
Numpy中的广播
广播(Broadcast)是 numpy 对不同维度(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
“维度”指的是特征或数据列。例如,有一项研究测量水的温度,另一项研究测量水的盐度和温度,第一个研究有一个维度;温度,而盐度和温度的研究是二维的。维度只是每个观测的不同属性,或者一些数据中的行。
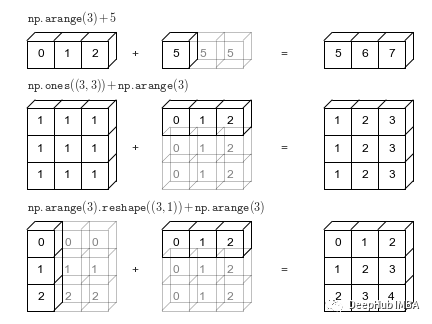
在正常情况下,NumPy不能很好地处理不同大小的数组。典型的NumPy操作一般会要求数据的维度是相同的,例如
import numpy as np
a = np.array([50, 20, 1, 15])
b = np.array([10, 20, 10, 20])
print(np.shape(a), "\n", np.shape(a))
(4,)
(4,)
它们都是水平形状的一维数组。我们可以对他们进行常规的数学操作,因为它们是相同的形状:
print(a * b)
[500 400 10 300]
如果要使用另一个具有不同形状的数组来尝试上一个示例,就会得到维度不匹配的错误。
c = np.array([4, 2, 1])
print(c * a)
ValueError: operands could not be broadcast together with shapes (3,) (4,)
但是因为Numpy 的广播机制,Numpy会尝试将数组广播到另一个操作数。广播通过扩充较小数组中的元素来适配较大数组的形状,它的本制是就是张量自动扩展,也就是说根据规则来进行的张量复制。
下面我们看下几个常见的广播示例
a ** 2
array([2500, 400, 1, 225])
2是一个标量,而a是一个数组,他们在维度上肯定是不同的,但是我们一般都会这么写,这就是广播,广播的机制会把2扩充成与a相同的维度 [2,2,2,2]然后再与a逐个相乘,就得到了我们要的结果。
在二维数组中,广播规则同样适用,请参见如下代码。
a = np.array([[0, 0, 0],
[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
b = np.array([1, 2, 3])
a + b
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])
可以看到,a中的最后一个维度都与b进行了相加操作,也就是b被自动扩充了,也就是说如果两个向量在维数上不相符,只要维度尾部是相等的,广播就会自动进行
能否广播必须从axis的最大值向最小值看去,依次对比两个要进行运算的数组的axis的数据宽度是否相等,如果在某一个axis下,一个数据宽度为1,另一个数据宽度不为1,那么numpy就可以进行广播;但是一旦出现了在某个axis下两个数据宽度不相等,并且两者全不为1的状况,就无法广播,看看下面的例子:
a = np.arange(6).reshape((2, 3, 1))
print(a)
array([[[0],
[1],
[2]],
[[3],
[4],
[5]]])
b = np.arange(6).reshape((1, 3, 2))
print(b)
array([[[0, 1],
[2, 3],
[4, 5]]])
那么a+b是否可行呢?如果可行结果是多少?
print(a+b)
array([[[ 0, 1],
[ 3, 4],
[ 6, 7]],
[[ 3, 4],
[ 6, 7],
[ 9, 10]]])
那么这个广播是怎么计算来的呢?首先我们看到结果的形状与a,b都相同,那么说明是a,b都进行广播了,也就是说同时需要复制这两个数组,把他们扩充成相同的维度,我们把结果分解:
首先对a进行扩充,变为:
array([[[0,0],
[1,1],
[2,2]],
[[3,3],
[4,4],
[5,5]]])
然后在对b进行扩充
array([[[0, 1],
[2, 3],
[4, 5]],
[[0, 1],
[2, 3],
[4, 5]]])
这样维度一致后进行加法操作:
array([[[0+0,0+1],
[1+2,1+3],
[2+4,2+5]],
[[3+0,3+1],
[4+2,4+3],
[5+4,5+5]]])
左边是a,右边是b,这样相加就得到了最后的结果
Pandas中的广播
Pandas的操作也与Numpy类似,但是这里我们特别说明3个函数,Apply、Applymap和Aggregate,这三个函数经常用于按用户希望的方式转换变量或整个数据。可以将这些函数称为“广播函数”,因为它们允许向变量或数据中的所有数据点广播特定的逻辑,比如一个自定义函数。对于这些例子,
我们首先导入pandas包,然后加载数据到“df”的变量中,这里使用泰坦尼克的数据集
import pandas as pd
df = pd.read_csv("../input/titanic/train.csv")
1、Apply
pandas中的apply函数是一个变量级别的函数,可以应用各种转换来转换一个变量。例如可以利用lambda表达式或函数来创建转换逻辑。例如,如在“Fare”变量上乘以100:
df['Fare'] = df['Fare'].apply(lambda x: x * 100)
最长用的方式是我们处理日期类型,例如从xxxx/mm/dd格式的字符串日期中提取月和日信息
data['last_review_month'] = data['last_review'].apply(lambda x: datetime.datetime.strptime(x, "%Y-%m-%d").month)
data['last_review_day'] = data['last_review'].apply(lambda x: datetime.datetime.strptime(x, "%Y-%m-%d").day)
2、Applymap
Applymap函数是apply的所有数据版本,其中转换逻辑应用于数据中的每个数据点(也就是数据行的每一列)。
假设我们想把所有乘客的名字都改成小写。出于演示目的,让我们创建一个单独的数据框架,它是原始数据框架的子集,其中只有“Name”变量。
先看一个不对的例子:
mapping = {"male":0, "female":1}
df.applymap(mapping.get)
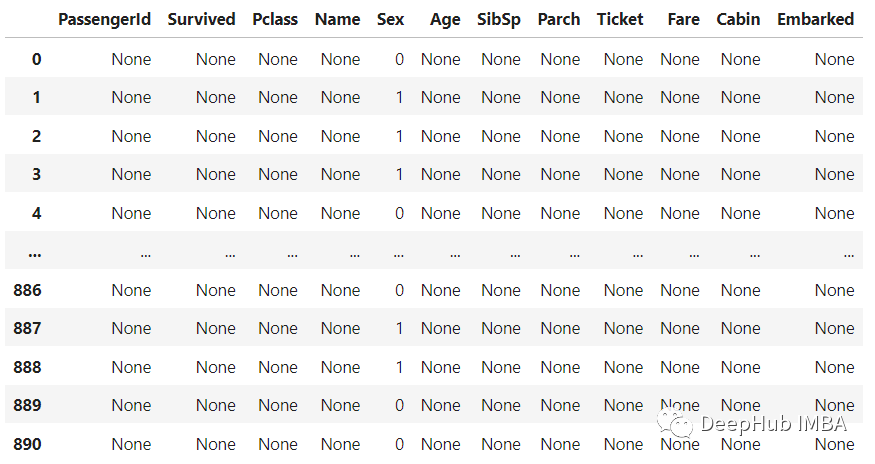
也就是说每一列都会被操作,我们看到所有与“Sex”变量无关的其他单元格都被替换为None。但是我们肯定不希望这样,所以需要构造lambda表达式来只在单元格中的值是一个映射键时替换这些值,在本例中是字符串' male '和' female '
df.applymap(lambda x: mapping[x] if x in mapping.keys() else x)
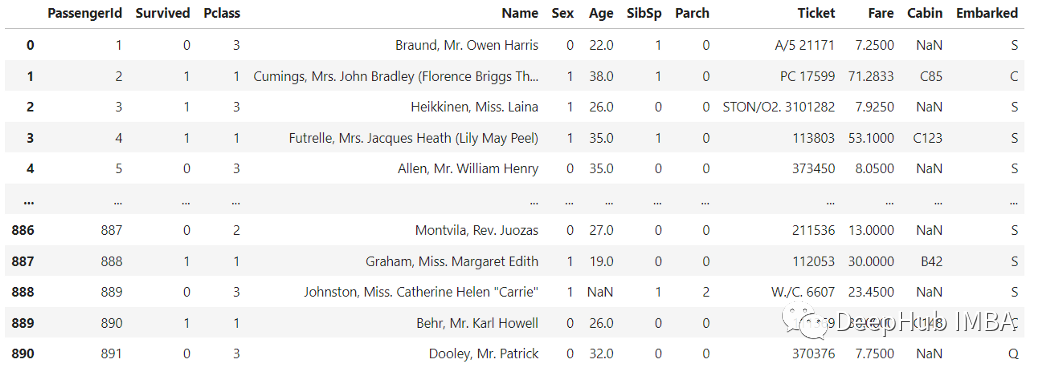
这样就对了,现在只有“Sex”变量被转换了,而其他变量都是完整的。
3、Aggregation
Aggregation函数与Apply和Applymap函数不同,它返回一个新的df,其中包括用户指定的聚合汇总统计信息。汇总汇总统计是指包括最大值、最小值、平均值、中位数、众数在内的统计量。下面我们计算了乘客的平均年龄、最大年龄和生存率。
df.groupby("Pclass").agg(avg_age = ("Age", "mean"),
max_age = ("Age", "max"),
survival_rate = ("Survived", "mean"))
聚合函数一般都会与Groupby函数结合使用。
总结
在本文中,我们介绍了Numpy的广播机制和Pandas中的一些广播的函数,并使用泰坦尼克的数据集演示了pandas上常用的转换/广播操作。