
🧠思维导图
📒前言
2022年11月30日,美国人工智能研究公司OpenAI发布全新的聊天机器人模型ChatGPT。上线仅五天,用户数量就突破100万人。2023年,大语言模型及其在人工智能领域的应用已成为全球科技研究的热点,其在规模上的增长尤为引人注目,参数量已从最初的十几亿跃升到如今的一万亿。
其实,早在20世纪70年代,人工智能(Artificial Intelligence,AI)就被称为世界三大尖端技术之一(空间技术、能源技术、人工智能)。然而,对于人工智能的定义却从未得到一个统一的答案。“智能”一词,涉及到“意识”,“自我”,“思维”等问题。但是由于生物技术的限制,使得人类对于脑工作原理尚且处于探索阶段。我们对我们自身智能的理解非常有限,对构成人的智能的必要元素也了解有限,所以就很难定义什么是“人工智能”。
不过幸运的是,研究者通过对人脑神经元结构的模拟,设计出神经网络模型。他们将神经元数学化,产生神经元数学模型。对高级语义和复杂图像处理找到了合适的解决方案。
对于和作者一样的大学生来讲,AI不仅是全能的答疑助手,还是解救无数男生的情感大师,甚至可能是无数论文的真正作者。
相信大家都急于探寻它们背后的奥秘了吧!请大家不要着急,本篇文章就为大家讲解AI家族背后鲜为人知的秘密。
人工智能(ArtificialIntelligence,AI)是最宽泛的概念,是研发用于模拟、延伸和扩展人的智能的理论、方法、 技术及应用系统的一门新的技术科学。但是前言中提到过,“人工智能”一词至今尚未有一个准确的定义。这个定义也只阐述了目标,而没有限定方法。
机器学习(MachineLearning,ML)是当前比较有效的一种实现人工智能的方式。主要分为符号机器学习和统计机器学习。符号机器学习是基于逻辑推理和符号表示的学习方法,统计机器学习是基于概率推理的学习方法。在人工智能发展初期,机器学习的主流还是符号机器学习,以离散方法处理问题。但从1990年代开始,统计机器学习横空出世,以连续方法处理问题。不过,大家对于这两个概念仅作了解即可,现阶段不必做深入探究。
深度学习(DeepLearning,DL)是机器学习领域中一个新的研究方向。它通过学习样本数据的内在规律和表示层次,让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
简而言之,这三者的关系是:人工智能 > 机器学习 > 深度学习
机器学习致力于研究如何通过计算手段,利用经验来改善系统自身性能。在计算机系统中,“经验”以“数据”的方式存在,而“经历”就是“数据集”。机器学习的主要内容是计算机通过对数据的处理和分析,从而产生模型的算法,也被称作“学习方法”。
通过对足够的数据进行学习,计算机产生一个模型。当我们对计算机提供新的一组数据时,计算机便能根据原有的模型提供相应的判断。
说起来可能有点深奥,举个简单的例子。高中阶段我们学过统计的内容中有一个重要的知识点是通过对图表分析,求出线性回归方程,并进行预测。其实这就是机器学习中的典型模型——线性模型。其实计算机和我们的计算方法也大致相同。进行数据处理,通过调参得到一个合适的预测函数(线性回归方程),并且能够进行预测。
1、机器学习的实现原理
机器学习的实现可以分成两步:训练和测试,类似于归纳和演绎。
归纳:从具体案例中抽象一般规律,机器学习中的“训练”亦是如此。通过对一定样本(训练数据)的学习,得到某个特定的表达式(模型)。就像我们做了无数道同类型的题后,总结出相应的答题套路。
演绎:从一般规律推导出具体案例的结果,机器学习中的“测试”亦是如此。通过得出的表达式,计算出新情况的对应结果,如果对应情况与真实情况误差很小或相同,则称模型是有效的。就像我们按照答题套路得出答案,如果答案与标准答案相同,则我们的答题套路是对的。
2、学习任务
根据训练数据是否拥有学习信息,学习任务大致可以分为三类:“监督学习”、“无监督学习”和“强化学习”
监督学习:指使用类别已知(已标记)的训练样本来训练算法,以便对数据进行分类或准确预测结果。
那么标记的训练样本是什么意思呢?它表示数据集具有被标记的信息,这些标签形成了数据属于哪一类对象的表示,帮助机器学习模型在未来遇到从未见过的数据时,能够准确地进行分类和识别。
举个简单的栗子,例如一个班上有50个男生和1个女生,这时有一个同学进入教室,我可以判断这位同学的性别。
无监督学习:指根据类别未知(没有被标记)的训练样本总结出事先未知类别特征,使得学得模型适用于新样本。无监督学习通常适用于以人工标注类别或进行人工类别标注的成本太高的情况。
延续上一个栗子,我事先并不知道这个班上有多少个男生和女生,但是我通过他们的穿着打扮、头发长短等等可以简单判断出他们的性别和比例,并且能够对进入教室的那位同学的性别进行判断。
监督学习的代表是分类和回归,无监督学习的代表是聚类。
分类是已知类别特征进行的分离不同类别,而聚类是在未知类别特征的情况下,根据自主总结出类别特征将训练集分成若干组,每组称为一个“簇”,每个自动形成的“簇”背后是一些潜在概念。
强化学习:又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
3、确定模型
在“机器学习”的过程中确定模型中有三个关键要素:假设、评价、优化。
假设是指“模型假设”,假设空间(所有可能的函数构成的空间)中圈定范围中确定有一个模型能够表达的关系可能,机器还会进一步在假设圈定的范围内寻找最优的自变量和因变量的关系,即确定参数。
评价是指“评价函数”,寻找最优之前,我们需要先定义什么是最优,即评价两个变量之间关系的好坏的指标。通常衡量该 关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。在评价函数中,我们通常使用损失函数(Loss)作为衡量模型预测值和真实值差距的评价函数。
然而,根据NFL定理(No Free lunch没有免费午餐定理),我们要谈论算法的相对优劣,必须要针对具体学习问题具体讨论。
优化是指“优化算法”,设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小/最拟合已有观测样本)的变量关系找出来,这个寻找最优解的方法即为优化算法。最简单也最麻烦的优化算法是不停计算每一个可能参数值对应的损失函数,从而找到最优解。
讲解了传统的机器学习方法,我们讲一讲当代机器学习领域的新研究方向——深度学习。
首先,相比于传统机器学习,深度学习又有何改进呢?虽然两者在理论结构上是一致的,即模型假设、 评价函数和优化算法,但其根本差别在于假设的复杂度。
举个栗子,一位老师想让计算机帮他选出班上一位“三好学生”,要求品德好、学习好、身体好。学习和身体的评价指标可以使用成绩单和体检报告进行简单评估。但是“品德”却是一种高级语义。这样的概念上升到一种道德标准,不仅评价方法多种多样,评价数据规模也是难以想象的。对计算机而言,只能接收到一个数字矩阵。如果这时候老师还是选择传统机器学习方法,那么老师的电脑在得出答案之前就已经冒烟了。
因此研究者们借鉴了人脑神经元的结构,设计出神经网络模型。
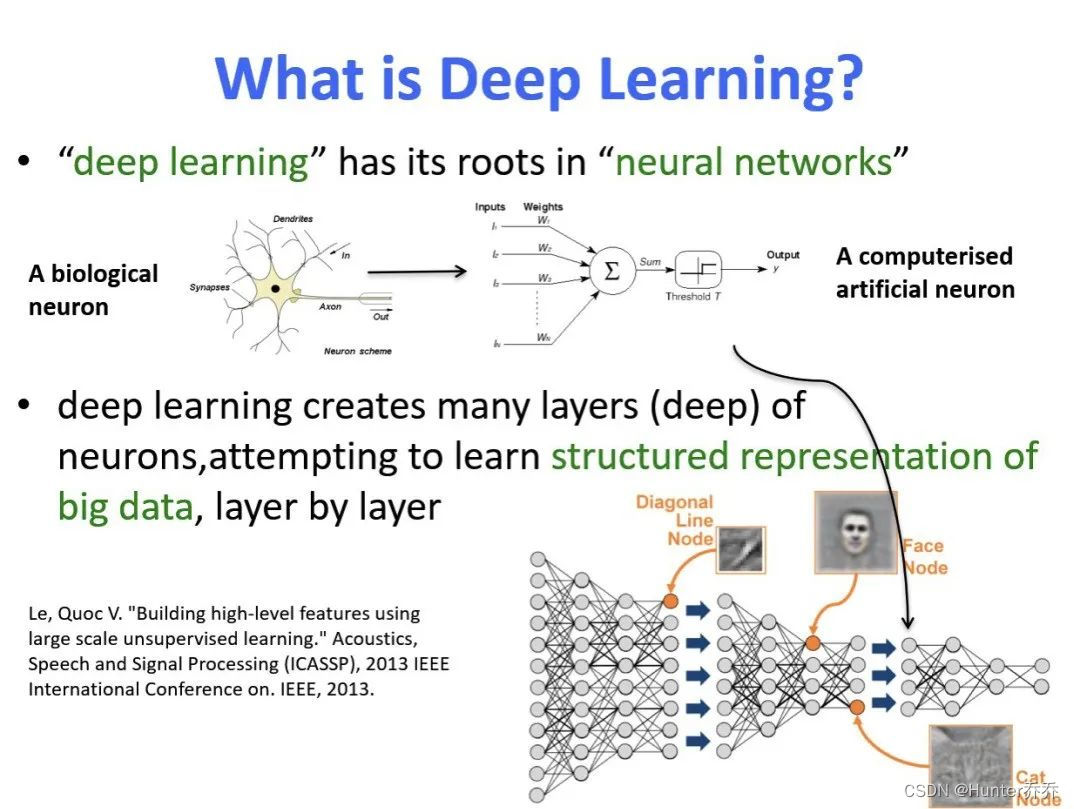
1、神经网络
神经元: 神经网络中每个节点称为神经元,由两部分组成:加权和和非线性变换
加权和:将所有输入加权求和。
非线性变换(激活函数):加权和的结果经过一个非线性函数变换,让神经元计算具备非线性的能 力。
多层连接: 大量这样的节点按照不同的层次排布,形成多层的结构连接起来,即称为神经网络。 前向计算: 从输入计算输出的过程,顺序从网络前至后。
计算图: 以图形化的方式展现神经网络的计算逻辑又称为计算图。
2、深度学习当代发展
目前,深度学习技术在图像识别、语音识别和自然语言处理等领域取得重大突破。深度学习技术在ImageNet图像识别竞赛中多次夺冠。语音识别和自然语言处理方面的成就更不必多讲,有我们熟知的语音助手和ChatGPT。
当然,为了使计算机运作方式更接近人脑的结构,生物计算机也在逐渐被推向时代的风口浪尖,其主要原材料是生物工程技术产生的蛋白质分子,并以此作为生物芯片来替代半导体硅片,利用有机化合物存储数据。运算速度要比当今最新一代计算机快10万倍,它具有很强的抗电磁干扰能力,并能彻底消除电路间的干扰。
然而,无法否认的是,“过拟合化”和“泛化能力差”是深度学习面临的两大致命难题。“泛化能力”指学得模型适用于新样本的能力。“过拟合化”指把训练样本自身的一些特点当作所有潜在样本都会具有的一般特质,会导致泛化能力下降。为攻破这两大难题,更新颖算法和模型(例如迁移模型)会被提出。
四、📚推荐书籍及课程
作者推荐购买书籍并未收取任何广告费用,大家根据自身情况合理购买。《机器学习》和《机器学习方法》是作者在学书籍,其余书籍是参考其他博主文章推荐拓展书籍(原文链接:学习机器学习要看哪些书籍 (baidu.com))
推荐课程均为作者在学免费高质量网课!
1、学习书籍
①《机器学习》(又称西瓜书):作者是南京大学计算机科学与技术系主任,南京大学人工智能学院院长周志华教授,适合初学者和进阶者阅读。这本书全面讲述了机器学习的基本概念、算法和应用,特别是在深度学习方面有详细的介绍。

②《机器学习方法》:作者李航,是另一本国内著名的机器学习经典著作,详细介绍了机器学习中常用的算法,如感知机、决策树、朴素贝叶斯、支持向量机、提升方法和 EM 算法等。

③《Deep Learning》:作者Ian Goodfellow、Yoshua Bengio和Aaron Courville,是一本深度学习领域的经典教材。该书全面介绍了深度学习中的基本概念和原理,包括神经网络、卷积神经网络和循环神经网络等。

④《Python机器学习基础教程》:作者Sebastian Raschka和Vahid Mirjalili,是一本介绍机器学习基本概念和Python编程实现的入门书籍。该书涵盖了机器学习的主要算法和Python中的数据处理和可视化技术,适合初学者入门。

⑤《机器学习实战》:作者Peter Harrington,是一本以实例为导向的机器学习教材。该书详细介绍了各种机器学习算法的实现和应用,包括 kNN、决策树、朴素贝叶斯、支持向量机和神经网等。

2、推荐课程
周志华教授亲讲《机器学习》:机器学习初步 - 南京大学 - 学堂在线 (xuetangx.com)
百度飞桨《零基础实践深度学习》:飞桨AI Studio星河社区 - 人工智能学习与实训社区 (baidu.com)
📝总结
本篇内容主要讲解了人工智能、机器学习、深度学习三者的概念和定义,也为大家解释了一些基本术语。想必现在大家看似深奥的人工智能背后的工作原理也有了基本认知。不过有一些概念的确难以理解,这属于很正常的现象。这需要长时间的学习消化加上个人理解。
虽然早在上世纪50年代,“人工智能”这个概念就伴随着“计算机”同时被提出,但是由于计算机技术的限制,人工智能到了本世纪才开始蓬勃发展。直到今天,“人工智能”仍然是一门界限模糊不清的学科。其原因不仅是研究人员对于人脑工作原理还在研究和探索,也包括一些与人类道德伦理相关的问题。
据路透社2023年3月28日报道,包括马斯克、苹果联合创始人斯蒂夫·沃兹尼亚克在内的1000多名人工智能专家和行业高管签署了一份公开信,他们呼吁将AI系统的训练暂停六个月,理由是对社会和人性存在潜在风险。
人工智能技术飞速发展是福是祸?人工智能的终点是造福还是毁灭?这些问题都有待进一步讨论。
另外,作者通过各种渠道现在可以使用谷歌号称该公司“规模最大、功能最强”的人工智能模型“双子座(Gemini)”。那么如果Gemini遇到当今一些伦理学领域知名难题时,会给出怎样的答案呢?大家可以期待一下!测试结果仅作参考,切勿用作学术用途。
下一章我们将学习“模型评估与选择”,让大家对于机器学习“评价”这一环节有更加深刻的认识。
由于作者时间有限,每篇内容也需花费较多时间撰写,后续内容将不定期更新,记得关注哦~
如果发现文章中表述存在错误或有疑问,欢迎私信作者或者在评论区留言~
版权归原作者 Hunter乔乔 所有, 如有侵权,请联系我们删除。