

在推荐系统中,我们通常使用非常稀疏的矩阵,因为项目总体非常大,而单个用户通常与项目总体的一个非常小的子集进行交互。以YouTube为例——用户通常会观看数百个(可能是数千个)视频,而YouTube的语料库中有数百万个视频,这导致了>99%的稀疏性。

这意味着当我们在一个矩阵中表示用户(行)和行为(列)时,结果是一个由许多零值组成的极其稀疏的矩阵。
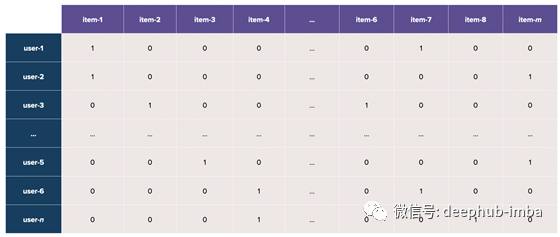
在真实的场景中,我们如何最好地表示这样一个稀疏的用户-项目交互矩阵?
为什么我们不能只使用Numpy数组或panda数据流呢?
要理解这一点,我们必须理解计算的两个主要约束——时间和内存。前者就是我们所知道的“程序运行所需的时间”,而后者是“程序使用了多少内存”。前者非常简单,但对于后者,确保程序不消耗所有内存非常重要,尤其是在处理大型数据集时,否则会遇到著名的“内存不足”错误。
我们PC上的每个程序和应用程序都使用一些内存(见下图)。当我们运行矩阵计算并希望将这些稀疏矩阵存储为Numpy数组或panda DataFrame时,它们也会消耗很多内存。
为了形式化这两个约束,它们通常被称为时间和空间(内存、硬盘等存储)复杂性。
空间复杂度
当处理稀疏矩阵时,将它们存储为一个完整的矩阵(从这里开始称为密集矩阵)是非常低效的。这是因为一个完整的数组为每个条目占用一块内存,所以一个n x m数组需要n x m块内存。从简单的逻辑角度来看,存储这么多零是没有意义的!
从数学的角度来看,如果我们有一个100,000 x 100,000矩阵,这将要求我们有100,000 x 100,000 x 8 = 80gb的内存来存储这个矩阵(因为每个double使用8字节)!
时间复杂度
除了空间复杂性之外,密集的矩阵也会加剧运行时。我们将用下面的一个例子来说明。
那么我们如何表示这些矩阵呢?
SciPy的稀疏模块介绍
在Python中,稀疏数据结构在scipy中得到了有效的实现。稀疏模块,其中大部分是基于Numpy数组。实现背后的思想很简单:我们不将所有值存储在密集的矩阵中,而是以某种格式存储非零值(例如,使用它们的行和列索引)。
在我们深入研究CSR之前,让我们比较一下在使用DataFrames和使用稀疏矩阵时在时间和空间复杂度上的效率差异。
import numpy as np
from scipy import sparse
from sys import getsizeof# Matrix 1: Create a dense matrix (stored as a full matrix).
A_full = np.random.rand(600, 600)# Matrix 2: Store A_full as a sparse matrix (though it is dense).
A_sparse = sparse.csc_matrix(A_full)# Matrix 3: Create a sparse matrix (stored as a full matrix).
B_full = np.diag(np.random.rand(600))# Matrix 4: Store B_full as a sparse matrix.
B_sparse = sparse.csc_matrix(B_full)# Create a square function to return the square of the matrix
def square(A):
return np.power(A, 2)
然后我们统计这些不同的矩阵以不同的形式存储以及它们使用了多少内存。
%timeit square(A_full)
print(getsizeof(A_full))>>> 6.91 ms ± 84.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
>>> 2880112%timeit square(A_sparse)
print(getsizeof(A_sparse))>>> 409 ms ± 11.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
>>> 56%timeit square(B_full)
print(getsizeof(B_full))>>> 2.18 ms ± 56.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
>>> 2880112%timeit square(B_sparse)
print(getsizeof(B_sparse))>>> 187 µs ± 5.24 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
>>> 56
显然,当我们用稀疏模块存储一个稀疏矩阵时,可以获得时间和空间的最佳性能。
压缩稀疏行(CSR)
尽管在SciPy中有很多类型的稀疏矩阵,比如键的字典(DOK)和列表的列表(LIL),但我只讨论压缩稀疏行(CSR),因为它是最常用和最广为人知的格式。
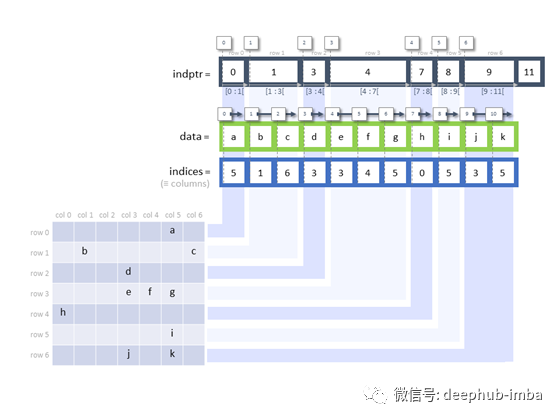
CSR(以及CSC,又名压缩稀疏列)用于写一次读多任务。为了有效地表示稀疏矩阵,CSR使用三个numpy数组来存储一些相关信息,包括:
data(数据):非零值的值,这些是存储在稀疏矩阵中的非零值
indices(索引):列索引的数组,从第一行(从左到右)开始,我们标识非零位置并在该行中返回它们的索引。在下面的图中,第一个非零值出现在第0行第5列,因此5作为索引数组中的第一个值出现,然后是1(第1行,第1列)。
indptr(指针):表示索引指针,返回一个行开始的数组。这个定义容易把人搞糊涂,我选择这样解释:它告诉我们每行包含多少个值。在下面的例子中,我们看到第一行包含一个值a,因此我们用0:1对它进行索引。第二行包含两个值b, c,然后我们从1:3开始索引,以此类推。len(indptr) = len(data) + 1 = len(indexes) + 1,因为对于每一行,我们用开始和结束索引表示它(类似于索引列表)。
有哪些方法可以构造csr_matrix?
创建一个完整的矩阵并将其转换为一个稀疏矩阵
some_dense_matrix = np.random.random(600, 600)
some_sparse_matrix = sparse.csr_matrix(some_dense_matrix)
正如前面所看到的,这种方法是有很大问题的,因为我们必须首先获得这个非常消耗内存的密集矩阵,然后才能将它转换成一个稀疏矩阵。
创建一个空的稀疏矩阵
# format: csr_matrix((row_len, col_len))
empty_sparse_matrix = sparse.csr_matrix((600, 600))
注意,我们不应该创建一个空的稀疏矩阵,然后填充它们,因为csr_matrix被设计为一次写、一次读多。向csr_matrix写入将是低效的,并且应该考虑其他类型的稀疏矩阵,比如在操作稀疏结构方面更有效的List of lists。
用数据创建一个稀疏矩阵
# method 1
# format: csr_matrix((data, (row_ind, col_ind)), [shape=(M, N)])
# where a[row_ind[k], col_ind[k]] = data[k]data = [3, 9, 5]
rows = [0, 1, 1]
cols = [2, 1, 2]sparse_matrix = sparse.csr_matrix((data, (rows, cols)),
shape=(len(rows), len(cols))
sparse_matrix.toarray()>>> array([[0, 0, 3],
[0, 9, 5],
[0, 0, 0]], dtype=int64)# method 2
# format: csr_matrix((data, indices, indptr), [shape=(M, N)])
# column indices for row i: indices[indptr[i]:indptr[i+1]]
# data values: data[indptr[i]:indptr[i+1]]data = [3, 9, 5]
indices = [2, 1, 2]
indptr = [0, 1, 3, 3]sparse_matrix = sparse.csr_matrix((data, indices, indptr))
sparse_matrix.toarray()>>> array([[0, 0, 3],
[0, 9, 5],
[0, 0, 0]], dtype=int64)
推荐使用这种方法
最后推荐两篇文章,有兴趣的可以深入阅读
Sparse data structures in Python
https://rushter.com/blog/scipy-sparse-matrices/
Complexity and Sparse Matrices
http://www.acme.byu.edu/wp-content/uploads/2015/11/Vol1Lab4Complexity.pdf
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********