
介绍:
XGBoost整体思想就是直接把损失函数和正则项加起来合成一个整体的损失函数,对这个损失函数求二阶导,得到最终的obj,通过obj计算得到一个分数,这个分数越小越好,最终通过obj计算得到的分数确定了树的结构和整个强学习器的分数。所以XGBoost不是通过拟合残差实现的,而是计算obj函数直接得到的树结构。

基于Boosting(梯度提升)思想,利用梯度下降思想,XGBoost在机器学习里面所有算法里面算效果很好的了,对于很多竞赛,都是用XGBoost获得了很好的名词,XGboost中所有的树都是二叉树,以CART树算法作为主流。
对于回归树:预测结果会落在每片叶子上,回归树会将叶子上的数值求平均就是这片叶子结点的回归结果。
对于分类树:最终类别号会落在每篇叶子上,叶子会遵循少数服从多数的结果,给出最终预测结果。
对于梯度提升树来说,整体思想就是将每棵树的预测结果加权后将所有的树分值求和就是这个样本在整个继承算法上的预测结果。

对于xgboost来说
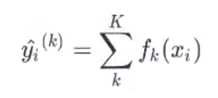
基于树的集成学习优点:
基于树的集成学习不用做特征归一化,使用起来非常方便。
基于树的集成学习可以做到特征组合,不用自己做升维。
集成学习可以做大规模数据并行处理。使得训练过程更快。
目标有两个部分组成
Train Loss:评估训练数据拟合的多好
Regularization:正则项,提高模型的泛化能力,能够更好的再测试集或者预测集预测的更准确。
我们要去优化这个目标函数。
GBDT并没有考虑模型的复杂度,XGBoost有考虑模型的复杂度,加入了正则项。
我们希望训练的模型即有最少的loss也有比较好的泛化能力。
对于每棵树来说我们要求树的结构和叶子节点分值。
基于树的目标函数
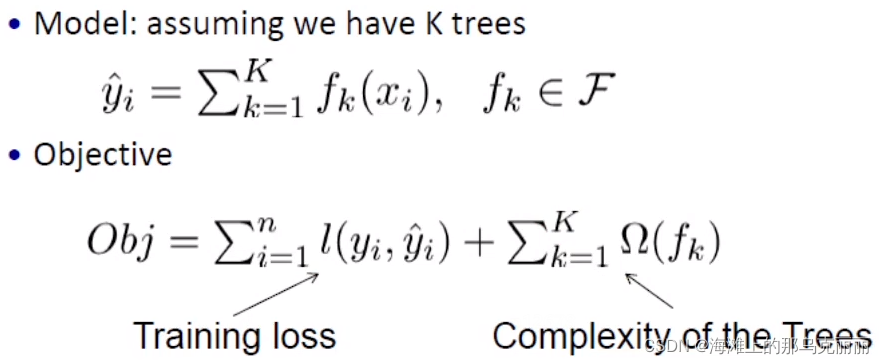
基于树的集成学习,我们没有W参数,但是也有要求的参数,就是树的结构和叶子结点的分值。
对于正则项,我们希望参数W越小越好,那么体现在树的结构上就是希望树的结构和叶子结点的分值越小越好(越小越能提高泛化能力)。
不管做什么业务分类还是回归,我们都可以用回归树。
目标式和启发式
启发式:
(1)对每个叶子节点分类的时候用的信息增益。
(2)剪枝(前剪枝,后剪枝)。
(3)树的最大深度,限制树的增长相当于限制树的范围。
(4)缩小叶子的分值。
XGBoost采用目标式:
目标式(比较直观,通过obj目标函数可以直观地看到我们要学的是什么)
(1)分裂的指标改成traning loss
(2)剪枝-->通过设置正则项控制剪枝。
(3)树的最大深度-->通过控制函数空间。
(4)平滑叶子结点的分值-->L2正则项放到叶子节点。
xgboost库介绍
使用XGboost我们通常有两个库,一个是xgboost库,一个是sklearn里面封装的XGboost类。
xgboost库建模流程:

sklearn:xgb.XGBRegressor()
参数:

n_estimators(树的数量):默认是100
在我们调参过程中发现,当我们的树数量很少的时候,树的数量对模型影响非常大,但是当树的数量达到一定的数量之后,对模型的效果就是一条直线,分数不会再有较大的提高。
所以当树的数量达到一个合理值后,在徒劳的增加树的数量是不会再有效的,只会增加计算量。
所以XGBoost和随机森林不一样不能盲从的相信n_estimators这个参数,一般这个参数不要调的太大,300一下最佳(结合学习曲线)。
slient:是否打印每次训练过程,默认False
xgboost:xhgb.train()
subsample随机抽样的参数:
XGBoost控制随机抽样的参数,默认是1,也就是说默认是100%抽样,对于较大的数据集,我们可以调整这个参数进行抽样,但是对于较少的数据量如果还要进行随机抽样的话,就有可能让模型因为数据量太少而学习不到较好的参数,所以这样的情况我们选择不适用这个参数。
eta:xgboost(eta),sklearn(learning_rate)决策树的步长,梯度下降的学习率
取值范围[0,1]
η用来控制迭代步长,η越大迭代速度越快,算法很快就能达到极限,但有可能无法收敛到最佳。
η越小迭代速度越慢,但有可能熟练不到最佳值。
我们要找的就是最快效果也是最好的值。
通常我们调整η主要是用来调整运行时间,一般简单调整一下步长就实现收敛,调整树模型效果主要还是用剪枝等操作。
XGBoost在设计时使其不仅可以使用树模型,还可以使用其他模型
booster控制我们究竟选择怎样的弱评估器。(在XGBoost中不是很常用)
gbtree:梯度提升树
gblinear:使用线性模型,线性模型,只有数据是线性的时候,才使用这个。
dart:抛弃提升树,在建树的过程中抛弃一部份树,比梯度提升书有更好的防止过拟合的功能。
# 使用波士顿房价数据集,发现gblinear这个弱评估器分数不高,也说明波士顿房价特征并不是线性的数据
for booster in ["gblinear", "gbtree", "dart"]:
reg = XGBRegressor(n_estimators=100,
learning_rate=0.1,
random_state=10,
booster=booster).fit(X_train, y_train)
print(booster)
print(reg.score(X_test, y_test))
gblinear
0.5462737865128029
gbtree
0.831708286367204
dart
0.8317082711597155
Objective:XGBoost损失函数

linear:均方误差作为损失函数
logistic:log_loss二分类
hinge:支持向量机二分类
multi:softmax多分类
也可以自定义损失函数
正则化系数对应的参数
reg_alpha:L1正则默认0
reg_lambda:L2正则默认1
所以XGboost默认使用L2正则化
gamma:让树停止生长的重要参数,默认是0
在XGBoost中,只要分数之差Gain大于0,目标函数就能继续减小,我们就允许树继续分支。
所以有
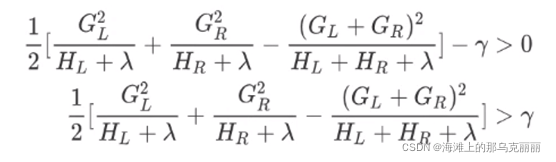
我们对gamma设置某个值,就是对Gain分支进行限制。
所以gamma设置越大,树的复杂度就越低。但是也不能过低,过低的话有可能就无法充分学习。
xgboost.cv:XGboost自带的用于交叉验证的类
from xgboost import XGBRegressor
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.datasets import load_boston # y是回归类型的变量,所以用来做分类
from sklearn.metrics import mean_squared_error # 模型评估指标
from sklearn.feature_selection import SelectFromModel # 嵌入法选择特征
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import ShuffleSplit, learning_curve, KFold
data = load_boston()
X = data.data
y = data.target
def XGb_test():
# 特征选择,xgboost是可以自己选择特征的,但是如果特征过多也可以使用嵌入发进行选择特征。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=20)
"""
reg = XGBRegressor(n_estimators=100).fit(X_train, y_train)
y_predict = reg.predict(X_test)
print(reg.score(X_test, y_test)) # 用R平方做回归指标
print(reg.feature_importances_)
print(mean_squared_error(y_predict, y_test)) # 用均方误差做回归指标
"""
"""
# XGboost使用交叉验证
reg = XGBRegressor(n_estimators=100, silent=True)
score_xgb = cross_val_score(reg, X, y).mean()
print(score_xgb)
# 随机森林使用交叉验证
rfr = RandomForestRegressor(n_estimators=100)
score_rfr = cross_val_score(rfr, X, y).mean()
print(score_rfr)
# 使用线性回归
lr = LinearRegression()
score_lr = cross_val_score(lr, X, y).mean()
print(score_lr)
# 0.6460769617602883 xgboost
# 0.615660483359535 随机森林
# 0.3532759243958772 线性回归
"""
# 画出学习曲线
def study_curve(estimator, X, y, cv, title, ax=None, ylim=None, n_jobs=None):
train_sizes_abs, train_score, test_score = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs)
if ax is not None:
ax.set_title(title)
if ylim is not None:
ax.set_ylim(*ylim)
ax.set_xlabel("train_samples")
ax.set_ylabel("score")
ax.grid()
ax.plot(train_sizes_abs, np.mean(train_score, axis=1), 'o-', color='r', label="train_score")
ax.plot(train_sizes_abs, np.mean(test_score, axis=1), 'o-', color='r', label="test_score")
ax.legend()
else:
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("train_samples")
plt.ylabel("score")
plt.grid()
plt.plot(train_sizes_abs, np.mean(train_score, axis=1), 'o-', color='r', label="train_score")
plt.plot(train_sizes_abs, np.mean(test_score, axis=1), 'o-', color='g', label="test_score")
plt.legend()
"""
if ax == None:
ax = plt.gca()
else:
ax = plt.figure()
ax.set_title(title)
if ylim is not None:
ax.set_ylim(*ylim)
ax.set_xlabel("train_samples")
ax.set_ylabel("score")
ax.grid()
ax.plot(train_sizes_abs, np.mean(train_score, axis=1), 'o-', color='r', label="train_score")
ax.plot(train_sizes_abs, np.mean(test_score, axis=1), 'o-', color='r', label="test_score")
ax.legend()
#return ax
"""
cv = ShuffleSplit(n_splits=50, test_size=0.2, random_state=10)
# fig, axes = plt.subplots(1,1,
# figsize=(10,10))
# cv = KFold(n_splits=5, shuffle=True, random_state=42)
study_curve(XGBRegressor(n_estimators=100), X_train, y_train, cv, title="XGBRegressor", ax=None, ylim=[0.5, 1.2], n_jobs=-1)
plt.show()
def Xgb_curve():
axies = range(1, 1010, 50)
scores = []
# 画出学习曲线找到比较好的n_estimators个数
for i in range(0, 1010, 50):
xgb = XGBRegressor(n_estimators=i)
score = cross_val_score(xgb, X, y, cv=10).mean()
scores.append(score)
plt.figure(figsize=(20, 5))
plt.title("XGBRegressor")
plt.grid()
plt.xlabel("树个数")
plt.ylabel("分数")
plt.plot(range(0, 1010, 50), scores, color='r', label="train_score")
print(axies[scores.index(max(scores))], max(scores))
plt.show()
if __name__ == "__main__":
# XGb_test()
Xgb_curve()
参数:
num_round(树的数量):默认是10
slient:是否打印每次训练过程,默认True
XGBoost剪枝参数
XGBoost作为树模型也是容易过拟合的模型。所以我们需要对XGBoost进行剪枝。
max_depth:最大深度(先调这个参数)除了n_estimators外调的第一个参数。
consample_bylevel:生成树的每一层时随机抽样特征比例。
consample_bynode:每次生成一个叶子节点时随机抽样特征比例。
**min_child_weight:**叶子节点上的二阶导数之和。
剪枝用的最多的还是gamma和max_depth
XGBoost处理样本不均衡问题
scale_pos_weight:默认是1
应该填写的参数是多数类除以少数类。
总结:
把启发式的步骤统统设计到目标式的函数中。
目标函数是loss加上正则项。
basemodel是回归树,我们要学习的是f1...fk这些小树。
我们希望模型既能准确,又能有一定的泛化能力。
XGboost也是过拟合的模型,所以剪枝也是非常重要的。
版权归原作者 海滩上的那乌克丽丽 所有, 如有侵权,请联系我们删除。