
一、界面设置
文生图:根据文本提示生成图像
图生图:图像生成图像;功能很强大,自己在后续使用中探索。
后期处理:图片处理;功能很强大,自己在后续使用中探索。
PNG信息:这是一个快速获取图片生成参数的便捷功能。如果图像是在SD里生成的,您可以使用“发送到”按钮将参数快速复制到各个页面。
模型融合:您最多可以组合 3 个模型来创建新模型。它通常用于混合两个或多个模型的风格。但是,不能保证合并结果。它有时会产生不需要的伪影。
训练:训练页面用于训练模型。它目前支持textual inversion(embedding) 和hypernetwork。Mac不能用来训练模型,所以我不会介绍这一部分。
设置:设置里面的具体选项就不详细讲了,大家在后续使用中自行探索
更改任何设置后,记得单击“保存设置”后再重载界面。
扩展:安装扩展插件,下一步有详细讲。
二、生成参数设置
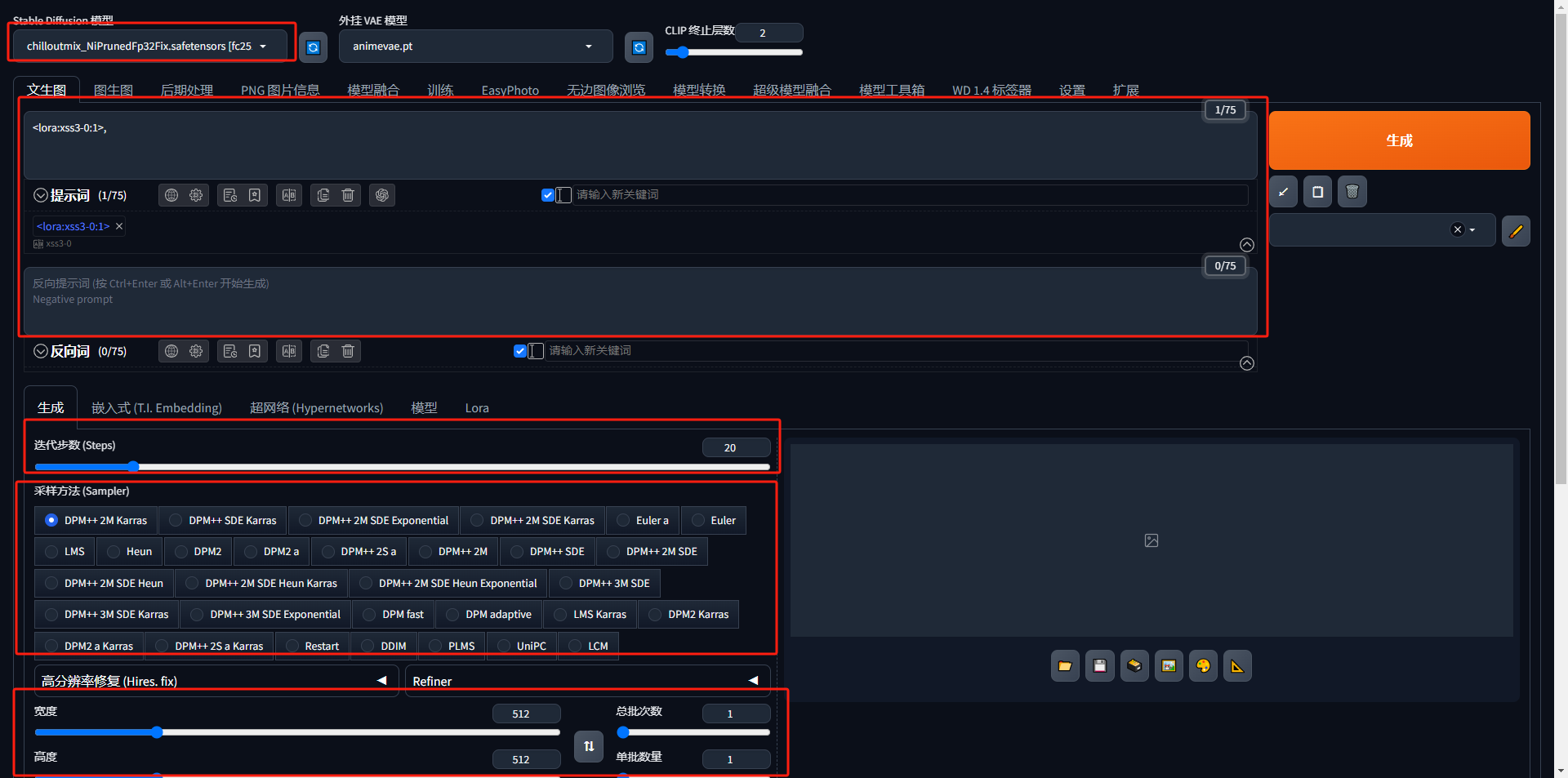
①左上角是选择基础模型,基于这个模型生成图片。
下拉菜单选择您想要的模型。首次使用的用户建议使用v1.5 基础模型。
下拉菜单旁边的刷新按钮用于刷新模型列表。当您刚刚将新模型放入模型文件夹需要更新列表时使用它。
②右边生成按钮下的按钮,从左到右:
1.读取最后一个参数:一般用于复制别人参数然后自动填充所有字段,以便您在按下“生成”按钮时生成相同的图像。请注意,将设置种子和模型覆盖。如果这不是您想要的,请将种子设置为 -1 并删除覆盖。
2.垃圾桶图标:删除当前提示和反向提示。
3.模型图标:显示额外的模型。此按钮用于将hypernetworks、embeddings和LoRA模型插入提示中。
4.加载样式:您可以从下面的样式下拉菜单中选择多种样式。使用此按钮将它们插入提示和反向提示中。
5.保存方式:保存提示和反向提示。您需要为样式命名。
③文本输入框,描述您想在图像中看到的内容。
- 正向提示词:指定你想看到的内容
- 反向提示词:指定你不想看到的内容
下面是一个例子:
提示词:
realistic, portrait of a girl,AI language model, silver hair,,question answering,smart, kind, energetic, cheerful, creative, with sparkling eyes and a contagious smile, ,information providing, conversation engaging, wide range of topics, accurate responses, helpful responses, knowledgeable, reliable, friendly, intelligent,sleek and futuristic design elements, and a complex network of circuits and processors. Others may imagine me as a friendly and approachable virtual assistant, with a smiling avatar or animated character representing me on their screen. Still, others may envision me as a disembodied voice, speaking from an unseen source, providing helpful and informative responses with a calm and reassuring tone
反向词:
(((sexy))),paintings,loli,,big head,sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans, nsfw, nipples,extra fingers, ((extra arms)), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck:1.3)
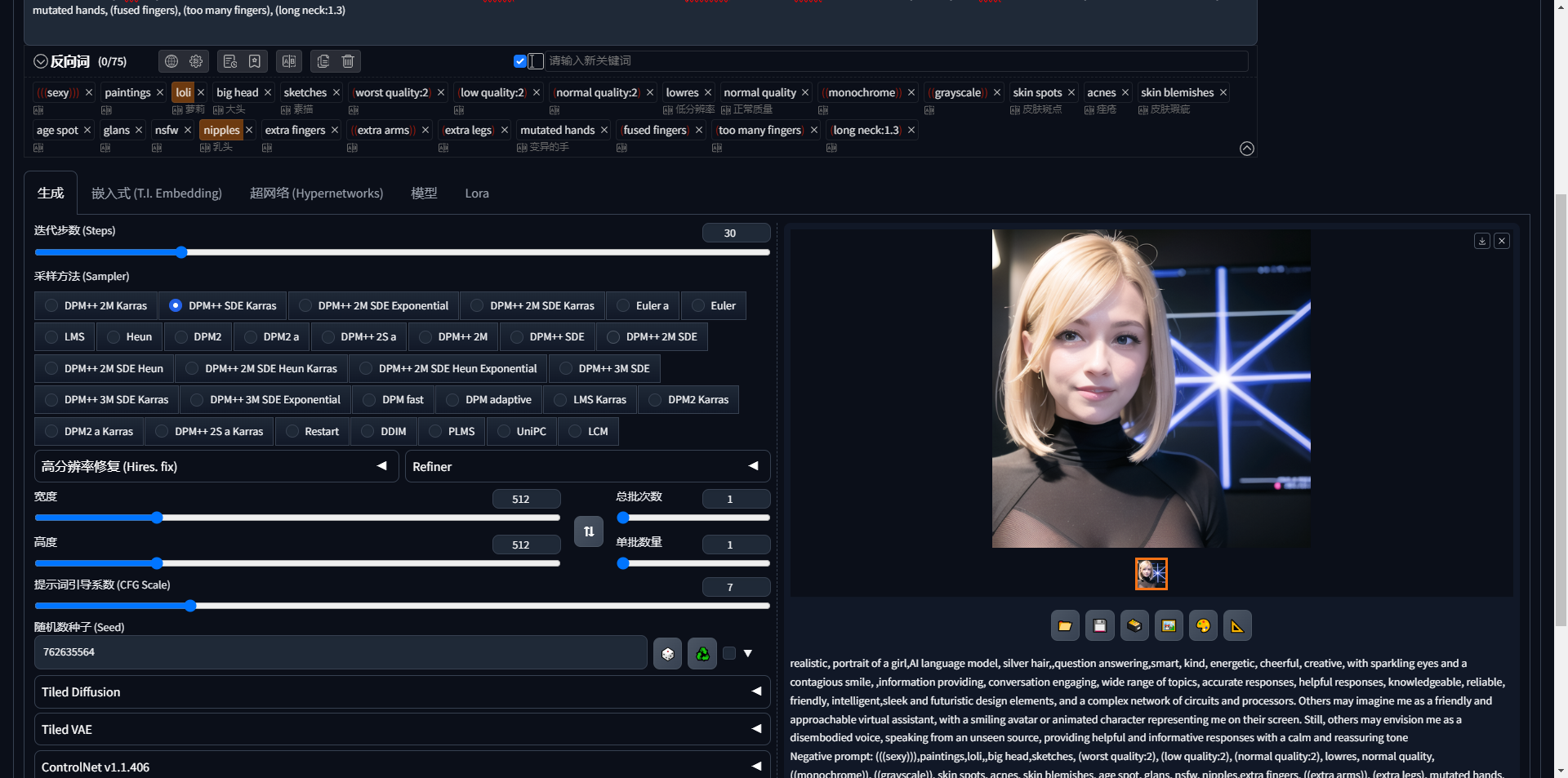
④采样方法:去噪过程的算法。
⑤采样步骤:去噪过程的采样步骤数。越多越好,但也需要更长的时间。25 个步骤适用于大多数情况。
⑥宽度和高度:输出图像的尺寸。使用 v1 模型时,您应该至少将一侧设置为 512 像素。例如,对于长宽比为 2:3 的肖像图像,将宽度设置为 512,高度设置为 768。
⑦批次计数:运行图像生成管道的次数。
⑧批量大小:每次运行管道时生成的图像数量。
生成的图像总数等于批次乘以批数。您通常会更改批量大小,因为它更快。仅当遇到内存问题时,您才会更改批次计数。
⑨CFG 比例:提示词引导系数是一个参数,用于控制模型遵守您的提示词的程度。(提示词权重)
- 1 – 大多忽略您的提示。
- 3 – 更加自由更有创意。
- 7 – 遵循提示和自由之间的良好平衡。
- 15 – 更加遵守提示。
- 30 – 严格按照提示操作。
下图显示了使用固定种子值更改 CFG 的效果。您不想将 CFG 值设置得太高或太低。如果 CFG 值太低,稳定扩散将忽略您的提示。太高时图像的颜色会饱和。

⑩种子Seed:用于在潜在空间中生成初始随机张量的种子值。实际上,它控制图像的内容。生成的每个图像都有自己的种子值。如果设置为 -1,AUTOMATIC1111 将使用随机种子值。
使用回收按钮复制种子值。

使用骰子图标将种子设置回 -1(随机)。

⑪面部修复需要应用一个额外的模型,该模型经过训练可以恢复面部缺陷。
在使用面部修复之前,您必须指定要使用的面部恢复模型。首先,访问“设置”选项卡。导航至面部恢复部分。选择面部修复模型。CodeFormer是一个不错的选择。将 CodeFormer 权重设置为 0 以获得最大效果。请记住单击“应用设置”按钮来保存设置!

⑫使用“平铺”选项可生成可平铺的周期性图像。就是由重复有规律图案拼成的图像。
⑬高分辨率修复选项应用upscaler来放大图像。因为稳定扩散的原始分辨率是 512 像素(或某些 v2 模型为 768 像素)。对于许多用途而言,图像太小了。
⑭最后,点击右边的生成按钮。稍等片刻后,您将获得图像!
版权归原作者 BasicLab基础架构实验室 所有, 如有侵权,请联系我们删除。