
spaCy 是自然语言处理(NLP)任务的必备库。spaCy 处理文本的过程是模块化的, 当调用 NLP 处理文本时,spaCy 首先将文本标记化以生成
Doc
对象,然后,依次在几个不同的组件中处理
Doc
,这也称为 处理管道 (Pipeline)。语言模型默认的处理管道依次是:Token, Tagger、Parser、NER 等,每个管道组件返回已处理的
Doc
,然后将其传递给下一个组件。

spacy 使用的语言模型是预先训练的统计模型,能够预测语言特征,对于英语,有:
- en_core_web_sm:英语多任务 CNN,在 OntoNotes 上训练,大小为 11 MB
- en_core_web_m:英语多任务 CNN,在 OntoNotes 上训练,并且使用 Common Crawl 上训练的 GLoVe 词嵌入,大小为 91 MB
- en_core_web_lg:英语多任务 CNN,在 OntoNotes 上训练,并且使用 Common Crawl 上训练的 GLoVe 词嵌入,大小为 789 MB
- en_core_web_trf:于 V3.0 新版本上发布的 Transformer-based pipelines 模型
# 下载spacy库,这里指定版本
pip install spacy==3.2.0
# 也可以不指定版本
pip install spacy
# 或者更新库
pip install spacy==x.x.x
OSError: [E050] Can’t find model ‘en_core_web_sm’. It doesn’t seem to be a shortcut link, a Python package or a valid path to a data directory.
这个报错说明没有相应的语言模型包。
运行如下命令安装
en_core_web_sm、zh_core_web_sm
:
结尾加上 --user 以管理员的身份运行,不如也可能不超过。
# English
python -m spacy download en_core_web_sm --user
# Chinese
python -m spacy download zh_core_web_sm --user
但有时候,并不能下载成功,甚至报错,可以在github上找到相应下载网址下载
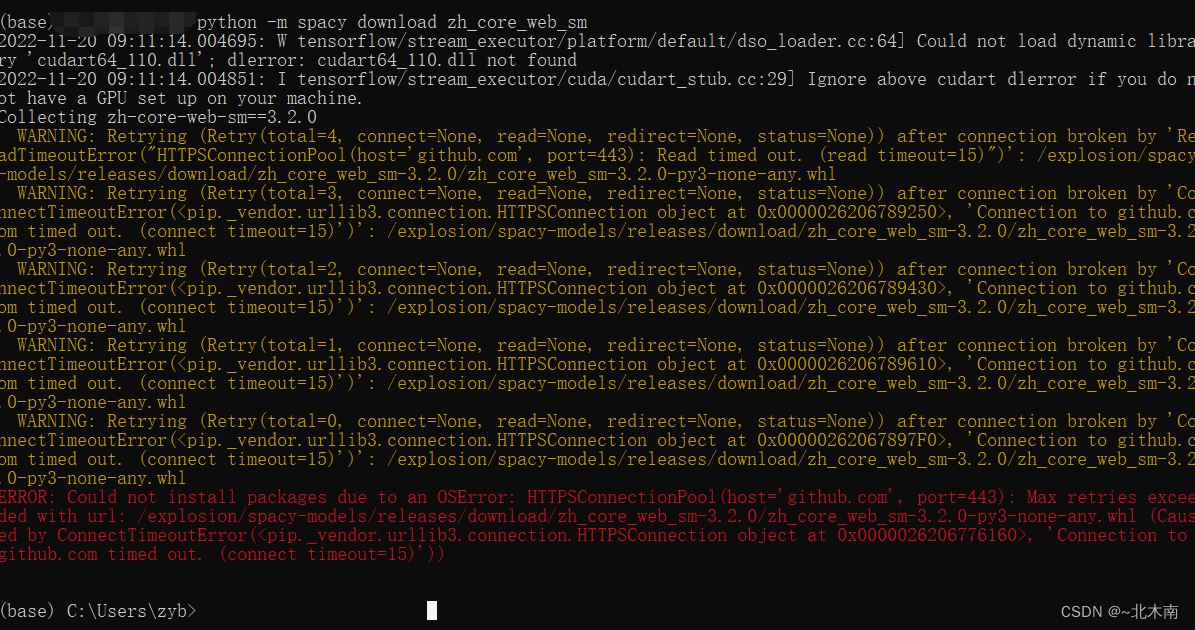
解决办法——从GitHub上下载
pip3 install https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.2.0/en_core_web_sm-3.2.0.tar.gz
直接打开conda终端输入此命令!
值得一提的是!!!
spacy的版本需要和en_core_web_sm、zh_core_web_sm的版本相对应,否则也会报错。
本文转载自: https://blog.csdn.net/m0_53328738/article/details/127597325
版权归原作者 ~北木南 所有, 如有侵权,请联系我们删除。
版权归原作者 ~北木南 所有, 如有侵权,请联系我们删除。