
论文阅读笔记:Vision Transformer
前言
在视觉领域,注意力要么和卷积网络结合使用如上篇博客提到的DETR,要么替换卷积网络中的某些部分,同时保持整体结构不变。本文表明对CNNs的依赖不是必要的,纯转换器(pure transformer)直接应用于图像块(image patches)序列在图像分类任务中能发挥很好的作用。
当对大量数据进行预训练并把它转移到多个中型或者小型图像识别基准(ImageNet,CIFAR-100,VTAB,etc.)中,与SOTA卷积网络相比,Vision Transformer(ViT)获得了出色的结果,同时训练时需要更少的计算资源。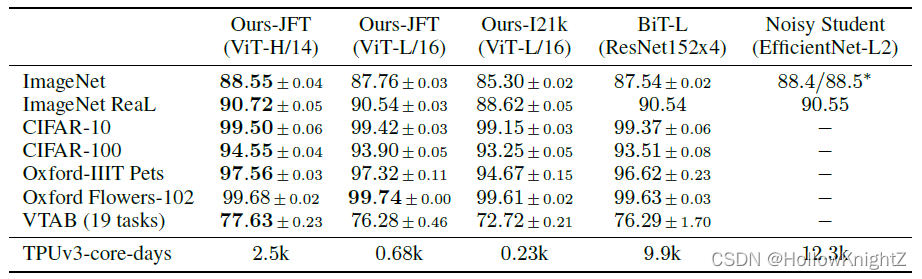
Transformer介绍博客:论文阅读笔记:Attention Is All You Need
DETR介绍博客:论文阅读笔记:End-to-End Object Detection with Transformers
论文原文:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
代码下载地址:GitHub - google-research/vision_transformer
VIT模型
Vision Transformer(ViT)的模型框架如图: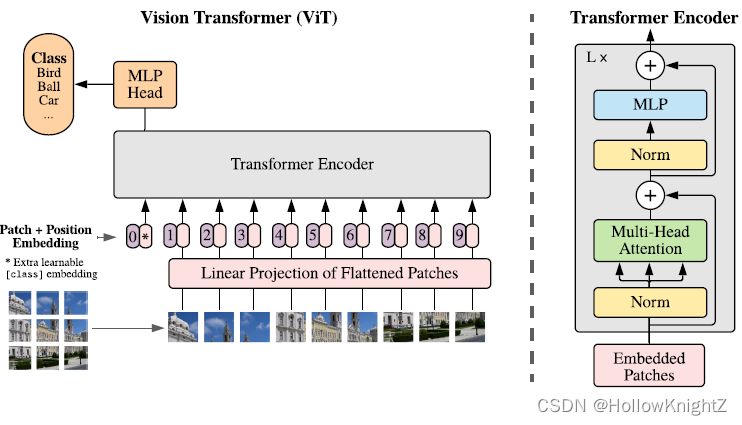
模型由三个模块组成:
· Linear Projection of Flattened Patches
· Transformer Encoder
· MLP Head
Linear Projection of Flattened Patches
标准的Transformer是把token embeddings的1维序列作为输入。为了处理2维的图像,需要把
H
×
W
×
C
H×W×C
H×W×C 的图像转换成
N
×
(
P
2
C
)
N×(P^2C)
N×(P2C) 的patch,
(
H
,
W
)
(H,W)
(H,W)为原始图像的分辨率,
C
C
C 为通道数,
(
P
,
P
)
(P,P)
(P,P)是图像块的分辨率,N是patch数,也是Transformer有效输入序列长度。
如下图,以ViT-B/16(P=16)为例举例说明,输入
48
×
48
×
3
48×48×3
48×48×3的图像,每个patch的大小为
16
×
16
×
3
16×16×3
16×16×3,所以会划分得到
N
=
(
48
/
16
)
∗
(
48
/
16
)
=
9
N = (48/16)*(48/16)=9
N=(48/16)∗(48/16)=9个patch。
[48,48,3] => [9,16,16,3]
接着,将9个[16,16,3]大小的patch通过类似于transformer的input embeding层,将每个patch映射成为一维token向量。
[9,16,16,3] => [9,768]
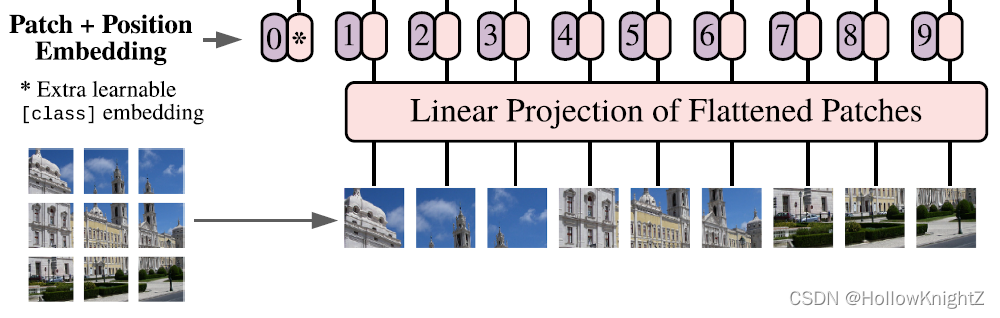
patch线性映射关系如下:
其中E是
N
×
(
P
2
C
)
N×(P^2C)
N×(P2C)大小的patch,通过
x
p
i
x_p^i
xpi的线性映射,再在输入Transformer Encoder之前在序列前添加一个可学习的[class]token(公式(1)中的
x
c
l
a
s
s
x_{class}
xclass,结构图中的
“
∗
”
“*”
“∗”,
concate([1,768],[9,768]]) => [10,768]
)其在Transformer编码器输出端的状态作为图像表示y(公式(4))。最后加上Position Embedding(公式(1)中的
E
p
o
s
E_{pos}
Epos,结构图中的
“
0
,
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
”
“0,1,2,3,4,5,6,7,8,9”
“0,1,2,3,4,5,6,7,8,9”,
E
c
l
a
s
s
,
p
a
t
c
h
+
E
p
o
s
E_{class,patch}+E_{pos}
Eclass,patch+Epos)。可以看到这里的Position Embedding不是之前self-transformer中使用的sin/cos得到的,而是是一维的位置编码。

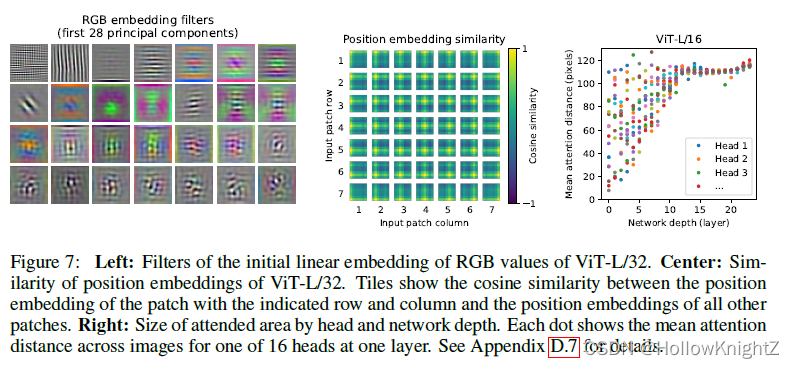
论文后续的分析部分也进行了展示,分别不使用Pos.Emb.、使用1-D Pos.Emb.、2-D Pos.Emb.以及相对Pos.Emb.,实验发现不使用Position Embedding和使用Position Embedding相差3%的精度,而使用什么方式的Position Embedding对结果影响不大。故这里直接使用了1-D Position Embedding。
Transformer Encoder

Transformer编码器包括L层Muti-head Attention块和MLP块(公式(2),(3)),LN(LayerNormalization)应用于每个区块之前,以及每个区块之后的剩余连接(对于这块可查看之前的博文论文阅读笔记:Attention Is All You Need中的Encoder和Layer Normalization)。MLP块包含两层,全连接+GELU激活函数。

具体结构,后续会通过阅读VIT源码进行解析。
MLP Head
Transformer Encoder后输出的shape和输入的shape是保持不变的。最终如公式(4)所示,只需要提取出[class]token生成的对应结果
z
L
0
z_L^0
zL0 进行LN(Layer Normalization),然后通过MLP Head即可。
论文中提到:
即Transformer model的output最后会通过一个 MLP+tanh激活函数(单个隐藏层中)来进行分类。说明MLP Head是由Linear + tanh + Linear。
SELF-SUPERVISION
论文中提到使用了自监督学习,不过通过自我监督预训练,较小的ViT-B/16模型在ImageNet上实现了79.9%的准确率,与从头开始的训练相比显著提高了2%,但仍落后于监督预训练4%。其中提到了余弦相似性:
余弦相似度是通过测量两个向量内积空间的余弦值来度量它们之间的相似性,尤其适用于任何维度的向量比较中,因此属于高维空间应用较多的机器学习算法。
引用自: 图像基础7 图像分类——余弦相似度
版权归原作者 HollowKnightZ 所有, 如有侵权,请联系我们删除。