
中文ChatGPT平替——ChatGLM-6B
ChatGLM-6B
简介
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B1 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。ChatGLM 当前版本模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。它是不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。2022年8月,我们向研究界和工业界开放了拥有1300亿参数的中英双语稠密模型 GLM-130B1,该模型有一些独特的优势:
- 双语: 同时支持中文和英文。
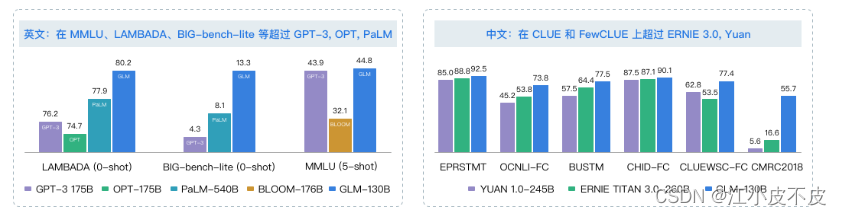
- 高精度(英文): 在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
- 高精度(中文): 在7个零样本 CLUE 数据集和5个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
- 快速推理: 首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理。
- 可复现性: 所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
- 跨平台: 支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。

官方实例
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
本地部署
1.下载代码
git clone https://github.com/THUDM/ChatGLM-6B.git
2.通过conda创建虚拟环境
# 新建chatglm环境
conda create -n chatglm python=3.8
# 激活chatglm环境
conda activate chatglm
# 安装PyTorch环境(根据自己的cuda版本选择合适的torch版本)
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# 安装gradio用于启动图形化web界面
pip install gradio
# 安装运行依赖
pip install -r requirement.txt
3.修改代码
- 在web_demo.py的最后一句demo.queue().launch(share=True),加两个server_name=“0.0.0.0”, server_port=1234参数。
demo.queue().launch(share=True,server_name="0.0.0.0",server_port=9234)
4.模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
- GPU
# FP16精度加载,需要13G显存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
# int8精度加载,需要10G显存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(8).cuda()
# int4精度加载,需要6G显存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
- CPU
#32G内存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
#16G内存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).bfloat16()
5.详细代码
from transformers import AutoModel, AutoTokenizer
import gradio as gr
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
# model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
model = model.eval()
MAX_TURNS = 20
MAX_BOXES = MAX_TURNS * 2
def predict(input, history=[]):
response, history = model.chat(tokenizer, input, history)
updates = []
for query, response in history:
updates.append(gr.update(visible=True, value=query))
updates.append(gr.update(visible=True, value=response))
if len(updates) < MAX_BOXES:
updates = updates + [gr.Textbox.update(visible=False)] * (MAX_BOXES - len(updates))
return [history] + updates
with gr.Blocks() as demo:
state = gr.State([])
text_boxes = []
for i in range(MAX_BOXES):
if i % 2 == 0:
label = "提问:"
else:
label = "回复:"
text_boxes.append(gr.Textbox(visible=False, label=label))
with gr.Row():
with gr.Column(scale=4):
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
with gr.Column(scale=1):
button = gr.Button("Generate")
button.click(predict, [txt, state], [state] + text_boxes)
demo.queue().launch(share=True,server_name="0.0.0.0",server_port=9234)
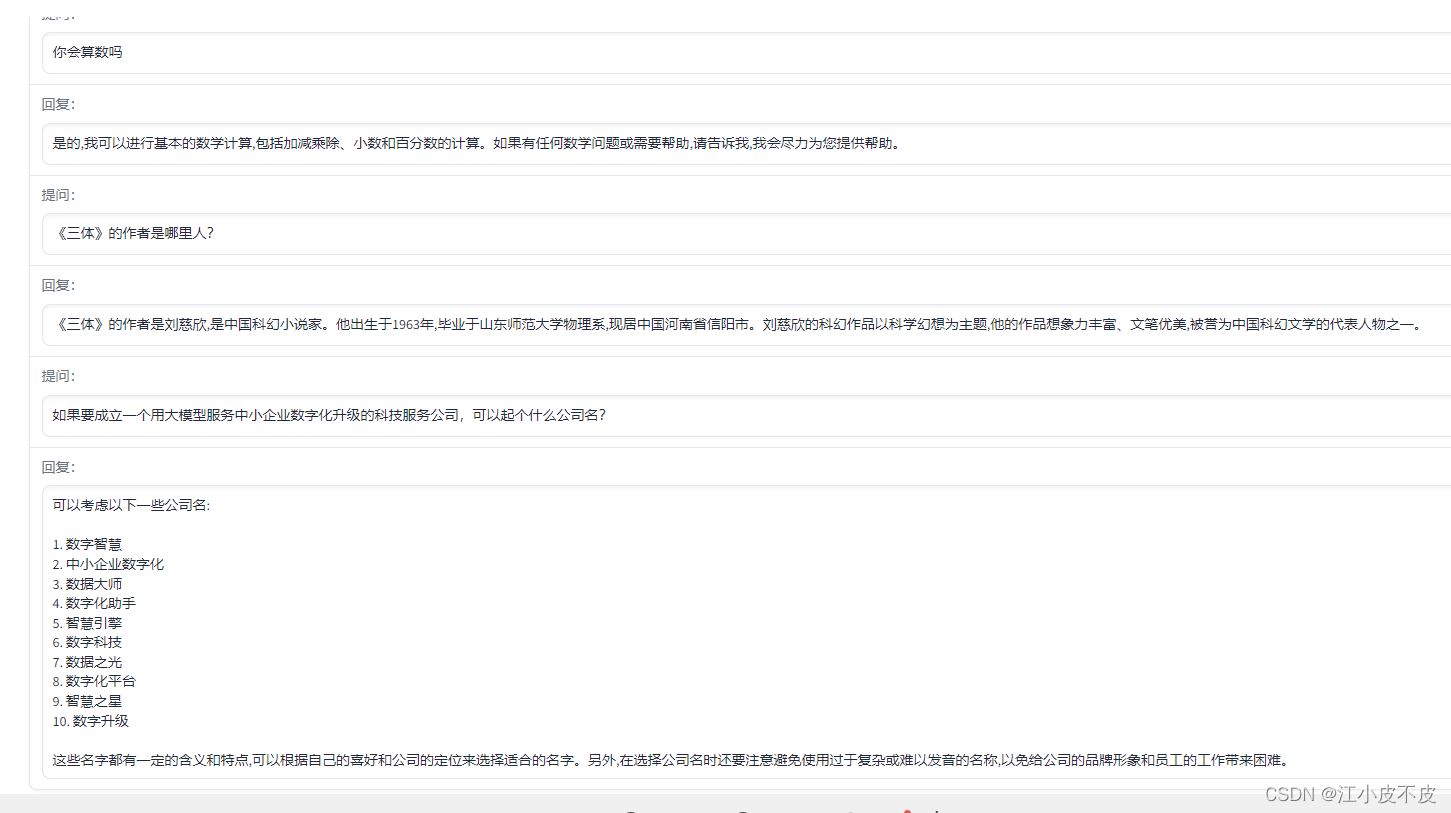
调用示例

本文转载自: https://blog.csdn.net/qq128252/article/details/129625046
版权归原作者 江小皮不皮 所有, 如有侵权,请联系我们删除。
版权归原作者 江小皮不皮 所有, 如有侵权,请联系我们删除。