
文章目录
摘要
记录一下,找到两个PDF公式转Latex的开源项目和一个数据集
数据集 UniMER
介绍
UniMER数据集是一个专为推动数学表达式识别(MER)领域进步而精心策划的专业集合。它包括全面的UniMER-1M训练集,该训练集包含超过一百万个实例,代表了一系列多样且复杂的数学表达式,以及精心设计的UniMER测试集,用于在现实世界场景下对MER模型进行基准测试。数据集的详细信息如下:
UniMER-1M训练集:
- 总样本数:1,061,791个LaTeX-图像对
- 组成:简洁与复杂、扩展公式表达式的均衡混合
- 目标:训练出稳健、高精度的MER模型,提高识别精度和泛化能力
UniMER测试集:
- 总样本数:23,757个,分为四种类型的表达式: - 简单打印表达式(SPE):6,762个样本- 复杂打印表达式(CPE):5,921个样本- 屏幕截图表达式(SCE):4,742个样本- 手写表达式(HWE):6,332个样本
- 目的:在各种现实世界条件下对MER模型进行全面评估
下载链接
您可以从OpenDataLab(推荐中国用户使用)或HuggingFace下载该数据集。
找到一个非常不错的公式转化开源项目。将论文中的公式转为Latex。
LaTeX-OCR
github链接:
https://github.com/lukas-blecher/LaTeX-OCR
包含训练测试等,
安装简单非常,
安装
pix2tex
:
pip install "pix2tex[gui]"
然后,下载权重到安装位置。
权重链接:
https://github.com/lukas-blecher/LaTeX-OCR/releases

注意:Weight release,别选错了。
然后,运行命令:
latexocr
就可以运行了。
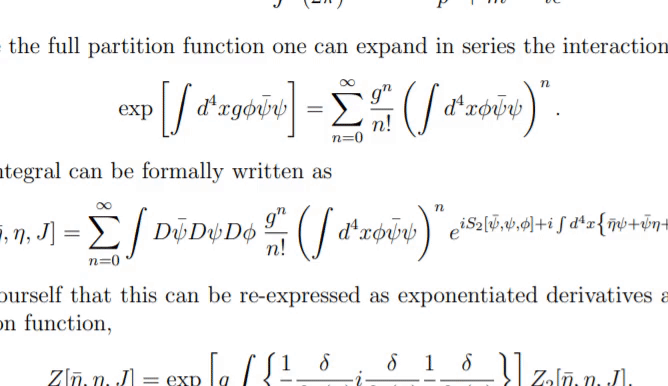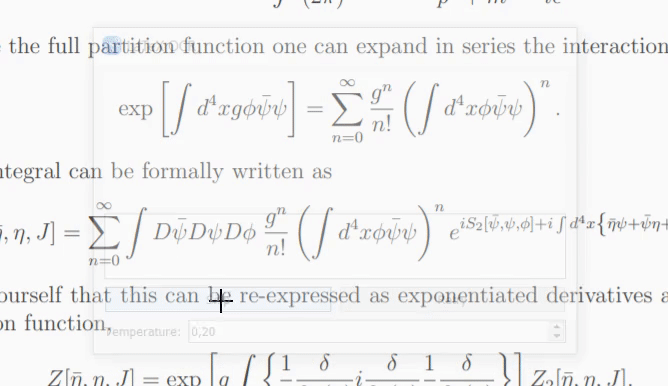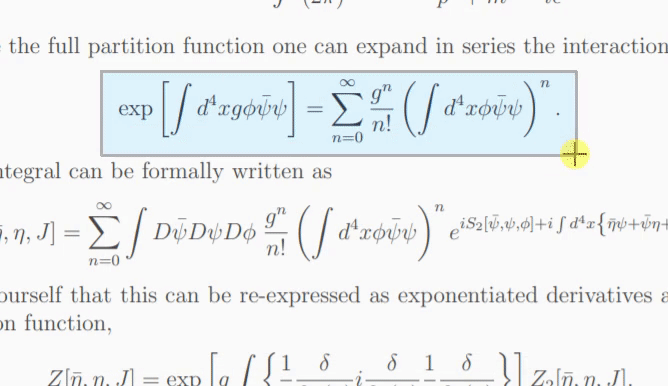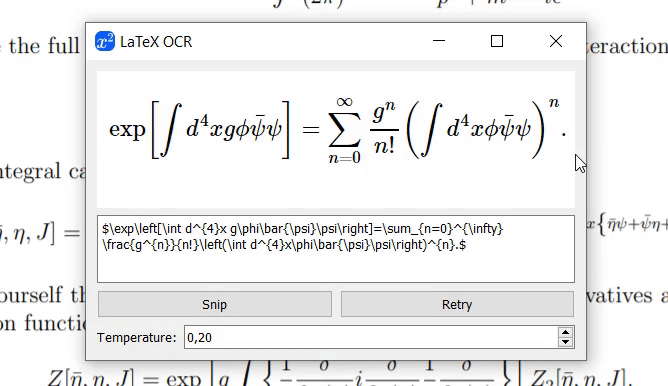
UniMERNet
github链接:
https://github.com/opendatalab/UniMERNet。
没有训练,只有测试。
安装
建议创建虚拟环境,我在base环境上安装没有成功,安装了python3.10的虚拟环境后才没有问题。
conda create -n unimernet python=3.10
conda activate unimernet
pip install--upgrade unimernet
下载项目和模型命令如下:
git clone https://github.com/opendatalab/UniMERNet.git
cd UniMERNet/models
# Download the model and tokenizer individually or use git-lfsgit lfs installgit clone https://huggingface.co/wanderkid/unimernet
如果没有git,也可以手动去huggingface上下载模型,将模型下载到本地的models下,路径要正确!
运行demo.py,
python demo.py
运行UI界面,执行命令
bash unimernet_gui
UniMERNet
UniMER 用的数据集
介绍
UniMER数据集是一个专为推动数学表达式识别(MER)领域进步而精心策划的专业集合。它包括全面的UniMER-1M训练集,该训练集包含超过一百万个实例,代表了一系列多样且复杂的数学表达式,以及精心设计的UniMER测试集,用于在现实世界场景下对MER模型进行基准测试。数据集的详细信息如下:
UniMER-1M训练集:
- 总样本数:1,061,791个LaTeX-图像对
- 组成:简洁与复杂、扩展公式表达式的均衡混合
- 目标:训练出稳健、高精度的MER模型,提高识别精度和泛化能力
UniMER测试集:
- 总样本数:23,757个,分为四种类型的表达式: - 简单打印表达式(SPE):6,762个样本- 复杂打印表达式(CPE):5,921个样本- 屏幕截图表达式(SCE):4,742个样本- 手写表达式(HWE):6,332个样本
- 目的:在各种现实世界条件下对MER模型进行全面评估
下载链接
您可以从OpenDataLab(推荐中国用户使用)或HuggingFace下载该数据集。
PDF-Extract-Kit
这个还没有调通。
github链接:
https://github.com/opendatalab/PDF-Extract-Kit
一个完整的工作流,支持PDF的分析,将PDF的论文内容识别出来。
整体介绍
PDF文档中包含大量知识信息,然而提取高质量的PDF内容并非易事。为此,我们将PDF内容提取工作进行拆解:
- 布局检测:使用LayoutLMv3模型进行区域检测,如
图像,表格,标题,文本等; - 公式检测:使用YOLOv8进行公式检测,包含
行内公式和行间公式; - 公式识别:使用UniMERNet进行公式识别;
- 光学字符识别:使用PaddleOCR进行文本识别;
注意:
PDF内容提取框架如下图所示

PDF-Extract-Kit输出格式
{
"layout_dets": [ # 页中的元素
{
"category_id": 0, # 类别编号, 0~9,13~15
"poly": [
136.0, # 坐标为图片坐标,需要转换回pdf坐标, 顺序是 左上-右上-右下-左下的x,y坐标
781.0,
340.0,
781.0,
340.0,
806.0,
136.0,
806.0
],
"score": 0.69, # 置信度
"latex": '' # 公式识别的结果,只有13,14有内容,其他为空,另外15是ocr的结果,这个key会换成text
},
...
],
"page_info": { # 页信息:提取bbox时的分辨率大小,如果有缩放可以基于该信息进行对齐
"page_no": 0, # 页数
"height": 1684, # 页高
"width": 1200 # 页宽
}
}
其中category_id包含的类型如下:
{0: 'title', # 标题
1: 'plain text', # 文本
2: 'abandon', # 包括页眉页脚页码和页面注释
3: 'figure', # 图片
4: 'figure_caption', # 图片描述
5: 'table', # 表格
6: 'table_caption', # 表格描述
7: 'table_footnote', # 表格注释
8: 'isolate_formula', # 行间公式(这个是layout的行间公式,优先级低于14)
9: 'formula_caption', # 行间公式的标号
13: 'inline_formula', # 行内公式
14: 'isolated_formula', # 行间公式
15: 'ocr_text'} # ocr识别结果
效果展示
结合多样性PDF文档标注,我们训练了鲁棒的
布局检测
和
公式检测
模型。在论文、教材、研报、财报等多样性的PDF文档上,我们的pipeline都能得到准确的提取结果,对于扫描模糊、水印等情况也有较高鲁棒性。

评测指标
现有开源模型多基于Arxiv论文类型数据进行训练,面对多样性的PDF文档,提前质量远不能达到实用需求。相比之下,我们的模型经过多样化数据训练,可以适应各种类型文档提取。
布局检测
我们与现有的开源Layout检测模型做了对比,包括DocXchain、Surya、360LayoutAnalysis的两个模型。而LayoutLMv3-SFT指的是我们在LayoutLMv3-base-chinese预训练权重的基础上进一步做了SFT训练后的模型。论文验证集由402张论文页面构成,教材验证集由587张不同来源的教材页面构成。
模型论文验证集教材验证集mAPAP50AR50mAPAP50AR50DocXchain52.869.577.334.950.163.5Surya24.239.466.113.923.349.9360LayoutAnalysis-Paper37.753.659.820.731.343.6360LayoutAnalysis-Report35.146.955.925.433.745.1LayoutLMv3-SFT77.693.395.567.982.787.9
公式检测
我们与开源的模型Pix2Text-MFD做了对比。另外,YOLOv8-Trained是我们在YOLOv8l模型的基础上训练后的权重。论文验证集由255张论文页面构成,多源验证集由789张不同来源的页面构成,包括教材、书籍等。
模型论文验证集多源验证集AP50AR50AP50AR50Pix2Text-MFD60.164.658.962.8YOLOv8-Trained87.789.982.487.3
公式识别
公式识别我们使用的是Unimernet的权重,没有进一步的SFT训练,其精度验证结果可以在其GitHub页面获取。
使用教程
环境安装
conda create -n pipeline python=3.10
pip install-r requirements.txt
pip install --extra-index-url https://miropsota.github.io/torch_packages_builder detectron2==0.6+pt2.3.1cu121
安装完环境后,可能会遇到一些版本冲突导致版本变更,如果遇到了版本相关的报错,可以尝试下面的命令重新安装指定版本的库。
pip installpillow==8.4.0
除了版本冲突外,可能还会遇到torch无法调用的错误,可以先把下面的库卸载,然后重新安装cuda12和cudnn。
pip uninstall nvidia-cusparse-cu12
参考模型下载下载所需模型权重
在Windows上运行
如需要在Windows上运行本项目,请参考在Windows环境下使用PDF-Extract-Kit。
在macOS上运行
如需要在macOS上运行本项目,请参考在macOS系统使用PDF-Extract-Kit。
运行提取脚本
python pdf_extract.py --pdf data/pdfs/ocr_1.pdf
相关参数解释:
--pdf待处理的pdf文件,如果传入一个文件夹,则会处理文件夹下的所有pdf文件。--output处理结果保存的路径,默认是"output"--vis是否对结果可视化,是则会把检测的结果可视化出来,主要是检测框和类别--render是否把识别得的结果渲染出来,包括公式的latex代码,以及普通文本,都会渲染出来放在检测框中。注意:此过程非常耗时,另外也需要提前安装xelatex和imagemagic。
版权归原作者 AI浩 所有, 如有侵权,请联系我们删除。