
前言
最近在公司实习,看到其实很多落地的模型都是基于yolo来改进的。在闲暇之余又重新温故了一下yolo系列,并想着将它们进行一个总结。今天就从V1下手,接下来的几个系列也会分别进行详解。
相比起Faster R-CNN的两阶段算法,2015年诞生的YOLOv1创造性地使用端到端(end to end)结构完成了物体检测任务。直接预测物体的类别和位置,没有RPN网络,也没有Anchor的预选框,因此速度很快。
YOLOv1是YOLO系列的基准,虽然后面在工程上面大家都是直接使用YOLOV5的开源代码,但是还得需要直到这些原理,而不是像黑盒一样进行调用。后续的YOLOv3、YOLOv5都是在原来的基础上做的改进,因此完全掌握和理解YOLOv1是学好YOLO系列的关键。
1、实现方式
YOLOV1的思想就是将图像分成S*S的小网格,如果物体的中心点落在了某一个网格内,那么就由这个网格来进行预测这个物体。
每一个网格预测B个bounding boxes,以及这些bounding boxes的得分:confidence score。confidence score反映了模型对于网格中预测是否含有物体,以及是这个物体的可能性是多少。confidence定义为:
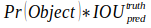
在这里需要区分开confidence score和confidence。上面公式的定义就是如果网格中不含有物体,则置信度为0,否则就是predicted box与ground truth之间的IOU。每一个bounding box由5个预测值组成:x,y,w,h,confidence。坐标(x,y)代表了bounding box的中心与grid cell边界的相对值。width,height则是相对于整幅图像的预测值(边框的宽和高),confidence就是预测框和真实框的IOU。每一个网格还要预测C个conditional class probability(条件类别概率):Pr(Class|Object),即在一个网格包含Object的前提下,它属于某个类的概率,只为每个网格预测一组(C个)类概率,而不考虑框B的数量,也就是说一个网格只能预测一个物体这也是YOLOV1的缺点之一。如果一个物体的中心点落在了某个网格内,具体是该网格的两个bounding box与真实物体框进行匹配,IoU更大的bounding box负责回归该真实物体。
对于PASCAL VOC数据集,图像输入为448×448,取S=7(即在经过神经网络之后的最终输出特征图大小为7*7),B=2(即每个grid cell中有两个bounding box负责预测落在这个gird cell中的物体),C=20(即一共有20个类别)。则输入图片经过网络的最终输出为一个7×7x30的tensor,如下图所示。且一张图片最多可以检测出49个对象,一共生成7×7×2=98个bounding box。

以上是训练的时候需要的实现方式,在进行测试的时候,就涉及到了confidence score这个概念,具体来说在测试阶段,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
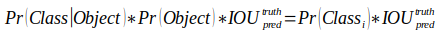
得到每个bbox的confidence score以后,设置阈值,滤掉的得分低的bboxes,对保留的bboxes进行NMS处理,就得到最终的检测结果。
2、backbone

YOLO的网络结构由24个卷积层和2个全连接层组成,网络结构借鉴了GoogLeNet分类网络结构,但是没有使用Inception module,使用的1×1卷积(交替的1×1卷积用来减少前几层的特征空间)和3×3卷积简单替代。网络输入的图片大小为448×448,最终输出为7×7×30的张量(在PASCAL VOC数据集上)。
在这里需要注意的是因为最后用到了两层全连接层,这就使得对网络的输入有一定的要求,不可以变换其余大小的输入。
3、训练
预训练
YOLOV1会现在imagnet上面进行预训练一个分类网络,预训练的网络即为整个网络结构的前20个卷积层+池化层+全连接层。然后再去进行训练检测网络,在预训练网络的基础上添加4个卷积层和2个全连接层,随机初始化权重。最后一层预测类概率和bounding box坐标。通过图像宽度和高度对bounding box的宽度和高度进行归一化,使它们下降到[0,1]之间,同时将(x,y)坐标参数化为特定网格单元位置的偏移,因此它们也在[0,1]之间。
损失函数
YOLOV1的损失函数算是比较经典的了,后面的也是基于这个损失函数进行梯度下降的。 YOLOv1的Loss一共由5个部分组成,均使用均方误差(sum-square error,MSE)损失,如下图所示:


在这里需要注意的是第三点的值是0.5,而不是5。
4、优劣
YOLOV1是采用回归的思想,并没有提前设计好锚框,使用轻量型的网络对物体进行定位和分类,处理速度很快。但是不足也很明显:
● 由于每一个区域默认只有两个bounding box做预测,并且只有一个类别,因此YOLOv1有这天然的检测限制。这种限制会导致模型对于小物体,以及靠得特别近的物体检测效果不好(一个网格只能预测一个物体)。
● 由于没有类似于Anchor的先验框,模型对于新的或者不常见宽高比例的物体检测效果不好。另外,由于下采样率较大,边框的检测精度不高。
参考:【目标检测】单阶段算法--YOLOv1详解
版权归原作者 Aliert 所有, 如有侵权,请联系我们删除。