使其能或不能被切分出来。
先来看看不修改词频时的分词效果。
演示代码如下:
1 import jieba
2 str3 = '他认为未来几年健康产业在GDP中将占比第一。'
3 seg_list = jieba.cut(str3)
4 print('精确模式分词结果:\n', '/'.join(seg_list))
代码运行结果如下,可以看到“中将占比”被切分为“中将/占/比”,这是不正确的。
1 精确模式分词结果:
2 他/认为/未来/几年/健康/产业/在/GDP/中将/占/比/第一/。
此时就可以使用suggest_freq()函数修改词频,以获得正确的分词结果。演示代码如下:
1 import jieba
2 str3 = '他认为未来几年健康产业在GDP中将占比第一。'
3 jieba.suggest_freq(('中', '将'), True) # 修改词频,强制让“中将”作为两个词被切分出来
4 jieba.suggest_freq('占比', True) # 修改词频,强制让“占比”作为一个词被切分出来
5 seg_list = jieba.cut(str3, HMM=False) # HMM模型的新词识别功能可能会让词频调节失效,因此将其关闭
6 print('精确模式分词结果:\n', '/'.join(seg_list))
代码运行结果如下,可以看到修改词频后,获得了正确的分词结果。
1 精确模式分词结果:
2 他/认为/未来/几年/健康/产业/在/GDP/中/将/占比/第一/。
4、关键词提取
代码文件:关键词提取.py
简单来说,关键词是最能反映文本的主题和意义的词语。关键词提取就是从指定文本中提取出与该文本的主旨最相关的词,它可以应用于文档的检索、分类和摘要自动编写等。例如,从新闻中提取出关键词,就能大致判断新闻的主要内容。
从文本中提取关键词的方法主要有两种:第一种是有监督的学习算法,这种方法将关键词的提取视为一个二分类问题,先提取出可能是关键词的候选词,再对候选词进行判定,判定结果只有“是关键词”和“不是关键词”两种,基于这一原理设计一个关键词归类器的算法模型,不断地用文本训练该模型,使模型更加成熟,直到模型能准确地对新文本提取关键词;第二种是无监督的学习算法,这种方法是对候选词进行打分,取出打分最高的候选词作为关键词,常见的打分算法有TF-IDF和TextRank。jieba模块提供了使用TF-IDF和TextRank算法提取关键词的函数,下面就来学习具体的编程方法。
1. 基于TF-IDF算法的关键词提取
extract_tags()函数能基于TF-IDF算法提取关键词,其语法格式如下:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
参数sentence为待提取关键词的文本;参数topK用于指定需返回的关键词个数,默认值为20;参数withWeight用于指定是否同时返回权重,默认值为False,表示不返回权重,TF或IDF权重越高,返回的优先级越高;参数allowPOS用于指定返回的关键词的词性,以对返回的关键词进行筛选,默认值为空,表示不进行筛选。
基于TF-IDF算法的关键词提取的演示代码如下:
1 from jieba import analyse # 导入关键词提取接口
2 text = '记者日前从中国科学院南京地质古生物研究所获悉,该所早期生命研究团队与美国学者合作,在中国湖北三峡地区的石板滩生物群中,发现了4种形似树叶的远古生物。这些“树叶”实际上是形态奇特的早期动物,它们生活在远古海洋底部。相关研究成果已发表在古生物学国际专业期刊《古生物学杂志》上。'
3 keywords = analyse.extract_tags(text, topK=10, withWeight=True, allowPOS=('n', 'v')) # 提取10个词性为名词或动词的关键词并返回权重
4 print(keywords)
代码运行结果如下:
1 [('古生物学', 0.783184303024), ('树叶', 0.6635900468544), ('生物群', 0.43238540794400004), ('古生物', 0.38124919198039997), ('期刊', 0.36554014868720003), ('石板', 0.34699723913040004), ('形似', 0.3288202017184), ('研究成果', 0.3278758070928), ('团队', 0.2826627565264), ('获悉', 0.28072960723920004)]
2. 基于TextRank算法的关键词提取
textrank()函数能基于TextRank算法提取关键词,其语法格式如下:
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
textrank()函数和extract_tags()函数的参数基本一致,只有参数allowPOS的默认值不同。并且由于算法不同,结果可能会有差异。
基于TextRank算法的关键词提取的演示代码如下:
1 from jieba import analyse # 导入关键词提取接口
2 text = '记者日前从中国科学院南京地质古生物研究所获悉,该所早期生命研究团队与美国学者合作,在中国湖北三峡地区的石板滩生物群中,发现了4种形似树叶的远古生物。这些“树叶”实际上是形态奇特的早期动物,它们生活在远古海洋底部。相关研究成果已发表在古生物学国际专业期刊《古生物学杂志》上。'
3 keywords = analyse.textrank(text, topK=10, withWeight=True, allowPOS=('n', 'v')) # 提取10个词性为名词或动词的关键词并返回权重
4 print(keywords)
代码运行结果如下,可以看到,由于算法不同,提取关键词的结果存在差异。
1 [('古生物学', 1.0), ('树叶', 0.8797803471074045), ('形似', 0.6765568513591282), ('专业', 0.6684901270801065), ('生物', 0.648692596888148), ('发表', 0.6139083953888275), ('生物群', 0.59981945604977), ('期刊', 0.5651065025924439), ('国际', 0.5642917600351786), ('获悉', 0.5620719278559326)]
5、停用词过滤
代码文件:停用词过滤.py、stopwords.txt
简单来说,停用词是指在每个文档中都会大量出现,但是对于NLP没有太大作用的词,如“你”“我”“的”“在”及标点符号等。在分词完毕后将停用词过滤掉,有助于提高NLP的效率。
先来看看未过滤停用词的效果。
演示代码如下:
1 import jieba
2 text = '商务部4月23日发布的数据显示,一季度,全国农产品网络零售额达936.8亿元,增长31.0%;电商直播超过400万场。电商给农民带来了新的机遇。'
3 seg_list = jieba.cut(text)
4 print('未启用停用词过滤时的分词结果:\n', '/'.join(seg_list))
代码运行结果如下:
1 未启用停用词过滤时的分词结果:
2 商务部/4/月/23/日/发布/的/数据/显示/,/一季度/,/全国/农产品/网络/零售额/达/936.8/亿元/,/增长/31.0%/;/电商/直播/超过/400/万场/。/电商/给/农民/带来/了/新/的/机遇/。
为了过滤停用词,需要有一个停用词词典。理论上来说,停用词词典的内容是根据NLP的目的变化的。
我们可以自己制作停用词词典,但更有效率的做法是下载现成的停用词词典,然后根据自己的需求修改。用搜索引擎搜索“停用词词典”,选择合适的词典下载,保存到代码文件所在的文件夹。
这里提供一个停用词词典“stopwords.txt”,下面就使用这个词典来过滤停用词。
演示代码如下:
1 import jieba
2 with open('stopwords.txt', 'r+', encoding='utf-8') as fp:
3 stopwords = fp.read().split('\n') # 将停用词词典的每一行停用词作为列表的一个元素
4 word_list = [] # 用于存储过滤停用词后的分词结果
5 text = '商务部4月23日发布的数据显示,一季度,全国农产品网络零售额达936.8亿元,增长31.0%;电商直播超过400万场。电商给农民带来了新的机遇。'
6 seg_list = jieba.cut(text)
7 for seg in seg_list:
8 if seg not in stopwords:
9 word_list.append(seg)
10 print('启用停用词过滤时的分词结果:\n', '/'.join(word_list))
需要注意的是,第2行代码中要根据停用词词典的编码格式设置参数encoding的值。如果词典的编码格式是GBK,则参数encoding就要设置为'gbk'。如何判断词典的编码格式是GBK还是UTF-8呢?可以使用PyCharm打开停用词词典,如果正常显示词典内容,则是UTF-8格式;如果显示为乱码,则是GBK格式。
代码运行结果如下,可以看到,经过停用词过滤,分词结果更精练了。
1 启用停用词过滤时的分词结果:
2 商务部/4/月/23/日/发布/数据/显示/一季度/全国/农产品/网络/零售额/达/936.8/亿元/增长/31.0%/电商/直播/超过/400/万场/电商/农民/带来/新/机遇
6、词频统计
代码文件:词频统计.py
词频是NLP中一个很重要的概念,是分词和关键词提取的依据。在构造分词词典时,通常需要为每一个词设置词频。
对分词结果进行词频统计能从客观上反映一段文本的侧重点,演示代码如下:
1 import jieba
2 text = '蒸馍馍锅锅蒸馍馍,馍馍蒸了一锅锅,馍馍搁上桌桌,桌桌上面有馍馍。'
3 with open('stopwords.txt', 'r+', encoding='utf-8') as fp:
4 stopwords = fp.read().split('\n') # 加载停用词词典
5 word_dict = {} # 用于存储词频统计结果的词典
6 jieba.suggest_freq(('桌桌'), True) # 让“桌桌”作为一个词被切分出来
7 seg_list = jieba.cut(text)
8 for seg in seg_list:
9 if seg not in stopwords: # 如果分出的词不是停用词,则统计词频
10 if seg in word_dict.keys():
11 word_dict[seg] += 1 # 如果分出的词存在于词典中,说明该词已经不是第一次出现在文本中,将该词的词频增加1
12 else:
13 word_dict[seg] = 1 # 如果分出的词不存在于词典中,说明该词是第一次被切出,将其添加到词典中并设置词频为1
14 print(word_dict)
代码运行结果如下,从各个词的词频就可以大致分析出这段文本描述的是用锅蒸馍馍。
1 {'蒸': 3, '馍馍': 5, '锅锅': 1, '一锅': 1, '锅': 1, '搁': 1, '桌桌': 2, '上面': 1
四、第三方工具包Gensim
1、Gensim简介
Gensim用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
- LSI
- LDA
- HDP
- DTM
- DIM
- TF-IDF
- word2vec、paragraph2vec
2、基本概念
- 语料(Corpus):一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。
- 向量(Vector):由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
- 稀疏向量(Sparse Vector):通常,我们可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(key, value)的tuple。
- 模型(Model):是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
3、将文档集做成语料库
我们需要从文档集中获得词库:
- 分词
- 去掉没有意义的冠词
- 去低频词: 去掉只在出现过一次的单词(避免我们的语料库矩阵太稀疏了)
- 将剩下的词做成词库
根据词库处理文档集,转化为语料库:
#文档集
documents = ["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey"]
#去冠词,连接词等
stoplist = set('for a of the and to in'.split())
texts = [[word for word in document.lower().split() if word not in stoplist]
for document in documents]
#统计词频
from collections import defaultdict
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
#去掉低频词
texts = [[token for token in text if frequency[token] > 1]
for text in texts]
from pprint import pprint
pprint(texts)
#获取词库dictionary
from gensim import corpora
dictionary = corpora.Dictionary(texts)
dictionary.save('/tmp/deerwester.dict')
print(dictionary)
print(dictionary.token2id)
#将文档转为语料库corpus
corpus = [dictionary.doc2bow(text) for text in texts]
print(corpus)
4、训练语料的预处理
训练语料的预处理指的是将文档中原始的字符文本转换成Gensim模型所能理解的稀疏向量的过程。
通常,我们要处理的原生语料是一堆文档的集合,每一篇文档又是一些原生字符的集合。在交给Gensim的模型训练之前,我们需要将这些原生字符解析成Gensim能处理的稀疏向量的格式。
由于语言和应用的多样性,Gensim没有对预处理的接口做出任何强制性的限定。通常,我们需要先对原始的文本进行分词、去除停用词等操作,得到每一篇文档的特征列表。例如,在词袋模型中,文档的特征就是其包含的word:
texts = [['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
其中,corpus的每一个元素对应一篇文档。
接下来,我们可以调用Gensim提供的API建立语料特征(此处即是word)的索引字典,并将文本特征的原始表达转化成词袋模型对应的稀疏向量的表达。依然以词袋模型为例:
from gensim import corpora
dictionary = corpora.Dictionary(texts) # 综合获取所有单词,作为综合特征(语料库)
print(dictionary)
corpus = [dictionary.doc2bow(text) for text in texts] # 利用语料特征,为每一句话,建立稀疏向量(这里是bow向量)。对应特征(单词)出现的次数
print(corpus)
到这里,训练语料的预处理工作就完成了。我们得到了语料中每一篇文档对应的稀疏向量(这里是bow向量);向量的每一个元素代表了一个word在这篇文档中出现的次数。值得注意的是,虽然词袋模型是很多主题模型的基本假设,这里介绍的doc2bow函数并不是将文本转化成稀疏向量的唯一途径。在下一小节里我们将介绍更多的向量变换函数。
最后,出于内存优化的考虑,Gensim支持文档的流式处理。我们需要做的,只是将上面的列表封装成一个Python迭代器;每一次迭代都返回一个稀疏向量即可。
# 流式处理,内存优化
class MyCorpus(object):
def __iter__(self):
for line in open('mycorpus.txt'):
# 假设文档中每行是一个句子,使用空格分割
yield dictionary.doc2bow(line.lower().split(' '))
5、主题向量的变换
对文本向量的变换是Gensim的核心。通过挖掘语料中隐藏的语义结构特征,我们最终可以变换出一个简洁高效的文本向量。
在Gensim中,每一个向量变换的操作都对应着一个主题模型,例如上一小节提到的对应着词袋模型的doc2bow变换。每一个模型又都是一个标准的Python对象。下面以TF-IDF模型为例,介绍Gensim模型的一般使用方法。
首先是模型对象的初始化。通常,Gensim模型都接受一段训练语料(注意在Gensim中,语料对应着一个稀疏向量的迭代器)作为初始化的参数。显然,越复杂的模型需要配置的参数越多。
from gensim import models
tfidf = models.TfidfModel(corpus)
其中,corpus是一个返回bow向量的迭代器。这两行代码将完成对corpus中出现的每一个特征的IDF值的统计工作。
接下来,我们可以调用这个模型将任意一段语料(依然是bow向量的迭代器)转化成TFIDF向量(的迭代器)。需要注意的是,这里的bow向量必须与训练语料的bow向量共享同一个特征字典(即共享同一个向量空间)。
doc_bow = [(0, 1), (1, 1)] # 表示语料库中的第0个单词出现1次,第1个单词出现1次
print(tfidf[doc_bow]) # 将语料转化为TFIDF向量
注意,同样是出于内存的考虑,model[corpus]方法返回的是一个迭代器。如果要多次访问model[corpus]的返回结果,可以先讲结果向量序列化到磁盘上。
我们也可以将训练好的模型持久化到磁盘上,以便下一次使用:
tfidf.save("./model.tfidf") # 存储模型
tfidf = models.TfidfModel.load("./model.tfidf") # 加载模型
6、文档相似度的计算
在得到每一篇文档对应的主题向量后,我们就可以计算文档之间的相似度,进而完成如文本聚类、信息检索之类的任务。在Gensim中,也提供了这一类任务的API接口。
以信息检索为例。对于一篇待检索的query,我们的目标是从文本集合中检索出主题相似度最高的文档。
首先,我们需要将待检索的query和文本放在同一个向量空间里进行表达(以LSI向量空间为例):
from gensim import similarities
# 构造LSI模型并将待检索的query和文本转化为LSI主题向量
# 转换之前的corpus和query均是BOW向量
lsi_model = models.LsiModel(corpus, id2word=dictionary, num_topics=2)
documents = lsi_model[corpus]
query = dictionary.doc2bow(['search','word'])
query_vec = lsi_model[query]
接下来,我们用待检索的文档向量初始化一个相似度计算的对象:
index = similarities.MatrixSimilarity(documents)
我们也可以通过save()和load()方法持久化这个相似度矩阵:
index.save('tmp/deerwester.index')
index = similarities.MatrixSimilarity.load('tmp/deerwester.index')
注意,如果待检索的目标文档过多,使用similarities.MatrixSimilarity类往往会带来内存不够用的问题。此时,可以改用similarities.Similarity类。二者的接口基本保持一致。
最后,我们借助index对象计算任意一段query和所有文档的(余弦)相似度:
sims = index[query_vec] # return: an iterator of tuple (idx, sim)
7、Word2vec
在Gensim中实现word2vec模型非常简单。首先,我们需要将原始的训练语料转化成一个sentence的迭代器;每一次迭代返回的sentence是一个word(utf8格式)的列表:
class MySentences(object):
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
for fname in os.listdir(self.dirname):
for line in open(os.path.join(self.dirname, fname)):
yield line.split()
sentences = MySentences('/some/directory') # a memory-friendly iterator
接下来,我们用这个迭代器作为输入,构造一个Gensim内建的word2vec模型的对象(即将原始的one-hot向量转化为word2vec向量):
model = gensim.models.Word2Vec(sentences)
如此,便完成了一个word2vec模型的训练。
我们也可以指定模型训练的参数,例如采用的模型(Skip-gram或是CBoW);负采样的个数;embedding向量的维度等。具体的参数列表在这里
同样,我们也可以通过调用save()和load()方法完成word2vec模型的持久化。此外,word2vec对象也支持原始bin文件格式的读写。
Word2vec对象还支持online learning。我们可以将更多的训练数据传递给一个已经训练好的word2vec对象,继续更新模型的参数:
model = gensim.models.Word2Vec.load('/tmp/mymodel')
model.train(more_sentences)
若要查看某一个word对应的word2vec向量,可以将这个word作为索引传递给训练好的模型对象:
model['computer'] # raw NumPy vector of a word
8、Gensim使用案例
1)计算两个词之间的余弦距离
y2=model.similarity(u"好", u"还行") #计算两个词之间的余弦距离
print(y2)
2)计算与某个词最相近的词
for i in model.most_similar(u"滋润"): #计算余弦距离最接近“滋润”的10个词
print(i[0],i[1])
3)保存模型、加载模型
# 保存模型,以便重用
model.save("书.model")
# 对应的加载方式
# model_2 =word2vec.Word2Vec.load("text8.model")
odel = word2vec.Word2Vec.load_word2vec_format('/tmp/vectors.txt', binary=False) # 载入 .txt文件
# using gzipped/bz2 input works too, no need to unzip:
model = word2vec.Word2Vec.load_word2vec_format('/tmp/vectors.bin.gz', binary=True) # 载入 .bin文件
4)增量训练
不能对C生成的模型进行再训练。
# 增量训练
model = gensim.models.Word2Vec.load(temp_path)
more_sentences = [['Advanced', 'users', 'can', 'load', 'a', 'model', 'and', 'continue', 'training', 'it', 'with', 'more', 'sentences']]
model.build_vocab(more_sentences, update=True)
model.train(more_sentences, total_examples=model.corpus_count, epochs=model.iter)
五、新闻关键词提取案例
代码文件:案例:新闻关键词的提取与汇总.py
本案例要爬取焦点中国网的今日焦点新闻(http://www.centrechina.com/news/jiaodian),然后从爬取到的新闻正文中提取关键词,最后将新闻标题和关键词汇总,存储为csv文件。
步骤1:导入所需模块。
演示代码如下:
1 import requests # 用于获取网页源代码
2 from bs4 import BeautifulSoup # 用于从网页源代码中提取数据
3 from jieba import analyse # 用于从新闻内容中提取关键词
4 import os # 用于完成文件和文件夹相关操作
5 import pandas as pd # 用于完成数据的存储
步骤2:先爬取今日焦点新闻首页中各条新闻的详情页网址。
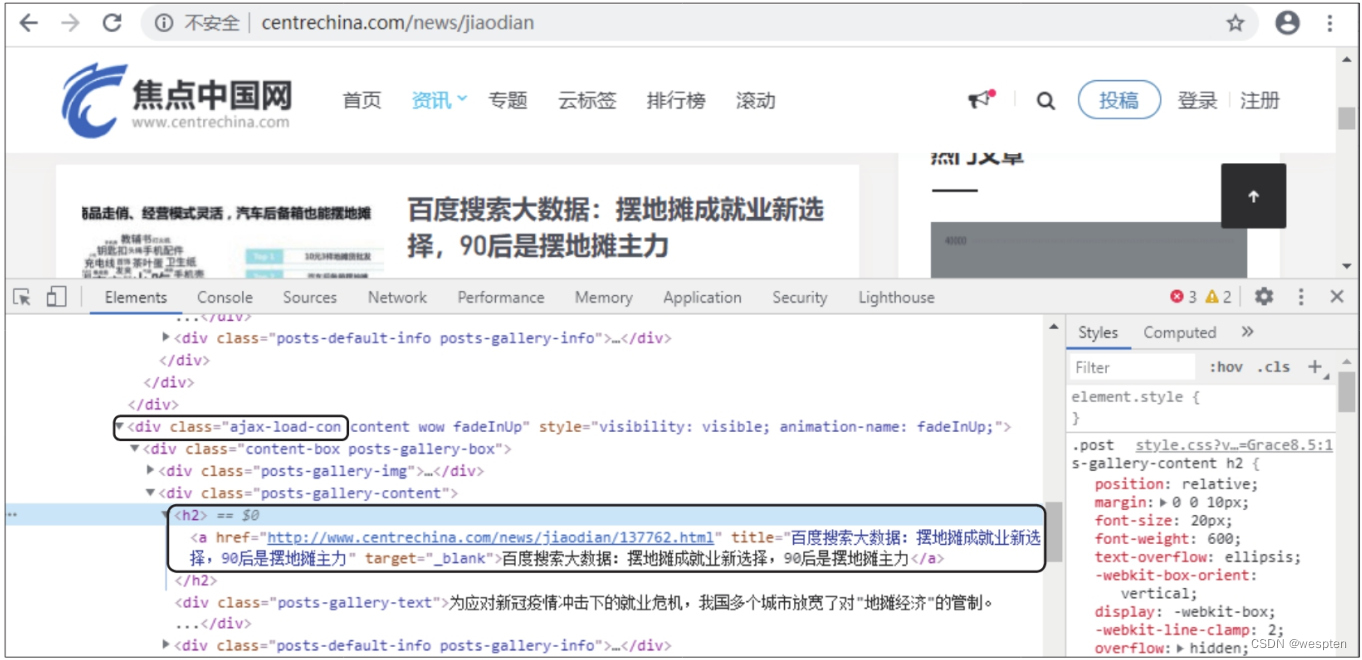
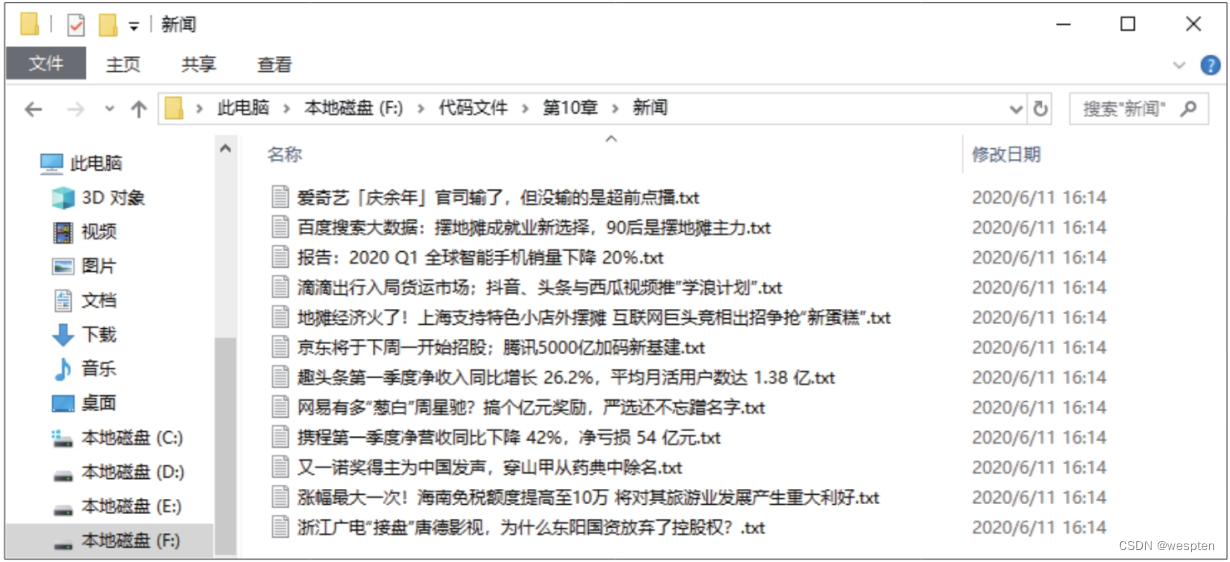
在开发者工具中搜索新闻关键词,分析出数据存在于静态网页中。使用元素选择工具选中一条新闻的链接,查看网页结构,可发现包含新闻详情页网址的标签都位于class属性值为ajax-load-con的 根据上述分析,编写代码爬取新闻详情页的网址。 演示代码如下: 步骤3:对爬取到的每个详情页网址发起请求并得到BeautifulSoup对象,再提取新闻标题和正文。这里将这两部分功能分别用不同的自定义函数来实现。 自定义函数get_text()用于请求网址并返回BeautifulSoup对象。 演示代码如下: 自定义函数parse_url()用于解析每个BeautifulSoup对象,提取新闻标题和正文,并保存为txt文件。在编写代码之前,要先分析新闻详情页的网页结构。打开任意一条新闻的详情页,利用开发者工具分析可知,标题文本位于class属性值为post-title的 标签中,如下图所示。 根据上述分析,编写parse_url()函数的代码。 演示代码如下: 需要注意的是,新闻正文位于多个 标签中,提取出来后要以追加的模式写入txt文件,因此,第7行代码中设置文件的打开模式为'a'。 步骤4:用循环取出网址列表中的每个网址,并调用get_text()函数完成新闻标题和正文的提取与保存。 演示代码如下: 代码运行结果如下图所示: 打开“新闻”文件夹,可看到多个txt文件,它们的文件名为爬取页面中的新闻标题,如下图所示。打开任意一个文件,可看到对应新闻的正文。 步骤5:读取每个txt文件中的新闻正文,然后从中提取关键词。 演示代码如下: 代码运行结果如下图所示: 步骤6:将得到的数据转换为DataFrame类型,并存储为csv文件。 演示代码如下: 运行以上代码,然后打开生成的csv文件,可看到如下图所示的关键词汇总效果。 本案例为了方便展示效果,只爬取了一页新闻。 感兴趣的朋友可以自己尝试进行扩展:通过循环和代理的方式爬取更多页的新闻并进行处理,保存到数据库中,再通过关键词查询新闻。 标签下,如下图所示。
1 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
2 url = 'http://www.centrechina.com/news/jiaodian'
3 response = requests.get(url, headers) # 对今日焦点新闻首页的网址发起请求,获取响应对象
4 html_data = response.text # 从响应对象中提取网页源代码
5 soup = BeautifulSoup(html_data, 'lxml') # 将网页源代码实例化为BeautifulSoup对象
6 hotnews_url_list = [] # 用于存储新闻详情页网址的列表
7 a_list = soup.select('.ajax-load-con h2 a') # 选中每一条新闻的<a>标签
8 for a in a_list:
9 hotnews_url_list.append(a['href']) # 从<a>标签中提取网址并添加到列表中
1 def get_text(url): # 请求网址并返回BeautifulSoup对象
2 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
3 response = requests.get(url, headers)
4 response.encoding = 'utf-8'
5 html_data = response.text
6 soup = BeautifulSoup(html_data, 'lxml') # 封装成BeautifulSoup的对象
7 parse_url(soup) # 调用BeautifulSoup对象解析函数,提取数据
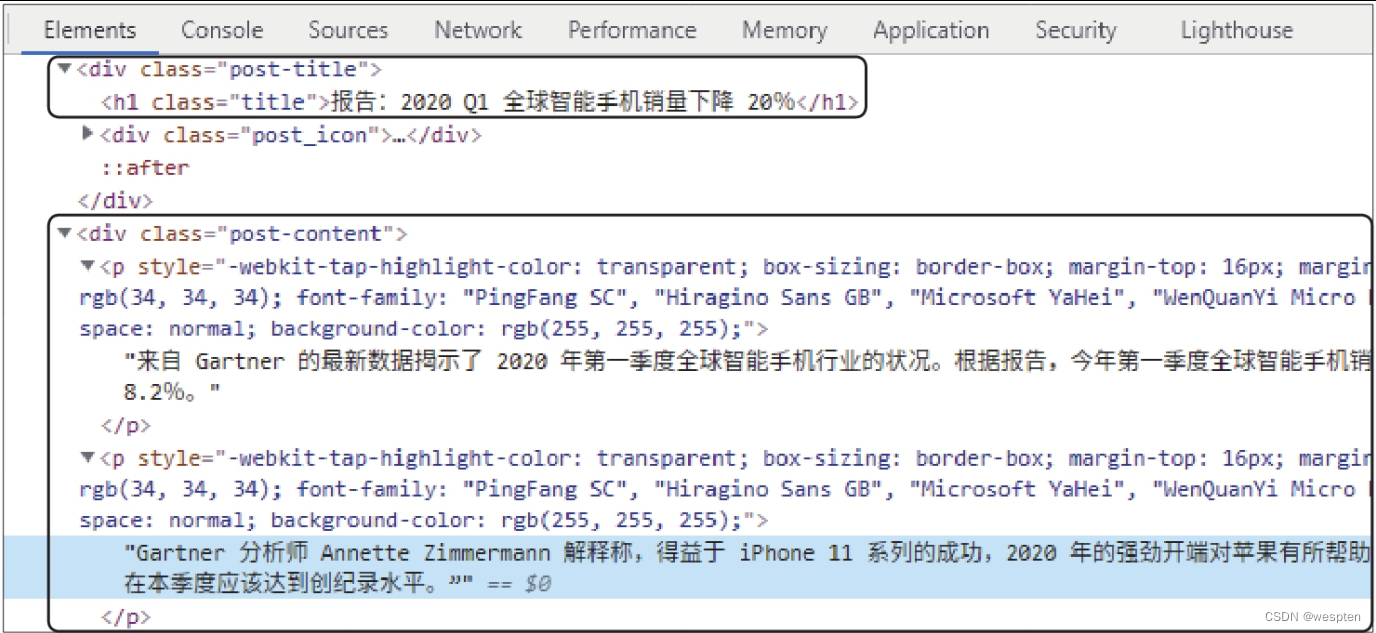
标签中,正文文本位于class属性值为post-content的
1 def parse_url(soup): # 解析BeautifulSoup对象
2 title = soup.select('.post-title h1')[0].string # 获取class属性值为post-title的标签下的<h1>标签的直系文本,即新闻标题
3 print(title)
4 p_list = soup.select('.post-content p') # 选中class属性值为post-content的标签下的所有<p>标签
5 for p in p_list: # 用循环遍历每个<p>标签
6 if p.string: # 当<p>标签的直系文本不为空时才进行写入
7 with open(f'新闻/{title}.txt', 'a', encoding='utf-8') as fp: # 创建txt文件,文件名为新闻标题,文件保存位置为代码文件所在文件夹下的“新闻”文件夹(需提前创建)
8 fp.write(p.string) # 将<p>标签的直系文本写入txt文件
1 for url in hotnews_url_list:
2 get_text(url)

1 keywords_dict = {'新闻标题': [], '新闻检索关键词': []} # 创建字典用于存储关键词提取结果
2 txt_name = os.listdir('新闻') # 获取“新闻”文件夹下的所有文件名
3 for txt_file in txt_name: # 循环取出每个文件名
4 with open('新闻/'+txt_file, 'r+', encoding='utf-8') as fp1: # 通过文件名读取新闻内容
5 txt_content = fp1.read()
6 keywords = analyse.textrank(txt_content, topK=10, withWeight=False) # 对新闻内容提取关键词
7 print(keywords)
8 keywords_dict['新闻标题'].append(txt_file) # 将文件名也就是新闻标题写入字典
9 keywords_dict['新闻检索关键词'].append(keywords) # 将提取的关键词写入字典

1 news_keyswords_info = pd.DataFrame(keywords_dict, columns=['新闻标题', '新闻检索关键词']) # 将字典转换为DataFrame
2 news_keyswords_info.to_csv('新闻关键词.csv', index=False, encoding='utf-8') # 将DataFrame存储为csv文件

版权归原作者 wespten 所有,
如有侵权,请联系我们删除。