
上一期我们通过对实验:银行卡卡号识别 加深了对前面所学openCV图像处理的一些理解
openCV实践项目:银行卡卡号识别_老师我作业忘带了的博客-CSDN博客
本次图片文本检测相对于要容易一些,内容如下:
一、流程说明


把一个这样的图片,通过仿射变换转换成那样的图片。
然后再通过 pytesseract 读取图片内容得到图片中的文本就好了。

所用到的知识同样大部分来源于入门opencv的第三篇文章: 第三篇文章
新增知识:仿射变换、ocr识别,下面代码处会有讲解。
注:本文使用现成图片,轮廓检测较为明显,若是自己拍照,建议让轮廓/边缘清晰一些。
二、tesseract-ocr安装配置
第一步:下载安装
在开始前,我们需要去 下载(连接) 一下tesseract-ocr,建议选择一个稳定点的版本下载。
现在完成之后安装的时候点下一步下一步就行了,记得记一下安装路径,下一步要配置环境变量(不配置也可以)
第二步:环境变量
注:即使不配置环境变量也不影响后面在代码中的操作,即这一步可以跳过。不理解环境变量意义的可以看一下这篇文章: 这篇文章
上一步安装完成后,把路径加进去:
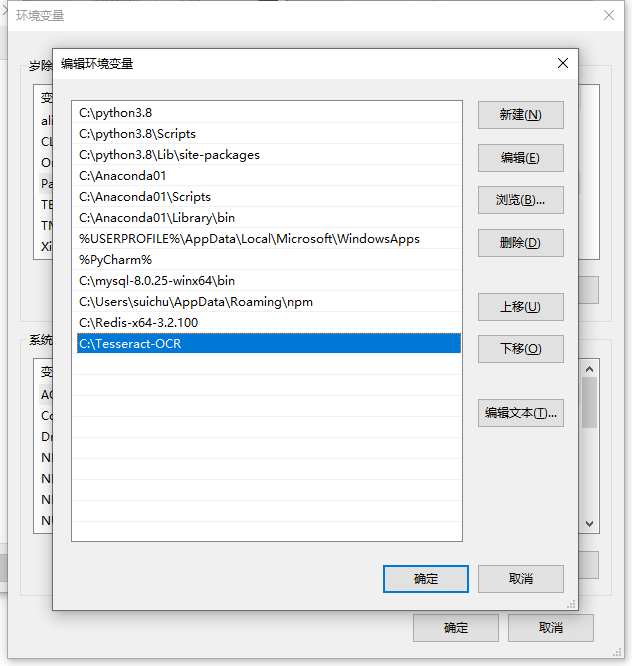
打开cmd,输入tesseract -v 得到版本信息,没报错就说明环境变量配置成功。

进行测试,比如我桌面上有这样一张图片:

在cmd中输入:tesseract 图片路径 输出路径 如:
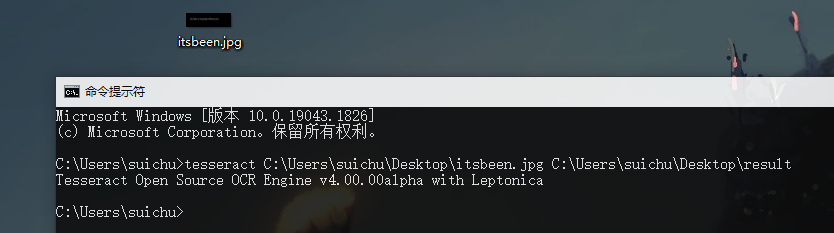
注:这个路径不用手打,直接把图片拖进去。默认的话路径就是C:\Users\suichu
然后我的桌面上出现了一个叫result.txt的文本文件:
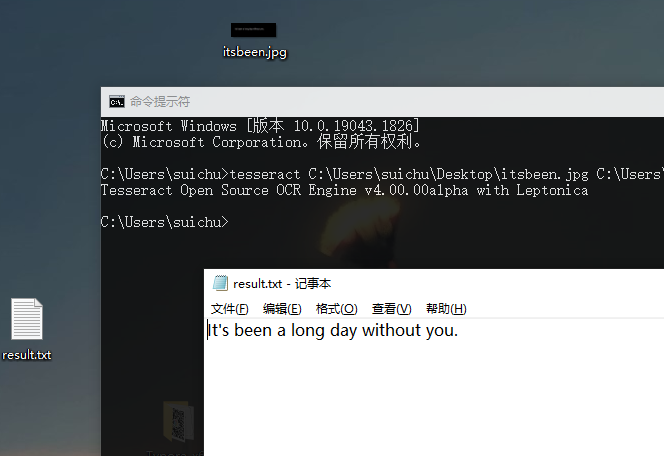
第三步:下载pytesseract
pip install pytesseract
下载完成之后,有一件事要记得注意一下,我们打开对应的python环境的文件,比如我下载在anaconda中,那我的路径就是:C:\Anaconda01**\Lib\site-packages\pytesseract **总之,打开它:
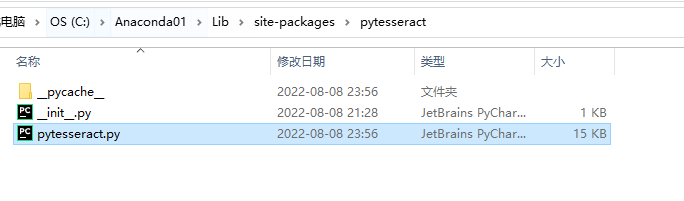
这里原本是相对路径,把它手动设置成绝对路径,以防报错。

当然 也可以不管,报错了再回来看。
from PIL import Image
import pytesseract
# 有时也可以提前加一些灰度转换 二值处理 滤波操作等,效果可能会更好一些。
text = pytesseract.image_to_string(Image.open(r'./data/image.png'))
print(text)
第四步:下载中文包
这一步是用来识别中文的,其实安装的时候有一个选项会问你是否下载中文包,不过比较慢还是自己下载吧。
github下载中文包:下载连接
下载完成后放到tessdata里就好
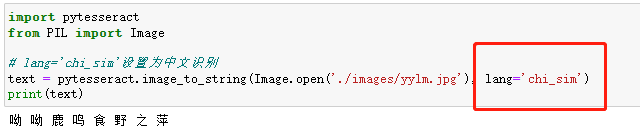
我们识别下方这句诗:

import pytesseract
from PIL import Image
# lang='chi_sim'设置为中文识别
text = pytesseract.image_to_string(Image.open('./images/yylm.jpg'), lang='chi_sim')
print(text)
三、代码及原理
定义图片展示函数 和 图片大小设置函数
import cv2
import numpy as np
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
前者是为了方便代码执行过程中图片处理得如何了,方便我们观察。
后者是为了方便我们管理图的大小,比如resize(img, width=500) 或 resize(img, height=500) 可以把大大小小的图片转换成相应比例的统一宽高的图片,方便我们观察。
读取输入图片,做预处理;
# 读取输入
image = cv2.imread("./images/receipt.jpg")
# 统一图片大小
orig = image.copy()
image = resize(orig, height=500)
# 记录变化比例 后面会用到
ratio = image.shape[0] / 500.0
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转化为灰度图
gray = cv2.GaussianBlur(gray, (5, 5), 0) # 高斯滤波降噪
cv_show('edged',gray)

进行边缘检测;
# 边缘检测
edged = cv2.Canny(gray, 75, 200)
cv_show('edged',edged)

进行轮廓检测;
由于我们后面仿射变换需要的只是图片中对象的四个角的坐标,因此轮廓检测时把面积最大的轮廓拿出来就行。
# 轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
# 根据面积倒序 只要最大的面积那n组。
need_cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:4]# 几组都行,其实倒序后的第一个基本上就是面积最大的。
此时,第一个轮廓也有可能与第二个轮廓很像或者基本表示同一个轮廓,毕竟图片中的对象不够平整。 我们先一步进行边缘检测,后一步进行轮廓检测。本例中排序完成后,cnts[0]与cnts[1]都是我们想要的那部分。即下一步绿色框中的图片:
遍历轮廓,进行轮廓近似;
由于我们上一步取出好几组(基本上第一组就是了)可能的轮廓(每个轮廓是一组点集,因为图像并不平整,所以我们接下来进行轮廓近似,我们对这几组进行遍历,确定它有四个点就说明是我们想要的答案。 不明白轮廓近似的建议去了解一下。
# 遍历轮廓
for c in cnts:
# 轮廓近似
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 近似成4个点的时候就拿出来
if len(approx) == 4:
screenCnt = approx
break
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
cv_show('Outline',image)

解释一下这一步和上一步:其实就是我们边缘检测后的图片进行轮廓检测,取出轮廓面积最大的n组轮廓,每个轮廓是一组点集,不一定就是四个点,也可能是100个构成一个轮廓,我们按顺序进行轮廓近似,一般循环到第一遍的时候就可以近似成我们想要的上图的这个轮廓了,我们也就得到了这四个顶点。
透视变换
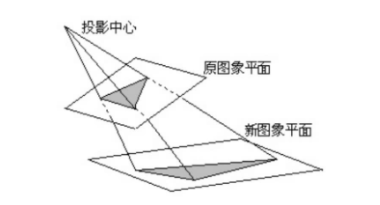
我们上一步拿到了那四个点的坐标,那个对应的轮廓也不是平行的,我们要做的就是把“它正过来”,平铺在图片上。
我们首先要确定四个的位置,左上、右上、右下、左上。
# 处理点坐标,返回rect使其顺序为左上,右上,右下,左下
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype="float32")
# 计算左上,右下 左上的x和y都是最小的 右下的x和y都是最大的
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下 np.diff后一项减前一项
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
两点间距离公式,我们计算最长的宽高,知道宽和高了我们就可以自己规定个矩阵,根据变换矩阵
把原图转换为“铺平 铺满”后的图片:
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
tl, tr, br, bl = rect
# 两点间距离公式计算输入的w和h值
widthTop = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
widthBot = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
# 要最大的 看着方便 下同
maxWidth = max(int(widthTop), int(widthBot))
heightRight = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightLeft = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightRight), int(heightLeft))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype="float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
我们执行上方函数:
# 透视变换 记得乘以比例,我们之前为了方便观察统一过大小。
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)
cv_show('warped',resize(warped, height=650))

最后进行ocr检测
对上一步获得的warped进行二值处理,使用pytesseract.image_to_string()即可。
from PIL import Image
import pytesseract
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]
filename = "{}.png".format('内容')
cv2.imwrite(filename, gray)
text = pytesseract.image_to_string(Image.open(filename))
print(text)
os.remove(filename)
得到结果

四、完整代码
# 导入工具包
import os
import cv2
import pytesseract
import numpy as np
from PIL import Image
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype="float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
tl, tr, br, bl = rect
# 两点间距离公式计算输入的w和h值
widthTop = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
widthBot = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
maxWidth = max(int(widthTop), int(widthBot))
heightRight = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightLeft = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightRight), int(heightLeft))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype="float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
# 读取输入
image = cv2.imread("./images/receipt.jpg")
# 记录比例 后面会用到
ratio = image.shape[0] / 500.0
orig = image.copy()
# 统一图片大小
image = resize(orig, height=500)
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
# 边缘检测
edged = cv2.Canny(gray, 75, 200)
# 轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:3]
# 遍历轮廓
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 4个点的时候就拿出来
if len(approx) == 4:
screenCnt = approx
break
# 透视变换
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)
# 文本检测
gray = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
# gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
gray = cv2.medianBlur(gray, 3)
filename = "{}.png".format('finally_picture')
cv2.imwrite(filename, gray)
text = pytesseract.image_to_string(Image.open(filename))
print(text)
os.remove(filename)
版权归原作者 老师我作业忘带了 所有, 如有侵权,请联系我们删除。