
CoN要点
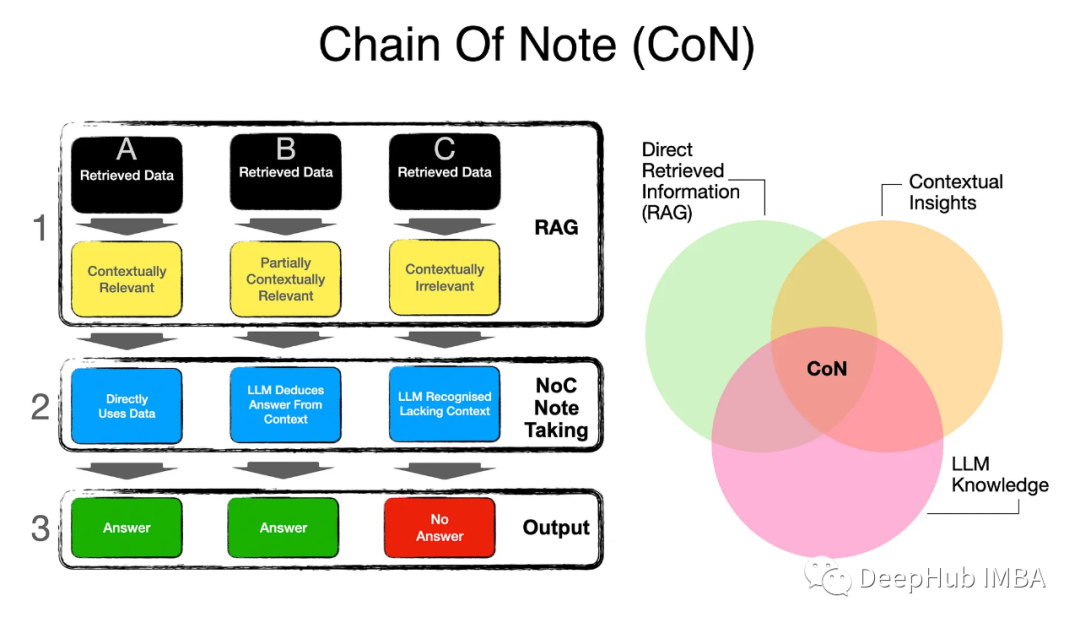
CoN框架由三种不同的类型组成,研究称之为阅读笔记。
上面的图像,类型(A)显示了检索到的数据或文档回答查询的位置。LLM仅使用NLG从提供的数据中格式化答案。
类型(B)中,检索到的文档不直接回答查询,但是上下文洞察足以使LLM将检索到的文档与它自己的知识结合起来,从而推断出答案。
类型(C)是指检索到的文档是不相关的,LLM没有相关的知识来响应,导致框架没有给出错误或错误的答案。
CoN是一个自适应过程,或逻辑和推理层,其中直接信息与上下文推理和法学硕士知识识别相平衡。
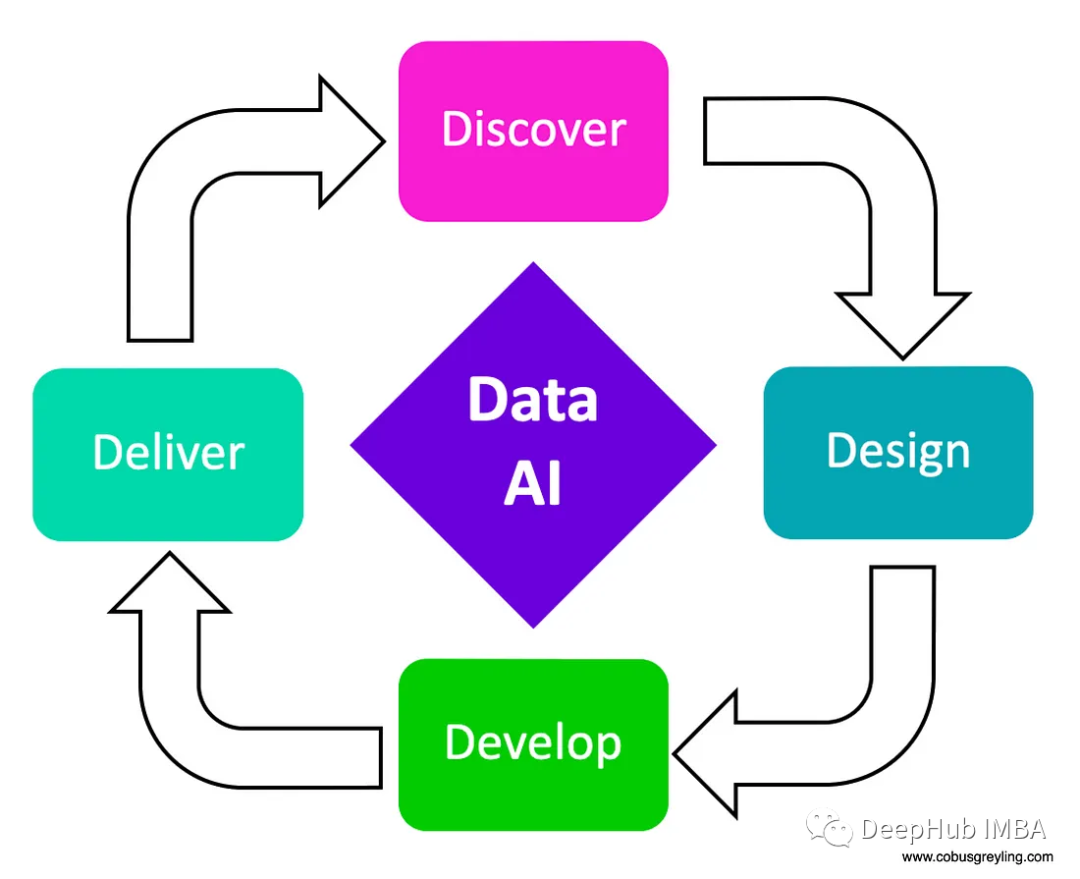
数据的四个方面
为了使模型具有生成NoC阅读笔记的能力,需要进行微调。
论文训练了一个llama - 27b模型,将笔记能力整合到CON中。
CoN不仅是一个提示模板,而且还包含了一个经过微调的可以记笔记模型。因此CoN可以看作是RAG和Fine-Tuning的结合。
这又回到了数据人工智能的概念和数据的四个方面,即数据发现、数据设计、数据开发和数据交付。
一般来说,RAG和具体的CoN可以看作是数据交付过程的一部分。但是为了训练NoC模型,需要一个数据发现、数据设计和数据开发的过程。
对于这项研究,收集适当的训练数据至关重要。
每个阅读笔记的手动注释是资源密集型的,因此研究团队采用了最先进的语言模型来生成注释。
如果在企业环境中实施NoC,那么人工智能加速数据生产力工作室将是至关重要的。这种“人工”的过程对于具有清晰信号的相关训练数据非常重要。
CoN 模板
下面是LangSmith的CoN模板。给定一个问题,查询Wikipedia并使用带有Chain-of-Note提示的OpenAI的API提取答案。
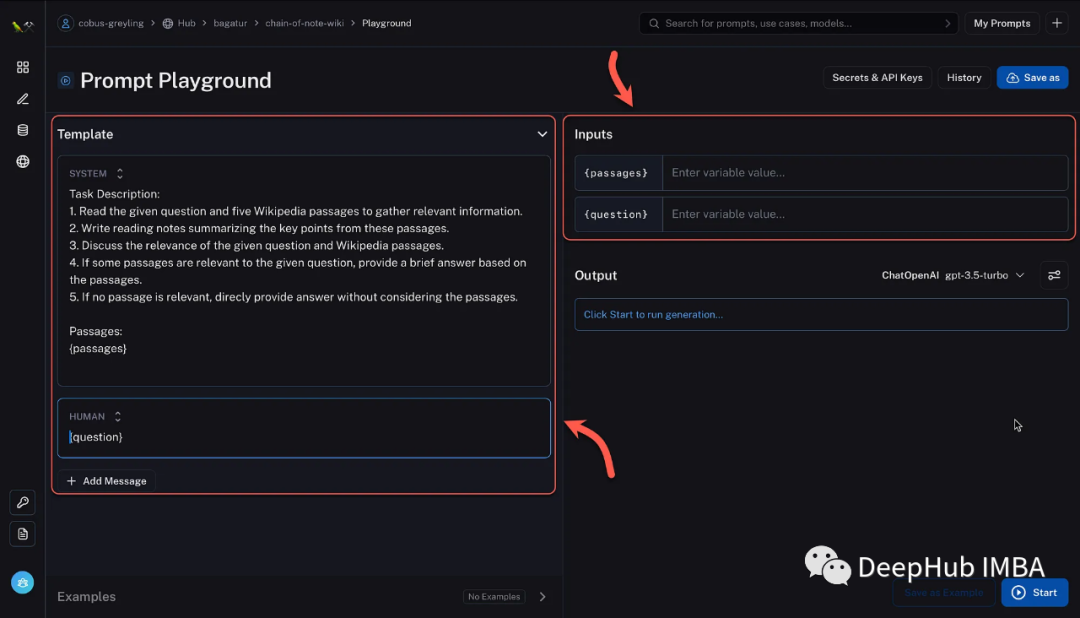
对于标准RAG:
Task Description: The primary objective is to briefly answer a specific
question.
对于带有CON的RALM:
Task Description:
1. Read the given question and five Wikipedia passages to gather relevant
information.
2. Write reading notes summarizing the key points from these passages.
3. Discuss the relevance of the given question and Wikipedia passages.
4. If some passages are relevant to the given question, provide a brief
answer based on the passages.
5. If no passage is relevant, direcly
provide answer without considering the passages.
CoN的对于RAG的改善
RAG检索增强生成已经成为llm的重要推动者。最值得注意的是,随着RAG的引入,模型幻觉得到了很大程度的抑制,RAG也可以作为模型性能的均衡器。
RAG面临的挑战是确保在推理时向LLM提供准确、高度简洁和上下文相关的数据。
但是不相关数据的检索可能导致错误的响应,并可能导致模型忽略其固有的知识,即使它拥有足够的信息来处理查询。
所以CoN 作为一种新的方法,提高RAG的弹性。特别是在RAG数据不包含与查询上下文相关的明确信号的情况下。
该研究的下图更详细地说明了NoC的实现。该框架主要构建了三种类型的阅读笔记……

CoN框架为检索到的文档生成顺序的阅读注释,从而能够系统地评估从外部文档检索到的信息的相关性和准确性。
通过创建顺序阅读笔记,该模型不仅评估每个文档与查询的相关性,而且还确定这些文档中最关键和最可靠的信息片段。
这个过程有助于过滤掉不相关或不可信的内容,从而产生更准确和上下文相关的响应。
总结
基于llm的生成式人工智能实现的答案不是RAG或模型微调。而是两者的结合。因为上下文参考是非常重要的,从数据提取中的信号越清晰越好。经过微调的模型提供了额外的上下文,以及检索到的文档和NoC提示模板。数据与高效的数据发现和设计方法将变得越来越重要。
论文地址: