
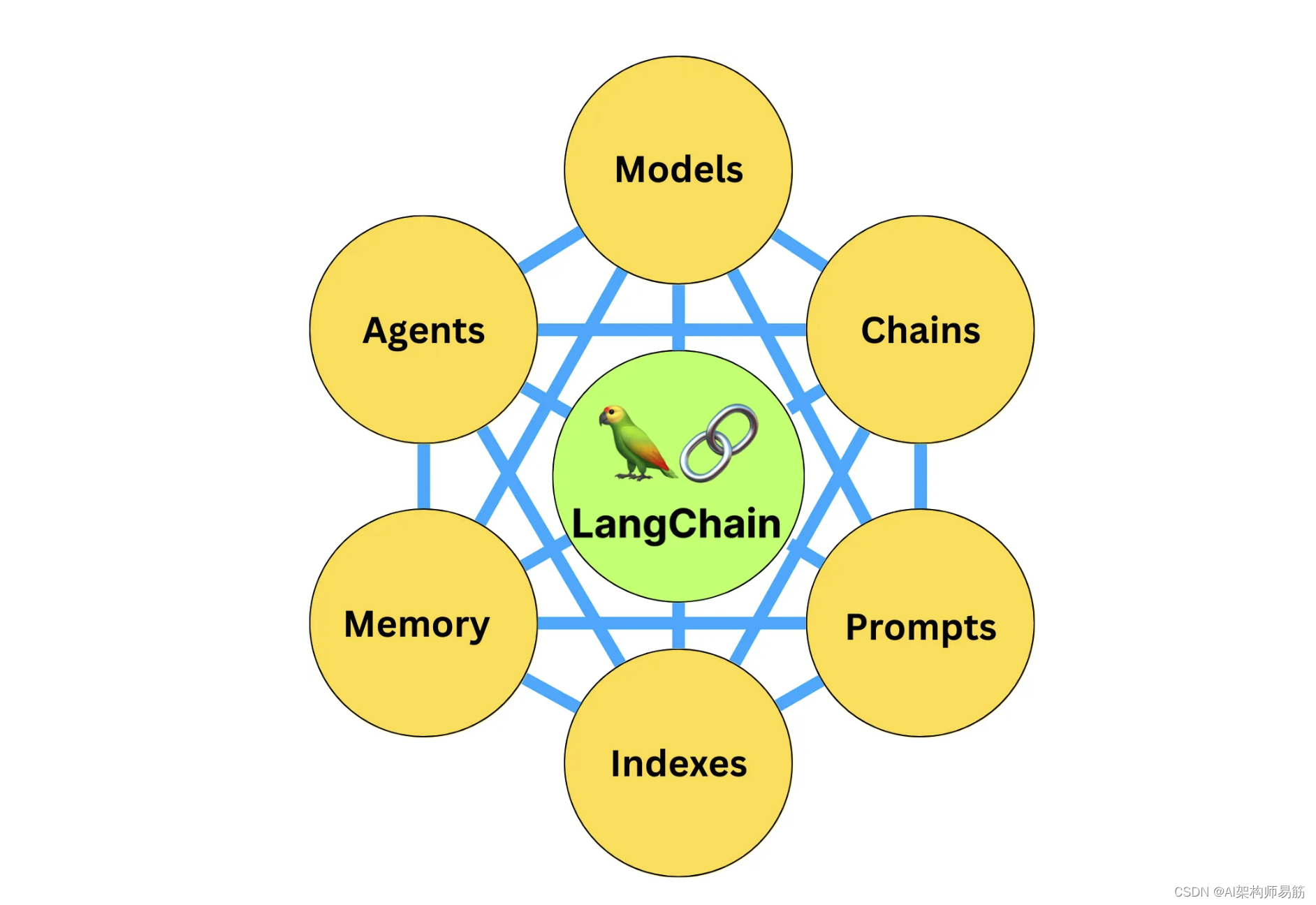
LangChain系列文章
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
- LangChain 5易速鲜花内部问答系统
- LangChain 6根据图片生成推广文案HuggingFace中的image-caption模型
- LangChain 7 文本模型TextLangChain和聊天模型ChatLangChain
- LangChain 8 模型Model I/O:输入提示、调用模型、解析输出
- LangChain 9 模型Model I/O 聊天提示词ChatPromptTemplate, 少量样本提示词FewShotPrompt
- LangChain 10思维链Chain of Thought一步一步的思考 think step by step
- LangChain 11实现思维树Implementing the Tree of Thoughts in LangChain’s Chain
- LangChain 12调用模型HuggingFace中的Llama2和Google Flan t5
- LangChain 13输出解析Output Parsers 自动修复解析器
- LangChain 14 SequencialChain链接不同的组件
- LangChain 15根据问题自动路由Router Chain确定用户的意图
- LangChain 16 通过Memory记住历史对话的内容
- LangChain 17 LangSmith调试、测试、评估和监视基于任何LLM框架构建的链和智能代理
- LangChain 18 LangSmith监控评估Agent并创建对应的数据库
- LangChain 19 Agents Reason+Action自定义agent处理OpenAI的计算缺陷
- LangChain 20 Agents调用google搜索API搜索市场价格 Reason Action:在语言模型中协同推理和行动
- LangChain 21 Agents自问自答与搜索 Self-ask with search
- LangChain 22 LangServe用于一键部署LangChain应用程序
- LangChain 23 Agents中的Tools用于增强和扩展智能代理agent的功能
- LangChain 24 对本地文档的搜索RAG检索增强生成Retrieval-augmented generation
- LangChain 25: SQL Agent通过自然语言查询数据库sqlite
- LangChain 26: 回调函数callbacks打印prompt verbose调用
- LangChain 27 AI Agents角色扮演多轮对话解决问题CAMEL
- LangChain 28 BabyAGI编写旧金山的天气预报
- LangChain 29 调试Debugging 详细信息verbose
- LangChain 30 ChatGPT LLM将字符串作为输入并返回字符串Chat Model将消息列表作为输入并返回消息
- LangChain 31 模块复用Prompt templates 提示词模板
- LangChain 32 输出解析器Output parsers
- LangChain 33: LangChain表达语言LangChain Expression Language (LCEL)
- LangChain 34: 一站式部署LLMs使用LangServe
1. 安全
LangChain拥有与各种外部资源(如本地和远程文件系统、API和数据库)的大型生态系统集成。这些集成使开发人员能够创建多功能的应用程序,将LLMs的强大功能与访问、交互和操作外部资源的能力相结合。
2. 最佳实践
在构建这样的应用程序时,开发人员应该记住遵循良好的安全实践:
- 限制权限:将权限专门限定在应用程序的需求范围内。授予广泛或过多的权限可能会引入重大的安全漏洞。为了避免这种漏洞,考虑使用只读凭据,禁止访问敏感资源,使用沙箱技术(如在容器内运行)等,以适应您的应用程序。
- 预防潜在滥用:就像人类可能犯错一样,大型语言模型(LLMs)也可能犯错。始终假设任何系统访问或凭据可能会以任何权限允许的方式使用。例如,如果一对数据库凭据允许删除数据,最安全的做法是假设任何能够使用这些凭据的LLM实际上可能会删除数据。
- 深度防御:没有完美的安全技术。微调和良好的链设计可以减少,但不能消除,大型语言模型(LLM)可能犯错的几率。最好结合多层安全方法,而不是依赖任何单一防御层来确保安全。例如:同时使用只读权限和沙箱技术,以确保LLMs只能访问明确为它们使用的数据。
2.1 不这样做的风险包括但不限于:
- 数据损坏或丢失。
- 未经授权访问机密信息。
- 关键资源性能或可用性受损。
2.2 示例场景及缓解策略:
- 用户可能会要求具有文件系统访问权限的代理删除不应删除的文件或读取包含敏感信息的文件的内容。为了缓解,限制代理仅使用特定目录,并且只允许它读取或写入安全的文件。考虑通过在容器中运行代理来进一步隔离代理。
- 用户可能会要求具有对外部 API 写入访问权限的代理向 API 写入恶意数据,或从该 API 中删除数据。为了缓解,给代理提供只读 API 密钥,或限制其仅使用已经抵御此类滥用的端点。
- 用户可能会要求具有访问数据库的权限的代理删除表或改变模式。为了缓解,将凭据范围限制为代理需要访问的表,并考虑发行只读凭据。
如果您正在构建访问文件系统、API 或数据库等外部资源的应用程序,请考虑与公司的安全团队交谈,以确定如何最好地设计和保护您的应用程序。
3. 汇报漏洞
请通过电子邮件向security@langchain.dev报告安全漏洞。这将确保问题得到及时分配和必要的处理。
4. 企业解决方案
LangChain可能为有额外安全要求的客户提供企业解决方案。请通过sales@langchain.dev与我们联系。
代码
https://github.com/zgpeace/pets-name-langchain/tree/develop
参考
本文转载自: https://blog.csdn.net/zgpeace/article/details/135188080
版权归原作者 AI架构师易筋 所有, 如有侵权,请联系我们删除。
版权归原作者 AI架构师易筋 所有, 如有侵权,请联系我们删除。