
1.属于监督学习的机器学习算法是:贝叶斯分类器
2.属于无监督学习的机器学习算法是:层次聚类
3.二项式分布的共轭分布是:Beta分布
4.多项式分布的共轭分布是:Dirichlet分布
5.朴素贝叶斯分类器的特点是:假设样本各维属性独立
6.下列方法没有考虑先验分布的是:最大似然估计
7.对于正态密度的贝叶斯分类器,各类协方差矩阵相同时,决策函数为:线性决策函数
8.下列属于线性分类方法的是:感知机
9.下列方法不受数据归一化影响的是:决策树
10.下列分类方法中不会用到梯度下降法的是:最小距离分类器
11.下列方法使用最大似然估计的是:Logistic回归
12.关于线性鉴别分析的描述最准确的是,找到一个投影方向,使得:类内距离最小,类间距离最大
13.SVM的原理的简单描述,可概括为:最大间隔分类
14.SVM的算法性能取决于:以上都有(核函数的选择、核函数的参数、软间隔参数C)
15.支持向量机的对偶问题是:凸二次优化
16.以下对支持向量机中的支撑向量描述正确的是:最大间隔支撑面上的向量
17.假定你使用阶数为2的线性核SVM,将模型应用到实际数据集上后,其训练准确率和测试准确率均为100%。现在增加模型复杂度(增加核函数的阶),会发生以下哪种情况:过拟合
18.避免直接的复杂非线性变换,采用线性手段实现非线性学习的方法是:核函数方法
19.关于决策树节点划分指标描述正确的是:信息增益越大越好
20.以下描述中,属于决策树策略的是:最大信息增益
21.集成学习中基分类器的选择如何,学习效率通常越好:分类器多样,差异大
22.集成学习中,每个基分类器的正确率的最低要求:50%以上
23.下面属于Bagging方法的特点是:构造训练集时采用Bootstraping的方式
24.下面属于Bagging方法的特点是:构造训练集时采用Bootstraping的方式
25.随机森林方法属于:Bagging方法
26.假定有一个数据集S,但该数据集有很多误差,采用软间隔SVM训练,阈值为C,如果C的值很小,以下哪种说法正确:会发生误分类现象
27.软间隔SVM的阈值趋于无穷,下面哪种说法正确:只要最佳分类超平面存在,它就能将所有数据全部正确分类
28.一般,K-NN最近邻方法在什么情况下效果好:样本较少但典型性较好
29.回归问题和分类问题的区别:前者预测函数值为连续值,后者为离散值
30.最小二乘回归方法的等效回归方法:线性均值和正态误差的最大似然回归
31.正则化的回归分析,可以避免:过拟合
32.“啤酒-纸尿布”问题讲述的是,超市购物中,通过分析购物单发现,买了纸尿布的男士,往往又买了啤酒。这是一个什么问题:关联分析
33.KL散度是根据什么构造的可分性判据:类概率密度
34.密度聚类方法充分考虑了样本间的什么关系:密度可达
35.混合高斯聚类中,运用了以下哪种过程:EM算法
36.主成分分析是一种什么方法:降维方法
37.PCA在做降维处理时,优先选取哪些特征:中心化样本的协方差矩阵的最大特征值对应特征向量
38.过拟合现象中:训练样本的测试误差最小,测试样本的正确识别率却很低
39.如右图所示有向图,节点G的马尔可夫毯为:**{D,E,F,H,I,J}**
40.如右图所示无向图,节点G的马尔可夫毯为:**{D,E,I,J}**
41.多层感知机方法中,可用作神经元的非线性激活函数:Logistic函数
42.在有限支撑集上,下面分布的熵最大:均匀分布
43.已知均值和方差,下面哪种分布的熵最大:高斯分布
44.以下模型中属于概率图模型的是:受限玻尔兹曼机
45.如右图所示有向图,以下陈述正确的有:B和G关于{C,F}条件独立
46.在标准化公式中,使用的目的是:防止分母为零
47.梯度下降算法的正确步骤是什么:4,3,1,5,2 (初始化-输入-计算误差-改变权重以减小误差-迭代更新)
(1)计算预测值和真实值之间的误差
(2)迭代跟新,直到找到最佳权重
(3)把输入传入网络,得到输出值
(4)初始化随机权重和偏差
(5)对每一个产生误差的神经元,改变相应的(权重)值以减小误差
48.假如使用一个较复杂的回归模型来拟合样本数据,使用岭回归,调试正则化参数,来降低模型复杂度。若λ较大时,关于偏差和方差,下列说法正确的是:若****λ较大时,偏差减小,方差减小
49.以下哪种方法会增加模型的欠拟合风险:数据增强
50.以下说法正确的是:除了EM算法,梯度下降也可求混合高斯模型的参数
51.在训练神经网络时,如果出现训练error过高,下列哪种方法不能大幅度降低训练error:增加训练数据
52.以下哪种激活函数可以导致梯度消失:Tanh
53.增加以下哪些超参数可能导致随机森林模型过拟合数据:(2)决策树的深度
54.以下关于深度网络训练的说法正确的是:D
A.训练过程需要用到梯度,梯度衡量了损失函数相对于模型参数的变化率
B.损失函数衡量了模型预测结果与真实值之间的差异
C.训练过程基于一种叫做反向传播的技术
D.其他选项都正确
55.以下哪一项在神经网络中引入了非线性:ReLU
56.在线性回归中使用正则项,你发现解的不少coefficient都是0,则这个正则项可能是:
**L0-norm**、**L1-norm**
57.关于CNN,以下结论正确的是:Pooling层用于减少图片的空间分辨率
58.关于k-means算法,正确的描述是:初始值不同,最终结果可能不同
59.下列关于过拟合现象的描述中,哪个是正确的:训练误差小,测试误差大
60.以下关于卷积神经网络,说法正确的是:卷积神经网络可以有多个卷积核,可以不同大小
61.LR模型的损失函数是:交叉熵
62.GRU和LSTM的说法正确的是:GRU的参数比LSTM的参数少
63.以下方法不可以用于特征降维的有:Monte Carlo method
64.下列哪个函数不可以做激活函数:y=2x
65.有两个样本点,第一个点为正样本,它的特征向量是(0,-1);第二个点为负样本,它的特征向量是(2,3),从这两个样本点组成的训练集构建一个线性SVM分类器的分类面方程是:x+2y=3
66.在其他条件不变的前提下,以下哪种做法容易引起机器学习中的过拟合问题:SVM算法中使用高斯核代替线性核
67.下方法中属于无监督学习算法的是:K-Means聚类
68.Bootstrap数据是什么意思:有放回地从总共N个样本中抽样n个样本
69.下面关于贝叶斯分类器描述错误的是:是基于后验概率,推导出先验概率
70.下面关于Adaboost算法的描述中,错误的是:同时独立地学习多个弱分类器
71.以下机器学习中,在数据预处理时,不需要考虑归一化处理的是:树形模型
72.二分类任务中,有三个分类器h1,h2,h3,三个测试样本x1,x2,x3。假设1表示分类结果正确,0表示错误,h1在x1,x2,x3的结果分别(1,1,0),h2,h3分别为(0,1,1),(1,0,1),按投票法集成三个分类器,下列说法正确的是:集成提高了性能
73.有关机器学习分类算法的Precision和Recall,以下定义中正确的是(假定tp = true positive, tn = true negative, fp = false positive, fn =false negative):Precision= tp / (tp + fp), Recall = tp / (tp + fn)
74.下列哪个不属于常用的文本分类的特征选择算法:主成分分析
75.在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计:极大似然估计
76.以下哪种距离会侧重考虑向量的方向:余弦距离
77.解决隐马模型中预测问题的算法是:维特比算法
78.在Logistic Regression 中,如果同时加入L1和L2范数,会产生什么效果:可以做特征选择,并在一定程度上防止过拟合
79.普通反向传播算法和随时间的反向传播算法(BPTT)有什么技术上的不同:与普通反向传播不同的是,BPTT会在每个时间步长内叠加所有对应权重的梯度
80.梯度爆炸问题是指在训练深度神经网络的时候,梯度变得过大而损失函数变为无穷。在RNN中,下面哪种方法可以较好地处理梯度爆炸问题:梯度裁剪
81.当训练一个神经网络来作图像识别任务时,通常会绘制一张训练集误差和验证集误差图来进行调试。在下图中,最好在哪个时间停止训练:C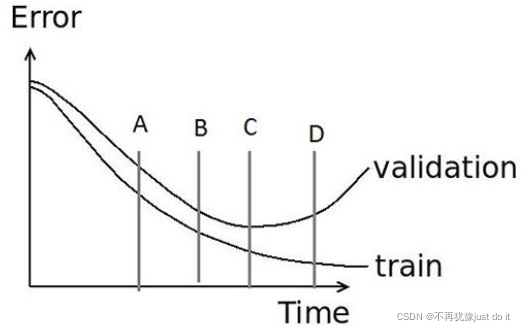
版权归原作者 不再犹豫just do it 所有, 如有侵权,请联系我们删除。