
1. 从embedding到Encoder-Decoder
1.1 Embedding
embedding可以把文字和图像转为向量(k维的浮点数特征向量)。
比如我们输入的句子长度为7,词典大小为100,把每一个整数转为2维小数的embedding直观代码如下:
from keras.models import Sequential
from keras.layers import Embedding
model = Sequential()
model.add(Embedding(100,2, input_length=7))#输入维,输出维
data = np.array([[0,2,0,1,1,0,0],[0,1,1,2,1,0,0],[0,1,12,1,15,0,1]])
model.predict(data) # 输入维度(3,7)整型,输出维度(3,7,2)浮点类型
图片同样可以做embedding,我们要把
N
∗
N
∗
256
N*N*256
N∗N∗256(前两个是尺寸,最后是灰度)的图像用
N
/
16
∗
N
/
16
∗
1000
N/16*N/16*1000
N/16∗N/16∗1000来表示,将每16个像素点看做一个像素块,则像素块为16*16*256的整数,要将其映射为1000维的浮点数。
embedding网络是
[
16
∗
16
∗
256
,
1000
]
[16*16*256,1000]
[16∗16∗256,1000]的浮点数矩阵,每一行的1000维数据就是每个块的embedding表示。
1.2 Encoder-Decoder 结构
Encoder-Decoder指的是如下的模型: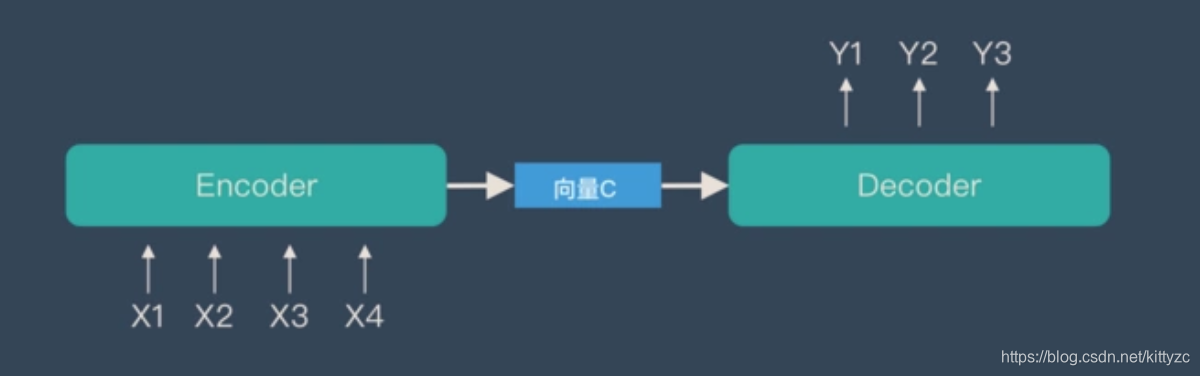
关于基本Encoder-Decoder,有2点需要说明:
1)不论输入和输出的长度是什么,中间的「向量 c」 长度都是固定的(这也是它的缺陷,下文会详细说明)
根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN ,但通常是其变种 LSTM 或者 GRU )
2)只要是符合上面的框架,都可以统称为 Encoder-Decoder 模型。说到 Encoder-Decoder 模型就经常提到一个名词—— Seq2Seq。
Seq2Seq(是 Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。常见的应用有:机器翻译、对话机器人、诗词生成、代码补全、文章摘要(文本 - 文本)。Encoder-Decoder是Seq2Seq的一种,即中间有个固定长度的向量C: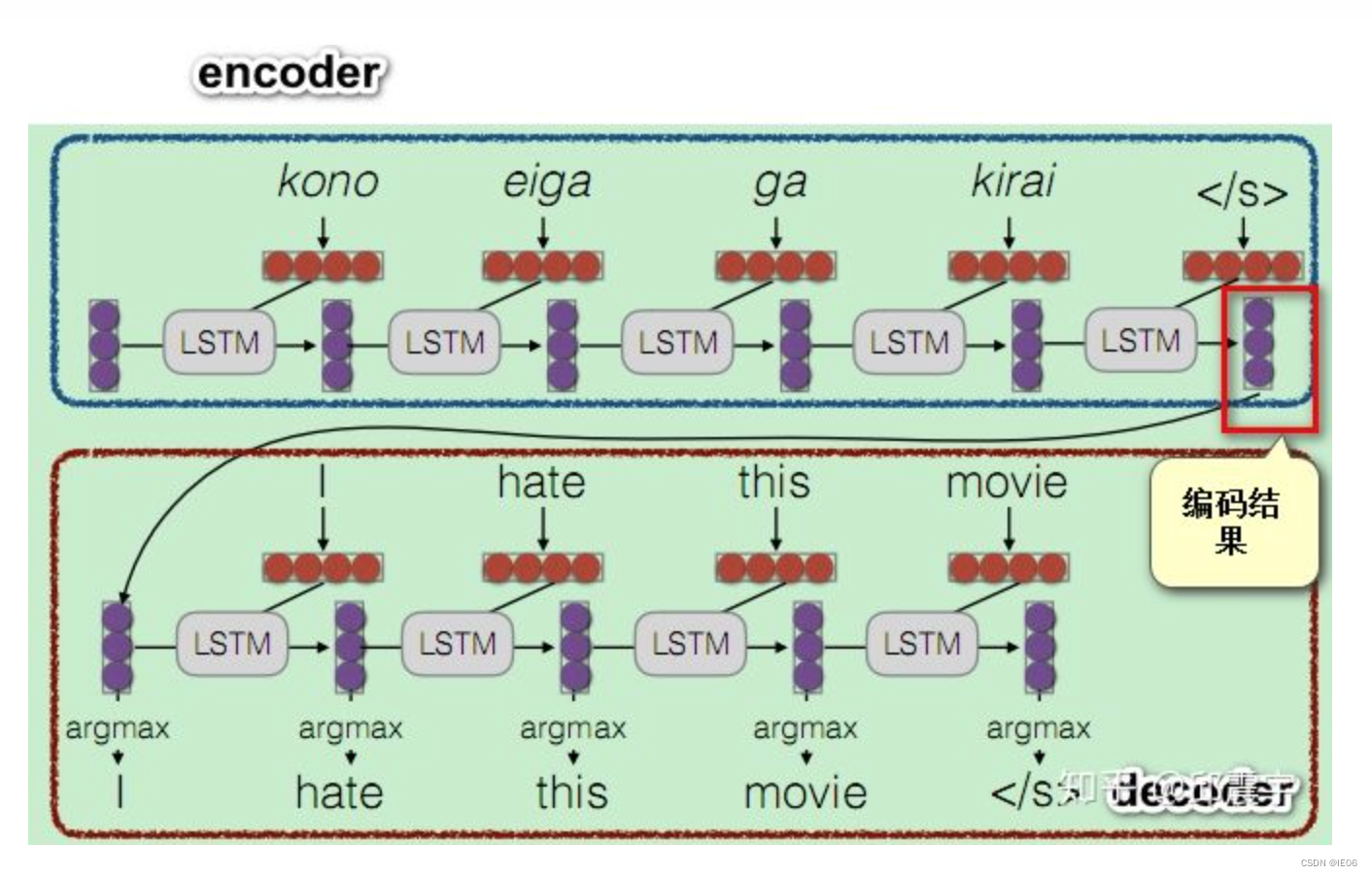
2 Attention
2.1 attention机制
Encoder-Decoder 当输入信息太长时,会丢失掉一些信息(编码长度优先,在编码时进行了压缩,因此丢失信息是必然的)。Attention 机制就是为了解决「信息过长,信息丢失」的问题,简单来说,Attention 模型的特点是 Encoder 不再将整个输入序列编码为固定长度的「中间向量 C」 ,而是编码成一个向量的序列。
引入了attention的Encoder-Decoder模型如下图,简单来说就是:不断输入X(代号K),不断计算C(注意力),不断decode成Y(代号Q)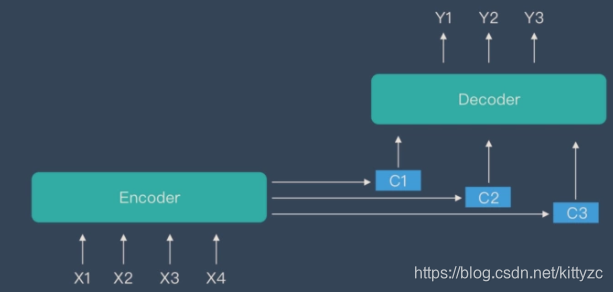
我们来看例子,输入X为kono eiga ga kirai(この映画が嫌い),其中日语的语序和英语是不一样的。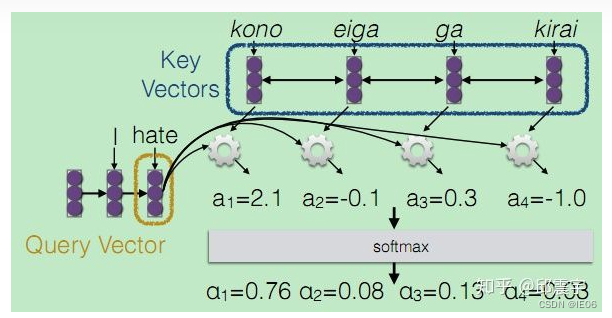
这里的注意力数组是用hate和日语原文乘积得到的。注意力集中在第一个单词kono,也就是说I hate 后面紧接着的this对应的起始是kono这个词。
我们来看下计算注意力数据的方法。其输入是待翻译的特征向量
K
K
K(key vectors),一个当前输出的特征向量
Q
i
Q_i
Qi(query vectors),计算函数为
a
i
=
F
(
Q
i
,
K
)
a_i=F(Q_i,K)
ai=F(Qi,K)。如果q、k维度相同,可以直接用点乘:
a
=
q
T
k
a=q^Tk
a=qTk;若维度不同,可以再加个学习参数矩阵W:
a
=
q
T
W
k
a=q^TWk
a=qTWk。此外,最好做一个归一化:
a
=
q
T
k
/
∣
k
∣
a=q^Tk/\sqrt{|k|}
a=qTk/∣k∣。
2.2 Self-attention机制
如果Q和K相同,则称为self-attention机制。一般的词嵌入模块学习的是单词之间的关系,而self-attention模块学习了单词在句子上下文环境中的关系(transformer中甚至还显式的加上了位置编码)。注意和Attention机制区分开,在Attention中我们有一对对的训练数据,而self-attention没有。
换种方式说明:假设我们得到了一段输入文本,并且从文本中的单词嵌入 W 开始。我们需要找到一种 Embedding 方法来度量同一文本中其他单词嵌入相对于 W 的重要度,并合并它们的信息来创建更新的嵌入W’。
具体做法是:自注意力机制会将 Embedding 输入文本中的每个单词线性投影到三个不同的空间中(这些矩阵在训练过程中需要学习),从而产生三种新的表示形式:即查询query、键key和值value。这些新的嵌入将用于获得一个得分,该得分将代表 W 和每个Wn 之间的依赖性(如果 W 依赖于 W’,则结果为绝对值很高的正数,如果 W 与W’不相关,则结果为绝对值很高的负值)。这个分数将被用来组合来自不同 Wn 单词嵌入的信息,为单词 W 的值v创建更新的嵌入e。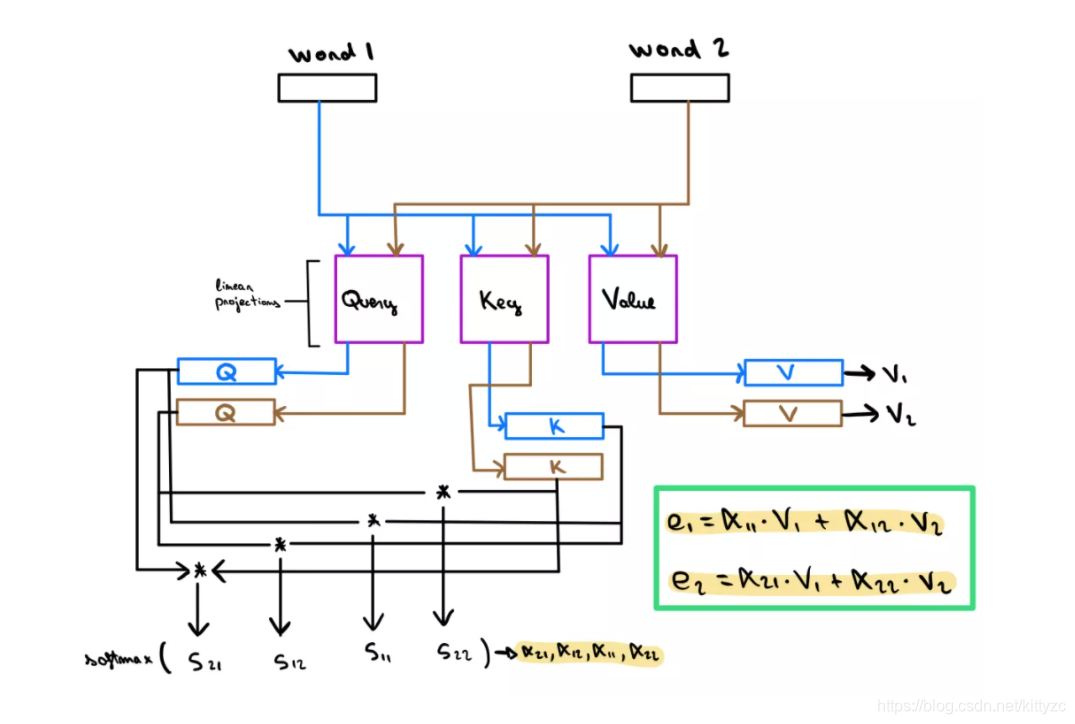
用矩阵形式,直观表达如下: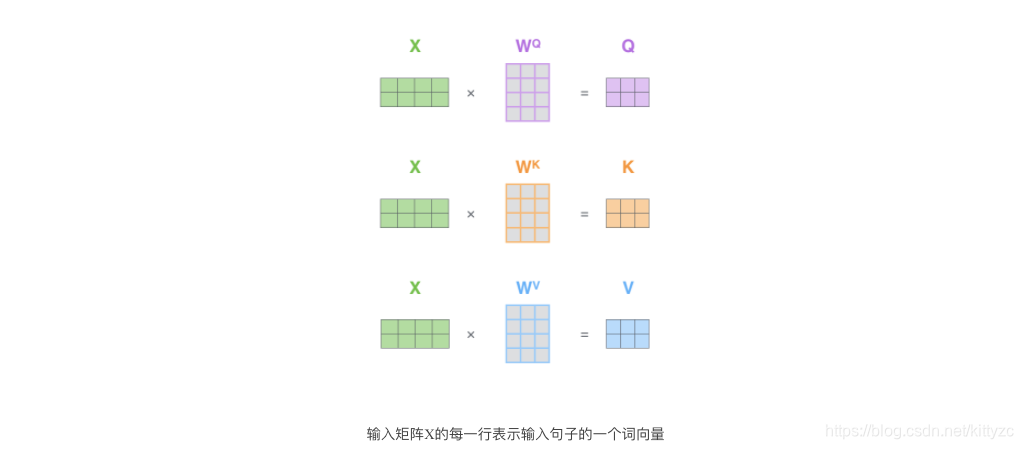
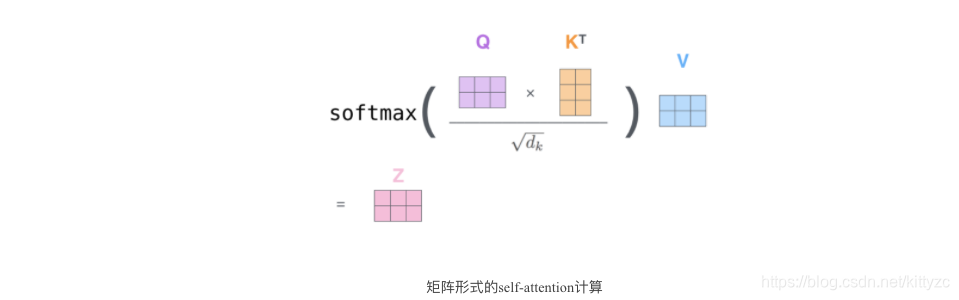
注意到这些新向量的维度比输入词向量的维度要小(512–>64),并不是必须要小的,是为了让多头attention的计算更稳定。
下面是个例子:对“Thinking Matchines”这句话,对“Thinking”(pos#1)计算attention 分值。我们需要计算每个词与“Thinking”的评估分,这个分决定着编码“Thinking”时(某个固定位置时),每个输入词需要集中多少关注度。
这个分通过“Thing”对应query-vector与所有词的key-vec依次做点积得到。所以当我们处理位置#1时,第一个分值是q1和k1的点积,第二个分值是q1和k2的点积。除以8,这样梯度会更稳定。然后加上softmax操作,归一化分值使得全为正数且加和为1。将softmax分值与value-vec按位相乘。保留关注词的value值,削弱非相关词的value值。将所有加权向量加和,产生该位置的self-attention的输出结果。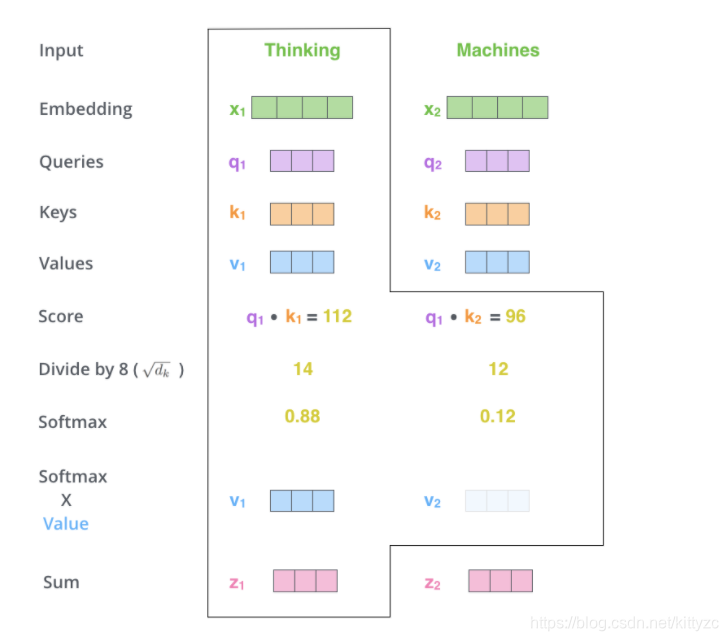
下图是一个self-attention的可视化例子:
用来做训练的一个编码器-解码器如图: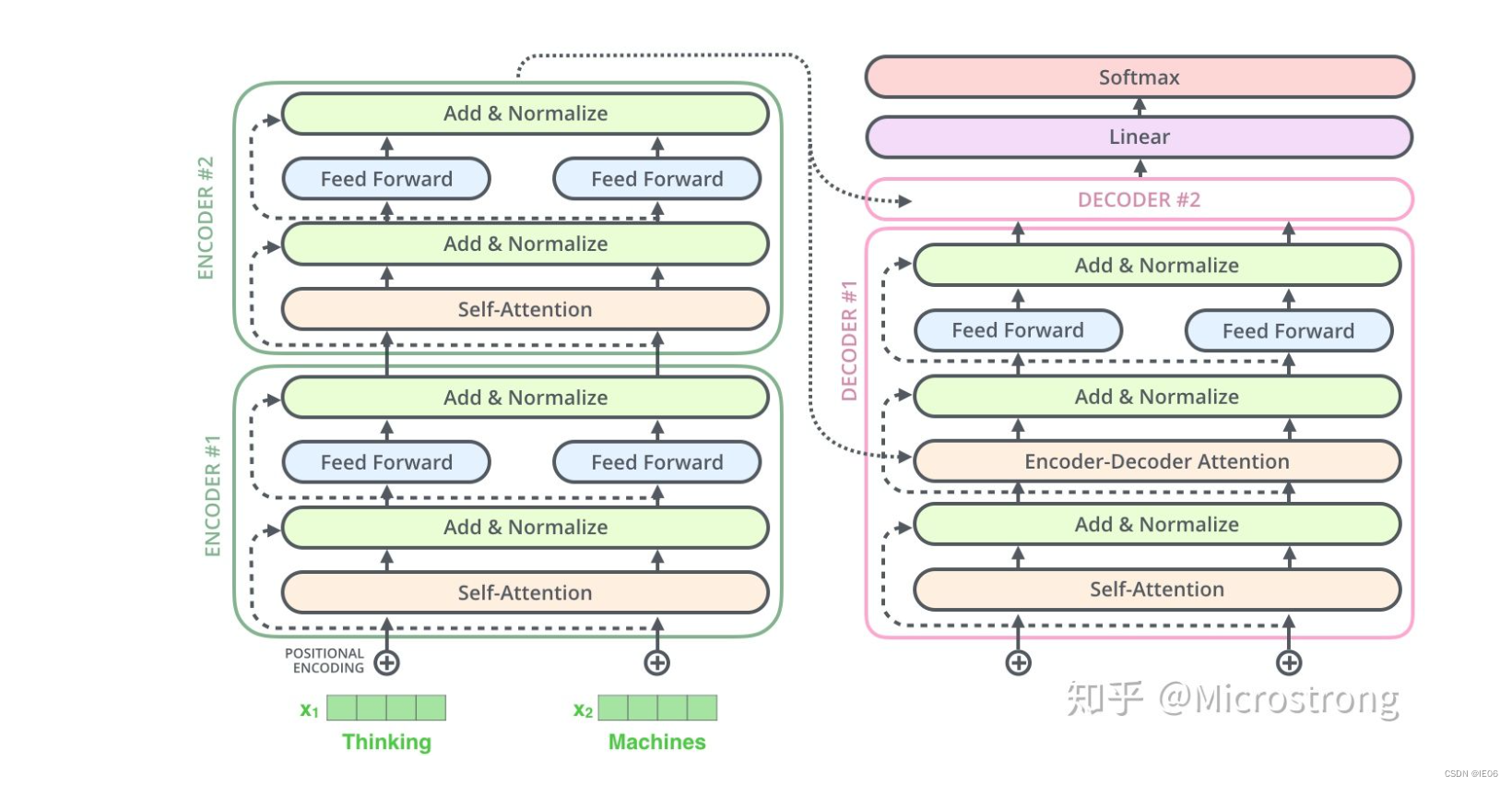
2.3 图像/视频的自注意力机制和交叉注意力机制
为了统一图像和视频,我们把图像用3维数据表示(宽、高、帧)。对于图像
X
∈
R
h
×
w
×
s
X\in R^{h\times w\times s}
X∈Rh×w×s上的任意一个点
(
i
,
j
,
k
)
(i,j,k)
(i,j,k),
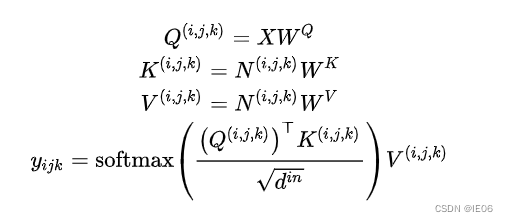
其中N是点
(
i
,
j
,
k
)
(i,j,k)
(i,j,k)的临近区域(相当于加了位置编码)。
交叉注意力机制有两个输入X和C,其中C用来计算N,其他都相同。我们可以把两者简单加起来作为解码器: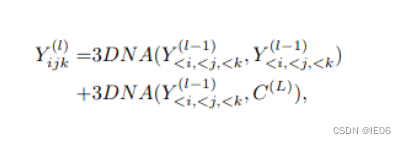
版权归原作者 IE06 所有, 如有侵权,请联系我们删除。