
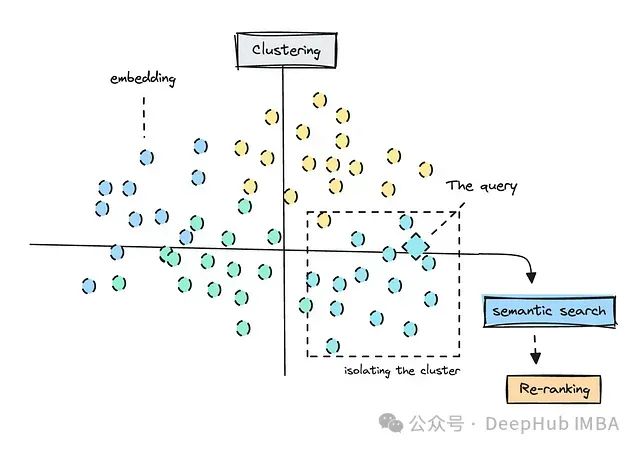
上图为执行语义搜索前的聚类演示 ,嵌入技术是自然语言处理的核心组成部分。虽然嵌入技术的应用范围广泛,但在检索应用中的语义搜索仍是其最常见的用途之一。
尽管知识图谱等可以提升检索的准确率和效率,但标准向量检索技术仍然具有其实用价值。许多文章讨论了如何从语义搜索结果中过滤无关内容,这也是本文将要探讨的主题。我们将使用聚类和重新排序等技术来实现这一目标。
本文的另外一个主要重点是比较不同规模的开源和闭源嵌入模型。
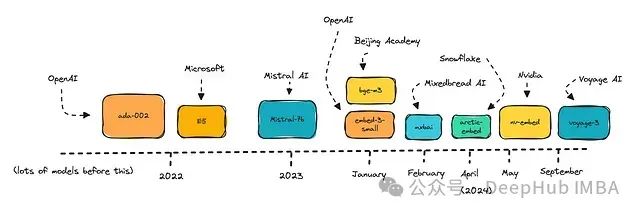
我们将比较MTEB排行榜上排名靠前9种不同嵌入模型。这将帮助你了解大型模型与小型模型的性能差异,以及随着规模扩大可能产生的成本。
如果你曾使用过OpenAI的模型生成嵌入,你可能会好奇它与其他模型的效果对比到底如何呢?
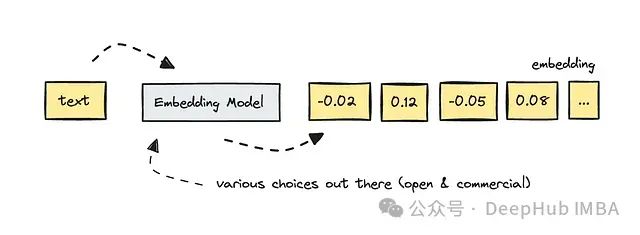
对于不熟悉嵌入概念的读者,这里简要回顾一下:当我们为每段文本创建嵌入(一组向量数组)时,实际上是将文本转换为计算机可以理解的形式。
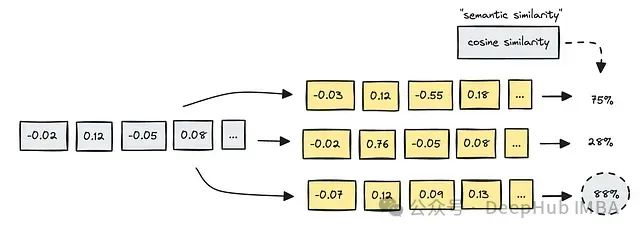
特别是在语义搜索中,我们比较不同文本的嵌入,以确定它们之间的语义相似度。这使我们能够使用查询进行一种模糊搜索——即搜索关系——而不是精确的关键词匹配。
在实际应用中,我们可能需要处理数百万用户的档案,但在本文中,我创建了6,900个合成LinkedIn档案作为示例。
这通常是一个相对简单的用例,因为我们不需要对大型文件中的文档进行分块处理;每个档案都可以作为一个整体处理。此外由于我们容易理解模型是否找到了正确的关系,所以对于可解释性方向也比其他的数据要好很多。
引言
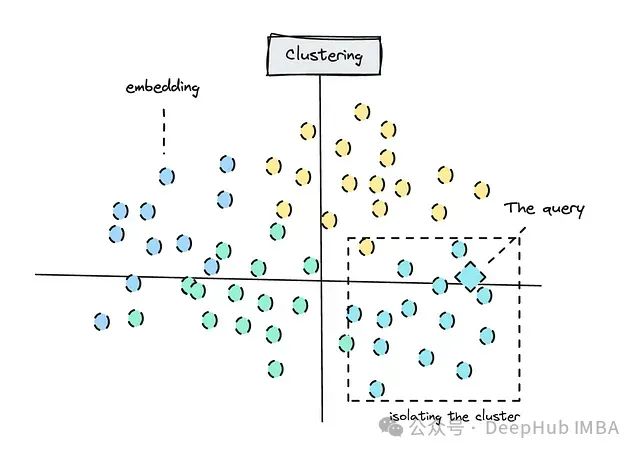
在本文中,由于我们的样本档案数量有限所以可以使用聚类作为整个数据集的无监督分类方法。
以下是聚类的示意图:
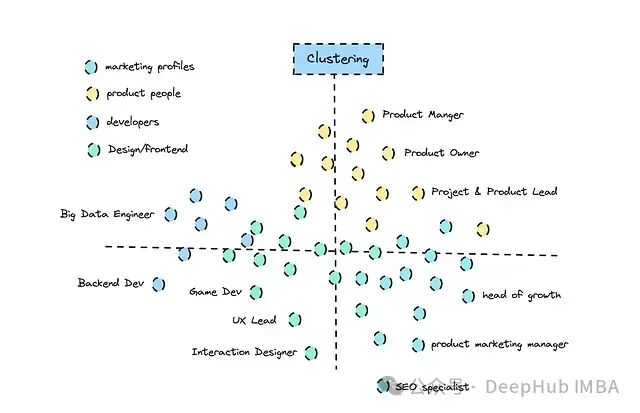
聚类还能帮助我们理解不同模型如何感知相关联的关系。根据所选模型的不同,可以在执行聚类内的语义搜索之前先确定正确的组别。
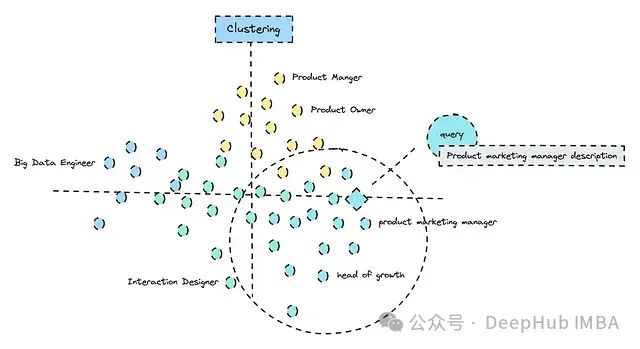
将查询与正确聚类匹配的简化图示 ,这种方法应该能够帮助我们过滤掉不相关的结果,例如模型将产品经理与产品营销经理混淆的情况。
最后一步可以添加使用大语言模型(LLM)进行重新排序,以确保最相关的结果排在前列。
为了简化过程并降低成本,我已经为我们将要评估的每个模型在这个数据集中添加了嵌入,同时也为我们的查询(即匿名职位描述)创建了嵌入。
嵌入
如前所述,嵌入是文本的数值表示,它捕捉了文本的语义含义,使计算机能够处理和理解自然语言。
对于更现代的transformer模型,它们能够理解整个上下文,从而理解词语和句子的多重含义——这在几年前还是无法实现的。
我们可以通过将嵌入表示为几何空间中的点来在图上可视化嵌入。因此嵌入之间的语义关系转化为几何上的接近程度。
不同的模型是为不同的任务而设计的,但大多数较大的模型通用性足够强,可以执行各种任务,如检索、聚类和分类。
语义搜索用于检索,它利用图上的这种接近度来确定查询与其他嵌入的匹配位置,即计算图上嵌入之间的距离。
为了计算语义搜索中嵌入之间的相似度,使用了几种方法,但余弦相似度是最常用的。
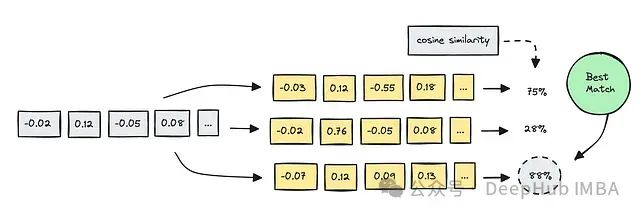
我们使用的模型将直接影响从语义搜索中获得的结果,这是模型训练方式的结果。模型的训练数据集、目标和架构至关重要,因为它们会影响模型理解和链接各种文本的能力。
另一方面,聚类将数据组织成组(或簇),其中同一组内的项目彼此更相似,而与其他组的项目不那么相似。它更擅长识别和匹配嵌入之间的相似性,使我们能够有效地隔离组。
对嵌入进行聚类以分组相似的档案并可视化查询的过程允许我们在执行语义搜索之前首先过滤掉任何不相关的匹配,从而起到降噪的作用。
但是其实并非所有模型都能以我们期望的方式使用聚类;有些模型会表现更好,有些则会表现更差,这取决于它们的构建方式。
嵌入模型
那么如何选择合适的模型呢?这就需要参考MTEB排行榜,它根据模型在各种任务中的表现对嵌入模型进行排名。
我为本文选择了一些模型,包括OpenAI的模型、经过微调的Mistral-7B,以及较小的新模型,如Mixedbread AI的Mxbai。
这些模型大多是在过去两年左右的时间里发布的。
如果你是开源模型的新手,可能会惊讶地发现许多开源模型的排名相当高。即使你不是第一次尝试这些模型,看看哪一个在这个任务中表现最好可能仍然很有趣。
请查看下面的表格,了解每个模型的大小、最大令牌数以及在检索和聚类方面的排名。
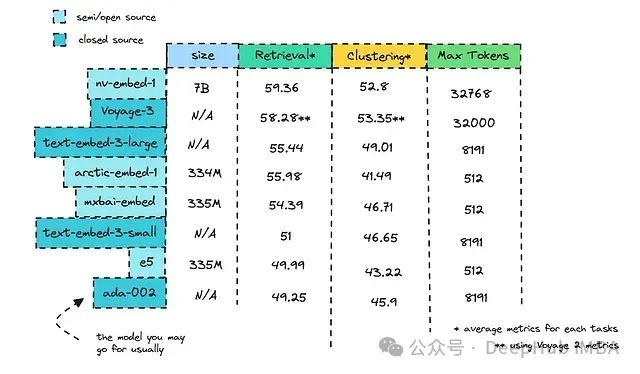
我们将使用的各种模型的MTEB排行榜指标 ,许多人使用过OpenAI的Ada-002,它在我们的列表中排名靠后。然而,OpenAI已经发布了text-embed-3的小型和大型版本,它们表现更好,而且成本更低。
那么,你可能会问,为什么有人会选择使用商业模型,而他们可以使用排行榜上排名靠前的开源模型呢?
开源模型的经济性分析
使用开源模型无疑有其优势,尤其是在隐私保护方面。许多开源模型在性能排行榜上表现出色,但在选择模型时,我们需要权衡托管模型与使用API的经济性。
我比较了在GPU上托管小型(约350M参数)和大型(7B参数)开源模型的成本,以及为几个流行的商业模型按令牌付费的成本。
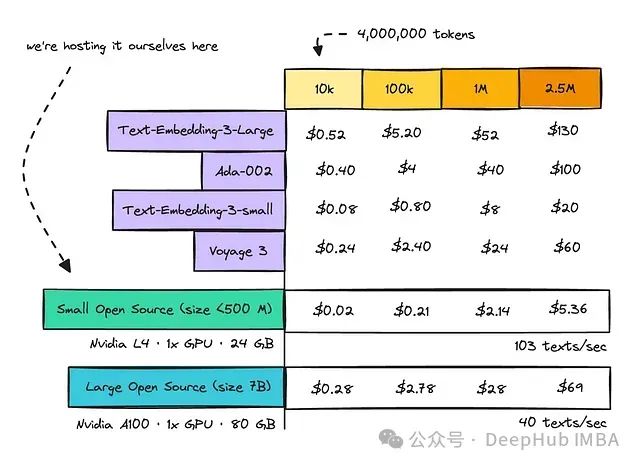
处理10k、100k、1m和2.5m文本的计算成本
这里假设每个文本包含400个令牌,因此334M参数模型在单个L4 GPU上每秒可以处理多达103个文本,而7B参数模型在单个A100上每秒可以处理约40个文本。
从图表中可以看出,一旦开始处理数百万个文本,使用像text-embed-3-large或ada-002这样的模型的成本会急剧增加。
然而,使用小型模型(参数少于500M)通常是最合理的选择。如果可能你应该选择较小的开源模型,因为这可能会将成本降低高达95%。
我还计算了在单个GPU上托管小型和大型模型的处理时间。
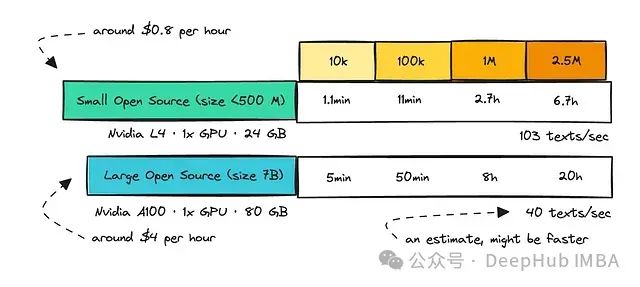
需要注意的是,调用API也需要时间,而且API通常有推理限制。因此无论你选择哪种方式,都必须考虑完全嵌入整个数据集所需的时间。
对于开源模型,你可以使用更多的GPU来加速处理,但这给了我们一个启示:使用较小的模型可能更加节能高效。
而最终上线时的最佳实践是测试几个模型,看看哪个模型在你的特定任务中表现最佳,这也是我们接下来要做的。
量化技术
如前所述,使用较大的模型(如7B参数规模的模型)仍然相当昂贵且能源密集。我们只计算了250万个嵌入的成本,但一旦你开始进一步扩大规模,研究量化技术可能会变得很有价值。
量化是通过使用较少的位来表示数据来压缩模型,从而减小模型的大小。这种技术的目的是使用4位和8位量化等方法,使得较大的模型能够在通常无法处理如此大规模模型的硬件上运行。
一些研究者尝试测量量化模型在各种指标上的性能下降;我记得最近看到的一项研究认为整体性能下降了约12%。
这是一个值得深入研究的话题,因为对于嵌入和生成对于量化来说是非常不同的,所以我们这里忽略掉量化,直接进入正题,开始测试模型。
数据导入
第一步就是数据导入
# 带有嵌入的合成LinkedIn档案
dataset=load_dataset("ilsilfverskiold/linkedin_profiles_synthetic")
profiles=dataset['train']
# 带有嵌入的匿名职位描述
dataset=load_dataset("ilsilfverskiold/linkedin_recruitment_questions_embedded")
applications=dataset['train']
这两个数据集将允许我们比较6,900个生成的LinkedIn档案的不同嵌入模型。
合成数据毕竟是人工生成的,所以在解释结果时需要谨慎。这些数据是使用Llama 3.1创建的,它们确实存在一些良好的对齐,但也使用了"结果导向"、"经验丰富"和"敬业"等常见描述词来描述档案。
嵌入已经被添加到数据集中,你可以在’profiles’中看到这一点。
# profiles数据集
Dataset({
features: [...,'embeddings_nv-embed-v1', 'embeddings_nv-embedqa-e5-v5', 'embeddings_bge-m3', 'embeddings_arctic-embed-l', 'embeddings_mistral-7b-v2', 'embeddings_gte-large-en-v1.5', 'embeddings_text-embedding-ada-002', 'embeddings_text-embedding-3-small', 'embeddings_voyage-3', 'embeddings_mxbai-embed-large-v1 '],
num_rows: 6904
})
注意:embeddings_gte-large-en-v1.5 不可用。我尝试托管它但未能为其设置所有嵌入,因此请不要使用它。
接下来选择你感兴趣的职位描述,以与档案进行匹配。
查看以下代码;我选择了第二个应用,但你可以设置其他数字。
application=applications[1] # 选择第二个应用 - 一个产品营销经理职位
application_text=application['natural_language']
print("application we're looking for: ",application_text)
如果你觉得直接在Hugging Face上查看数据集更方便,也可以这样做。
在这一步,你可以决定使用哪个嵌入模型。我已经测试了大多数模型,所以在这次运行中我将使用
embeddings_mxbai-embed-large-v1
。
这是一个334M参数的开源模型,如果你查看之前的表格,你会发现它在检索和聚类方面都表现出色。
如果你想尝试不同的模型,只需设置另一个模型名称。查看上面提到的数据集,了解你可以使用哪些模型。
# 获取特定嵌入模型的查询嵌入 - 这里我们选择mxbai-embed-large-v1
query_embedding_vector=np.array(application['embeddings_mxbai-embed-large-v1'])
embeddings_list= [np.array(emb) forembinprofiles['embeddings_mxbai-embed-large-v1 ']] # 注意额外的空格
texts=profiles['text']
语义搜索实现
在尝试聚类之前,首先可以测试语义搜索;这允许我们在引入其他技术之前评估其基本性能。
为了计算档案和我们的查询(职位申请)之间的语义相似度,可以执行以下代码:
# 首先尝试计算余弦相似度(不使用聚类)
defcosine_similarity(a, b):
a=np.array(a)
b=np.array(b)
returnnp.dot(a, b) / (np.linalg.norm(a) *np.linalg.norm(b))
similarities= []
foridx, embinenumerate(embeddings_list):
sim=cosine_similarity(query_embedding_vector, emb)
similarities.append(sim)
然后,我们可以按相似度降序排列结果,并显示前30个结果:
results=list(zip(range(1, len(texts) +1), similarities, texts))
sorted_results=sorted(results, key=lambdax: x[1], reverse=True)
# 显示结果
print("\nSimilarity Results (sorted from highest to lowest):")
foridx, sim, textinsorted_results[:30]: # 可以调整显示数量
percentage= (sim+1) /2*100
text_preview=' '.join(text.split()[:10])
print(f"Text {idx} similarity: {percentage:.2f}% - Preview: {text_preview}...")
执行上述代码后,结果可能如下所示(具体取决于你选择的应用):
Similarity Results (sorted from highest to lowest):
Text 3615 similarity: 89.59% - Preview: Product Marketing Manager | Building Go-to-Market Strategies for Growth Results-driven...
Text 6299 similarity: 89.56% - Preview: Product Marketing Manager | Driving Growth & Customer Engagement Results-driven...
Text 3232 similarity: 89.09% - Preview: Product Marketing Manager | Driving Product Growth through Data-Driven Strategies...
Text 5959 similarity: 88.90% - Preview: Product Marketing Manager | Data-Driven Growth Expert Results-driven Product Marketing...
Text 5635 similarity: 88.84% - Preview: Product Marketing Manager | Driving Growth through Data-Driven Marketing Strategies...
Text 5835 similarity: 88.74% - Preview: Product Marketing Manager | Cloud-Based SaaS Results-driven Product Marketing Manager...
Text 139 similarity: 88.66% - Preview: Product Marketing Manager | Scaling Growth through Data-Driven Strategies Experienced...
Text 6688 similarity: 88.48% - Preview: Product Marketing Manager | Driving Business Growth through Data-Driven Insights...
使用mxbai嵌入模型(以及许多其他模型)时,我们可以清楚地看到结果会同时返回产品营销经理和产品经理,这并不是我们期望的结果。
让我们引入聚类技术,看看是否能改善这一情况。
聚类实现
对档案嵌入进行聚类就需要决定聚类的数量。
本例中,我选择了10个聚类:
embeddings_array=np.array(embeddings_list)
num_clusters=10# 你可以选择其他数量
kmeans=KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(embeddings_array)
cluster_labels=kmeans.labels_
pca=PCA(n_components=2)
reduced_embeddings=pca.fit_transform(embeddings_array)
接下来,我们需要确定查询(或职位申请)应该属于哪个聚类:
# 现在看看查询如何适应聚类
query_embedding_array=np.array(query_embedding_vector).reshape(1, -1)
reduced_query_embedding=pca.transform(query_embedding_array)
# 预测查询应该属于哪个聚类
query_cluster_label=kmeans.predict(query_embedding_array)[0]
print(f"The query belongs to cluster {query_cluster_label}")
完成这些步骤后,可以在二维图上可视化聚类结果。聚类已经被压缩到二维空间,因此可能会出现重叠。
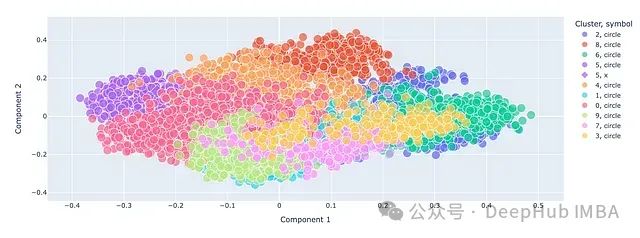
你可以悬停在不同的嵌入点上以查看具体档案信息。
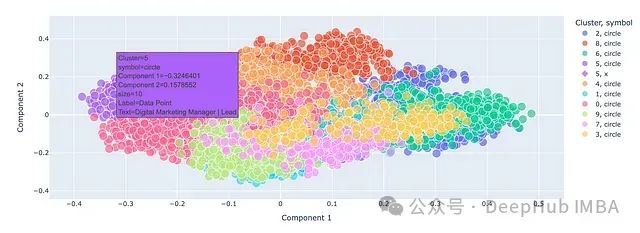
还可以在图上单独标出查询点(用X表示),以查看模型认为它属于哪个聚类。
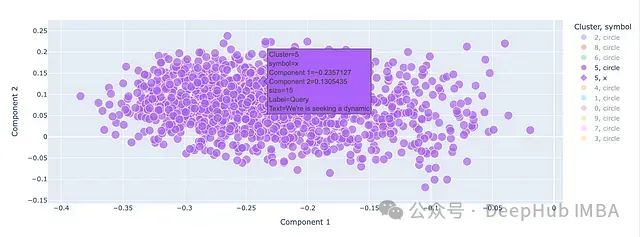
从结果中我们可以清楚地看到,模型正确地将营销相关职位归为一个聚类,包括SEO专家和增长黑客在内,同时将Office产品经理和产品经理排除在外。
这是一个令人鼓舞的结果,我们可以结合聚类和语义搜索来获得更精确的结果。
建议尝试不同的模型,观察它们的表现差异;你会发现较大的模型通常在分组相似档案方面表现更好,但一些较小的模型也能达到令人满意的效果。
结合聚类和语义搜索
既然我们已经确认模型能够将查询正确地分配到相应的聚类中,我们可以结合这两种方法来优化搜索结果。
# 现在我们只在正确的聚类中进行语义搜索
cluster_indices=np.where(cluster_labels==query_cluster_label)[0]
cluster_embeddings=embeddings_array[cluster_indices]
cluster_texts= [texts[i] foriincluster_indices]
similarities_in_cluster= []
foridx, embinzip(cluster_indices, cluster_embeddings):
sim=cosine_similarity(query_embedding_vector, emb)
similarities_in_cluster.append((idx, sim))
similarities_in_cluster.sort(key=lambdax: x[1], reverse=True)
top_n=40 # 可以调整此数字以显示更多匹配结果
top_matches=similarities_in_cluster[:top_n]
print(f"\nTop {top_n} similar texts in the same cluster as the query:")
foridx, simintop_matches:
percentage= (sim+1) /2*100
text_preview=' '.join(texts[idx].split()[:10])
print(f"Text {idx+1} similarity: {percentage:.2f}% - Preview: {text_preview}...")
执行上述代码后,我们可以看到结果中不再包含产品经理,而是返回了更相关的营销经理职位,这通常是更准确的匹配:
Top 40 similar texts in the same cluster as the query:
Text 3615 similarity: 89.59% - Preview: Product Marketing Manager | Building Go-to-Market Strategies for Growth Results-driven...
Text 3232 similarity: 89.09% - Preview: Product Marketing Manager | Driving Product Growth through Data-Driven Strategies...
Text 5959 similarity: 88.90% - Preview: Product Marketing Manager | Data-Driven Growth Expert Results-driven Product Marketing...
Text 5635 similarity: 88.84% - Preview: Product Marketing Manager | Driving Growth through Data-Driven Marketing Strategies...
Text 5835 similarity: 88.74% - Preview: Product Marketing Manager | Cloud-Based SaaS Results-driven Product Marketing Manager...
Text 139 similarity: 88.66% - Preview: Product Marketing Manager | Scaling Growth through Data-Driven Strategies Experienced...
Text 6688 similarity: 88.48% - Preview: Product Marketing Manager | Driving Business Growth through Data-Driven Insights...
Text 6405 similarity: 88.27% - Preview: Product Marketing Manager | Scaling SaaS Products for Global Markets...
Text 5183 similarity: 87.86% - Preview: Product Marketing Manager | B2B SaaS Experienced Product Marketing Manager...
本例的主要目的是让你比较不同的模型,特别是较小的模型与较大的模型,以评估在追求更快、更经济的推理过程中可以接受的质量损失程度。除非确实有必要,否则不要仅仅因为模型规模大就选择它。
如果你想继续评估模型性能,可以使用RAGAs(检索增强生成评估)来评估基于不同模型的检索应用程序的表现。
模型性能分析
为了评估模型性能,我选择了一个具体的指标:模型在区分产品经理和产品营销经理方面的能力。
研究发现,较大的模型在聚类之前通常能提供更准确的结果,但它们最初都存在将这两个角色分开的困难。
Ada-002,可能由于其较大的规模,在聚类之前表现良好,而OpenAI的较小和较新的模型text-embed-3-small表现相对较差。
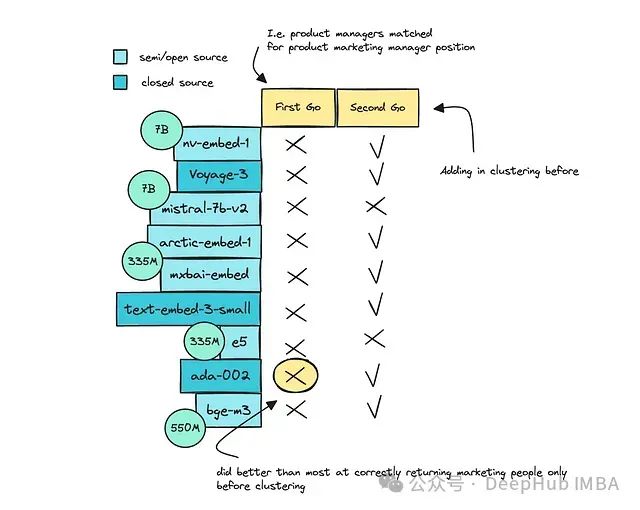
一些模型在正确聚类档案方面也存在困难。比如经过微调的7B Mistral模型和E5在这方面表现不佳。这可能是由于它们的训练方式和架构特点导致的。
其余模型对于这个特定的职位档案表现大致相同。
值得注意的是,mxbai模型的表现令人惊讶,尽管它只有335M的参数规模;这表明对于较简单的任务,较大的模型可能存在过度拟合的问题。
需要强调的是这只是针对一个特定任务的评估;建议你根据自己的具体需求,考虑其他方面来全面评估模型性能。
接下来,我们可以继续探讨如何进一步优化结果,例如使用重新排序等策略,以提供给大语言模型(LLM)最佳的评估输入。
重新排序技术
在检索增强生成(RAG)管道中,有多种策略可以用来纠正不相关的结果;重新排序是其中之一。
重新排序的基本思想是重新安排结果的顺序,使更相关的结果排在前面。实现这一目标的一种方法是使用成对排序。
具体操作是,将一对结果提供给模型(可能是大语言模型),并要求它根据职位描述对两个档案的相关性进行排序。
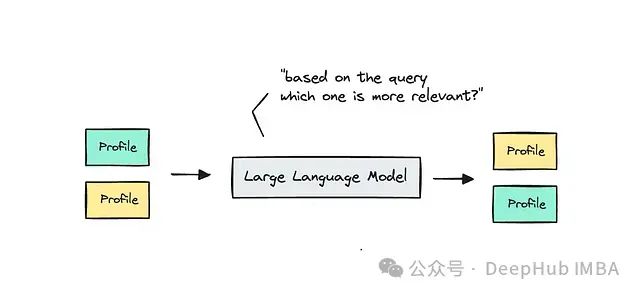
在实际应用中,你需要根据具体用例结合多种方法来优化性能。
总结
对于嵌入技术的新手,希望本文能为你提供有价值的见解。对于已经熟悉这一领域的读者,希望本文关于使用较小与较大嵌入模型的经济性分析能够带来新的思考。
值得注意的是,在大型语言模型(LLM)领域,许多闭源模型正在领先;但在嵌入模型方面,情况并非如此。
本文的一个重要结论是:不要忽视较小的、计算效率更高的模型。它们可能在特定任务中表现出色,同时提供更高的成本效益。
本文的Colab笔记本可以在以下链接找到:
https://avoid.overfit.cn/post/38350e175fa0424b8c988ad98930ff94
作者:Ida Silfverskiöld
版权归原作者 deephub 所有, 如有侵权,请联系我们删除。