

Requirements:
- Python: 3.8.5
- PyTorch: 1.8.0
- Transformers: 4.9.0
- NLTK: 3.5
- LTP: 4.0
** Model:**
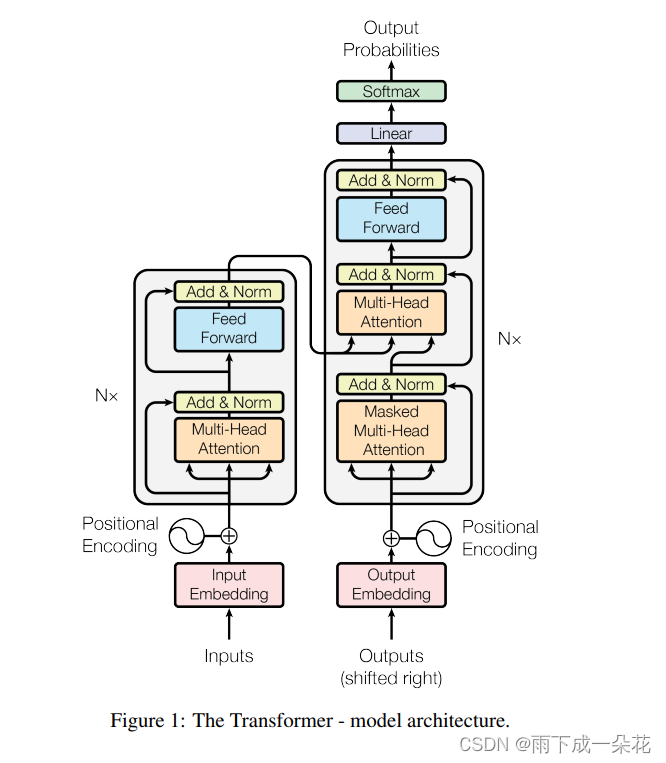
Attention:
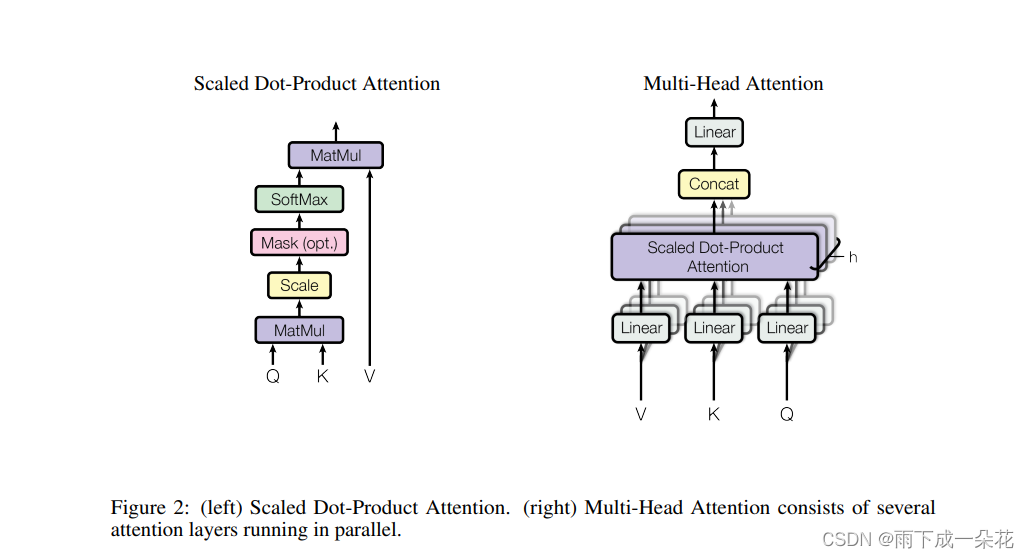
论文解读参考:
https://blog.csdn.net/Magical_Bubble/article/details/89083225
实验步骤:
1)下载VSstudio2019
注意:安装时勾选“Python开发”和“C++桌面开发”
2) 下载和安装nvidia显卡驱动

下载之后就是简单的下一步直到完成。
完成之后,在cmd中输入执行:
nvidia-smi
如果有错误:
'nvidia-smi' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
把C:\Program Files\NVIDIA Corporation\NVSMI添加到环境变量的path中。再重新打开cmd窗口。
3) 下载和安装CUDA和cuDNN
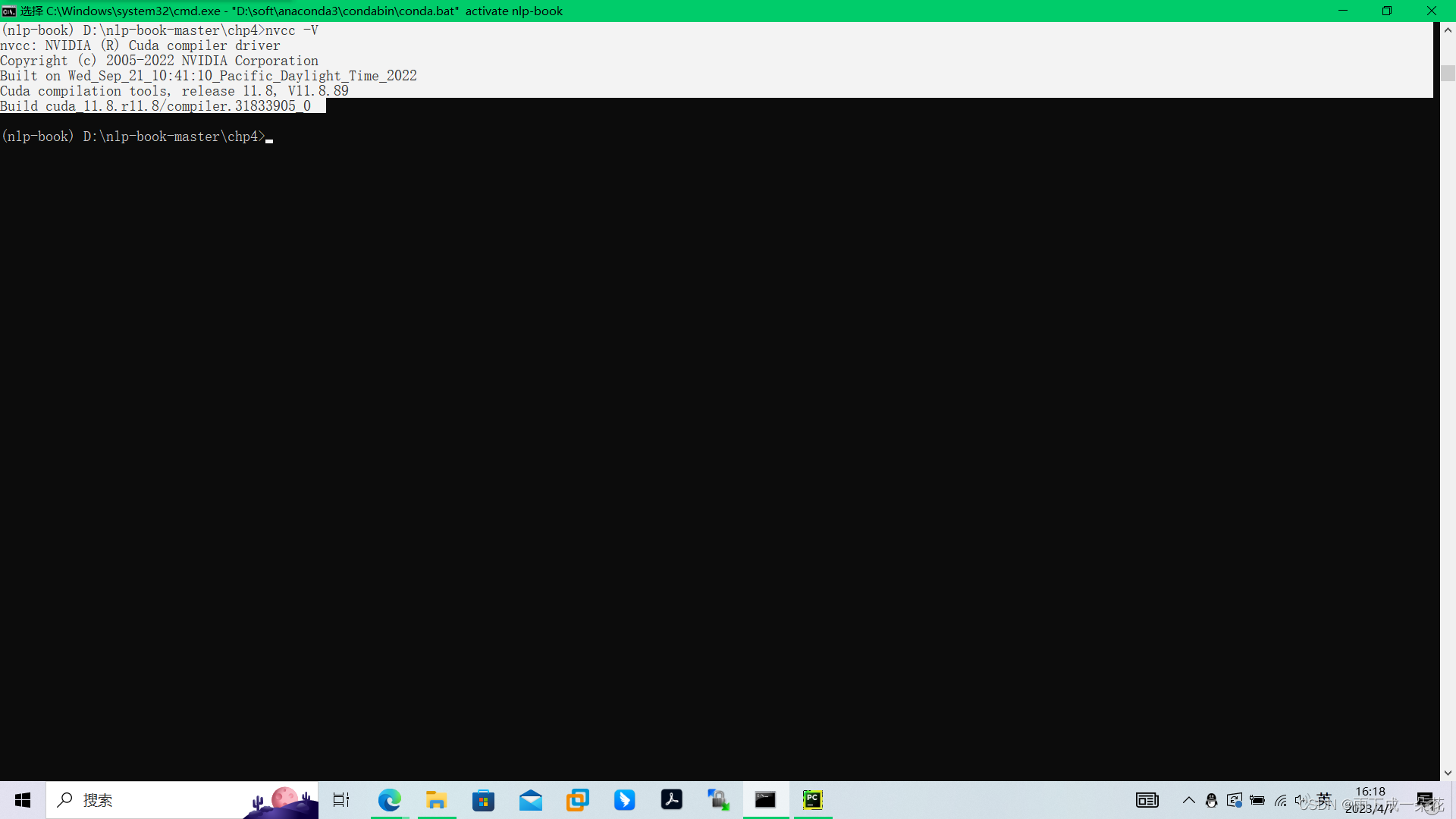
安装完后,可以执行nvcc -V 来验证gpu是否可以等待应用,下图表示cuda安装好了
4) 安装Anaconda
搭建虚拟环境和pytorch软件平台

5)添加Aanaconda国内镜像配置
清华TUNA提供了 Anaconda 仓库的镜像,运行以下命令:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
6)建立虚拟环境,安装软件pytorch,transformer
(这个很重要,可以保证不同版本的包独立环境)
创建虚拟环境:conda create -n nlp-book python=3.8.5(虚拟环境安装不上的话:conda config --add channels conda-forge)
激活虚拟环境nlp-book,输入: conda activate nlp-book
删除虚拟环境:conda remove -n your_env_name --all
**激活虚拟环境nlp-book: **
在所创建的pytorch环境下安装pytorch, 执行命令:
(conda install pytorch=1.8 torchvision cudatoolkit=10.2 -c pytorch)
conda install pytorch=1.8.0 torchvision cudatoolkit -c pytorch(笔记本)
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge(台式机)
【注意:在虚拟环境下,安装pytorch,可能会碰到包的不兼容性,会报错
anaconda search -t conda libcublas >=11.10.1.25,<11.11.3.6
(and similarly for the other packages)
于是在cmd命令行,输入:
anaconda search -t conda pytorch
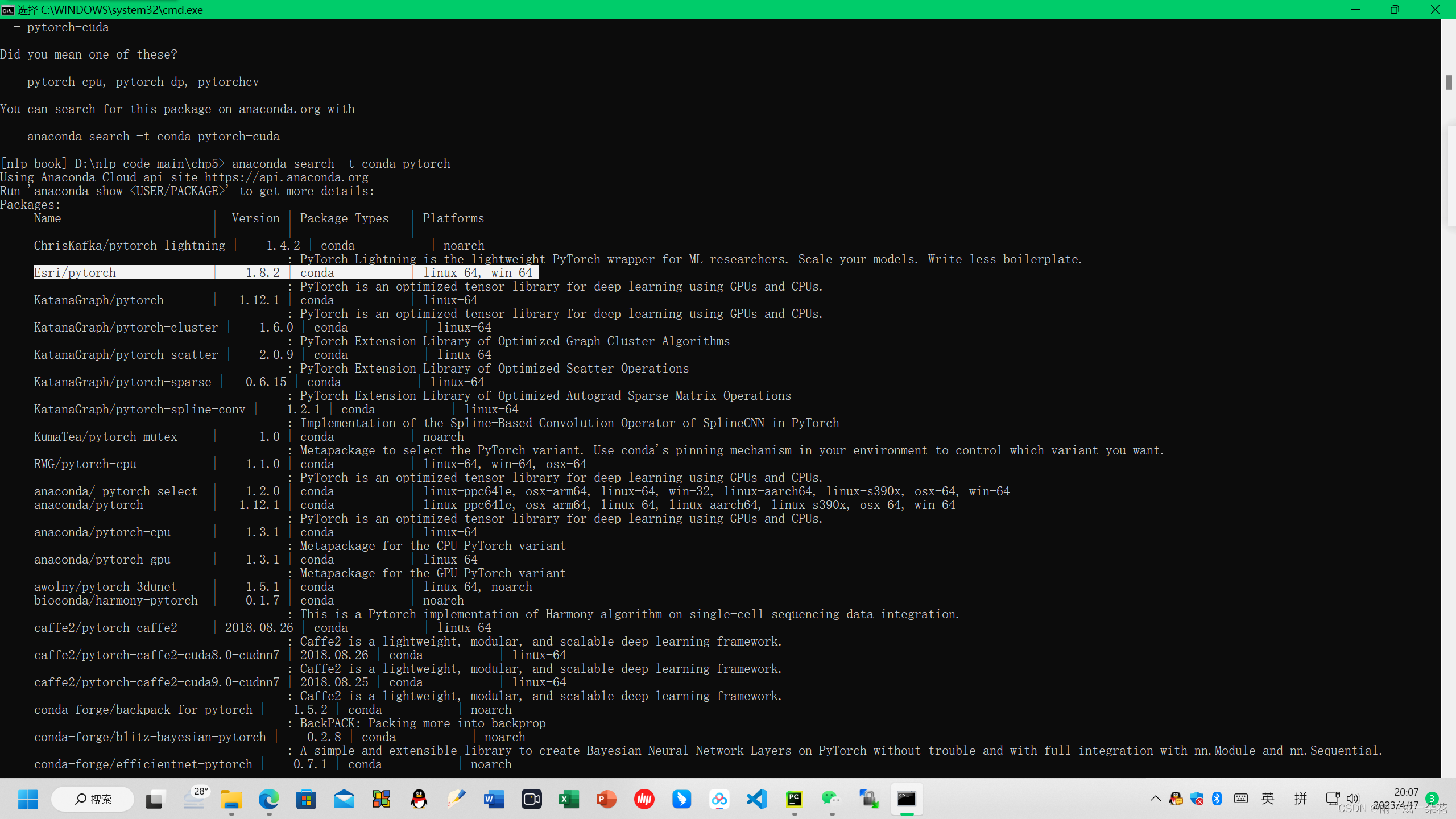
结果只有1.8.2版本,也就是在不同的cuda版本下,对应的pytorch库居然不一样
于是输入安装命令: conda install -c https://conda.anaconda.org/conda-forge pytorch=1.8.2
不断地报错,不断通过类似以下命令安装补全: D:\nlp-code-main\chp5> conda install -c https://conda.anaconda.org/conda-forge python_abi 】
之后,就可以安装pytorch。特别是之前安装的pytorch版本过高,无法兼容新的项目下的pytorch,就必须在虚拟环境下重新安装。
小结:(1)在安装pytorch曾出现多种版本大小不兼容的情况,改了很久无法纠错,于是后来重新卸载anaconda,缘由是自带的python3.5版本,无法满足后面高版本的python所需要的库,重新安装了最新版的anaconda,之后创建虚拟环境,安装pytorch都可以。
** (2)查看安装的版本,pytorch,transformers
import torch
import numpy as np
import transformers
print(torch.version)
print(transformers.version) **
接下来安装模型
conda install transformer=4.9.0
安装时报错:
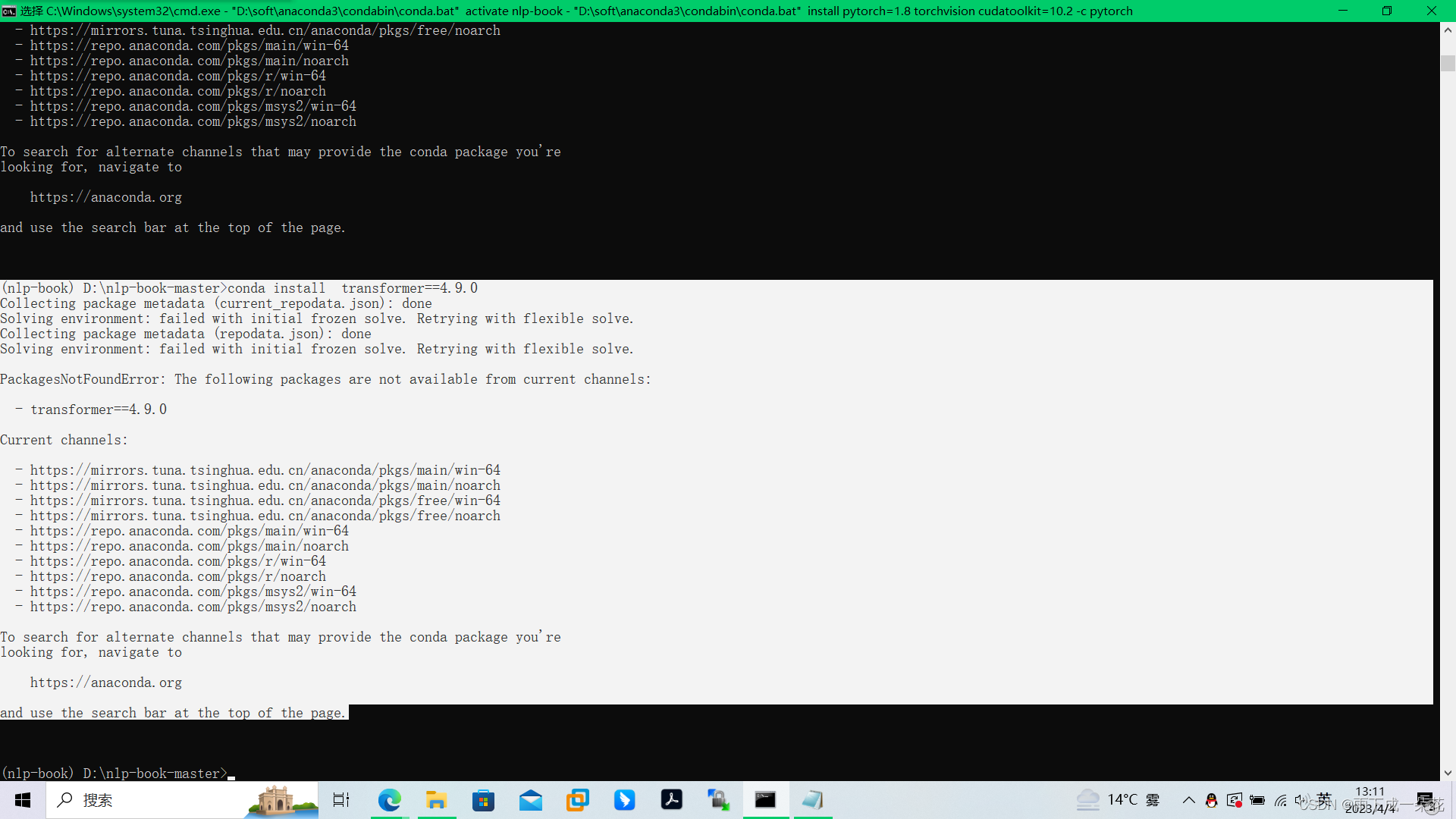
缺乏镜像
执行安装命令
pip install transformers==4.9.0 -i https://pypi.doubanio.com/simple
pip install nltk==3.5 -i https://pypi.doubanio.com/simple
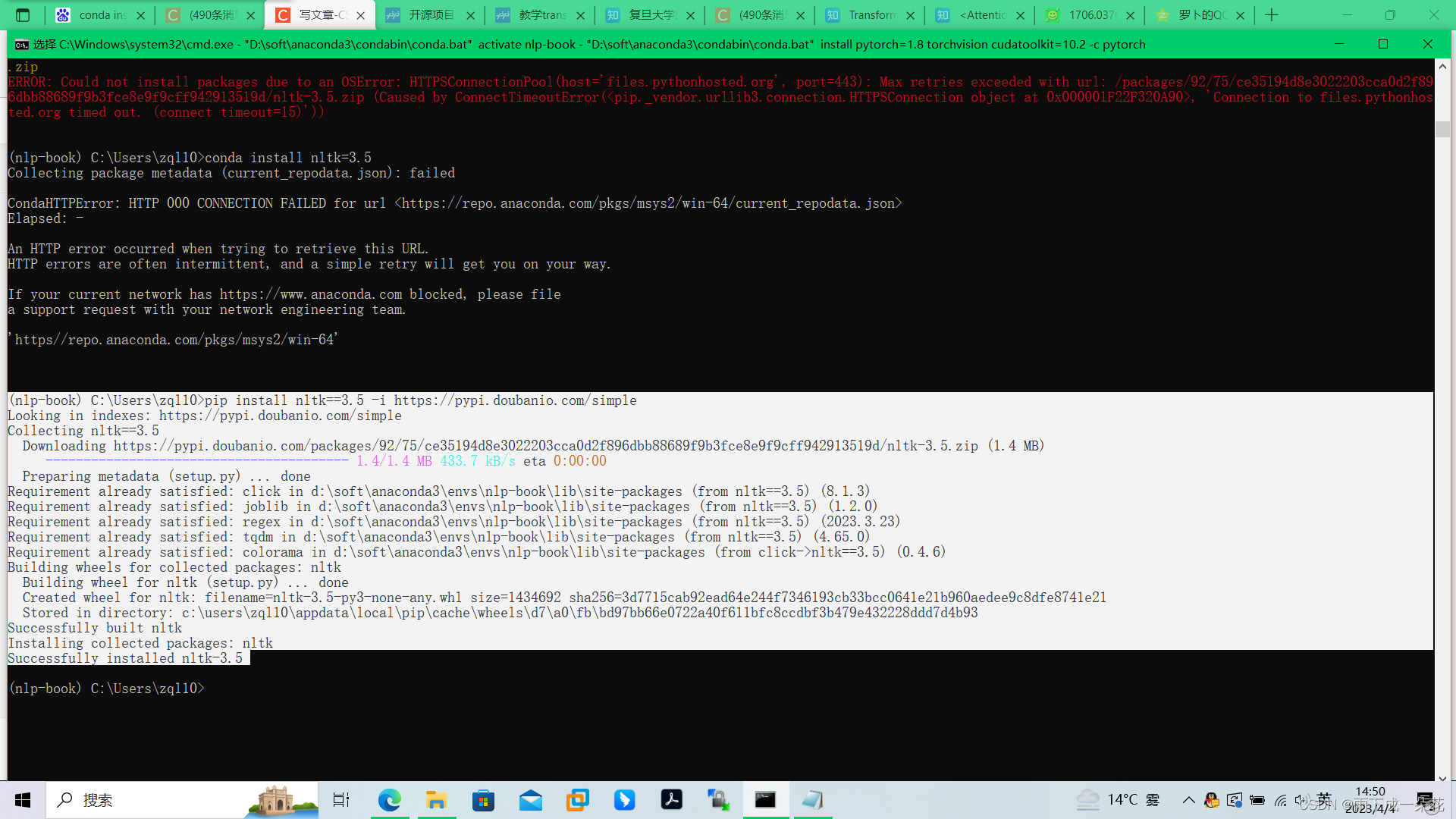
pip install ltp==4.0.2 -i https://pypi.doubanio.com/simple

7)进入项目所在目录
(nlp-book) D:\nlp-book-master\chp4>python transformer_sent_polarity.py
报错

无法在线下载sentence_polarity数据,通常无法下载这个包nltk_data下的很多数据集以及xml文件。一般的方法可以自己下载放到本地目录。链接地址:GitHub - nltk/nltk_data: NLTK Data
于是改正上面报错:
解决方法:
离线下载
github:nltk_data(或pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple)进入清华镜像安装后,也无法安装预训练的情感数据集,于是还是进入gitub下载
GitHub - nltk/nltk_data: NLTK Data,
进入下载页面:/tree/gh-pages/packages/corpora,在corpora下面可以进行下载具体的数据集格式,
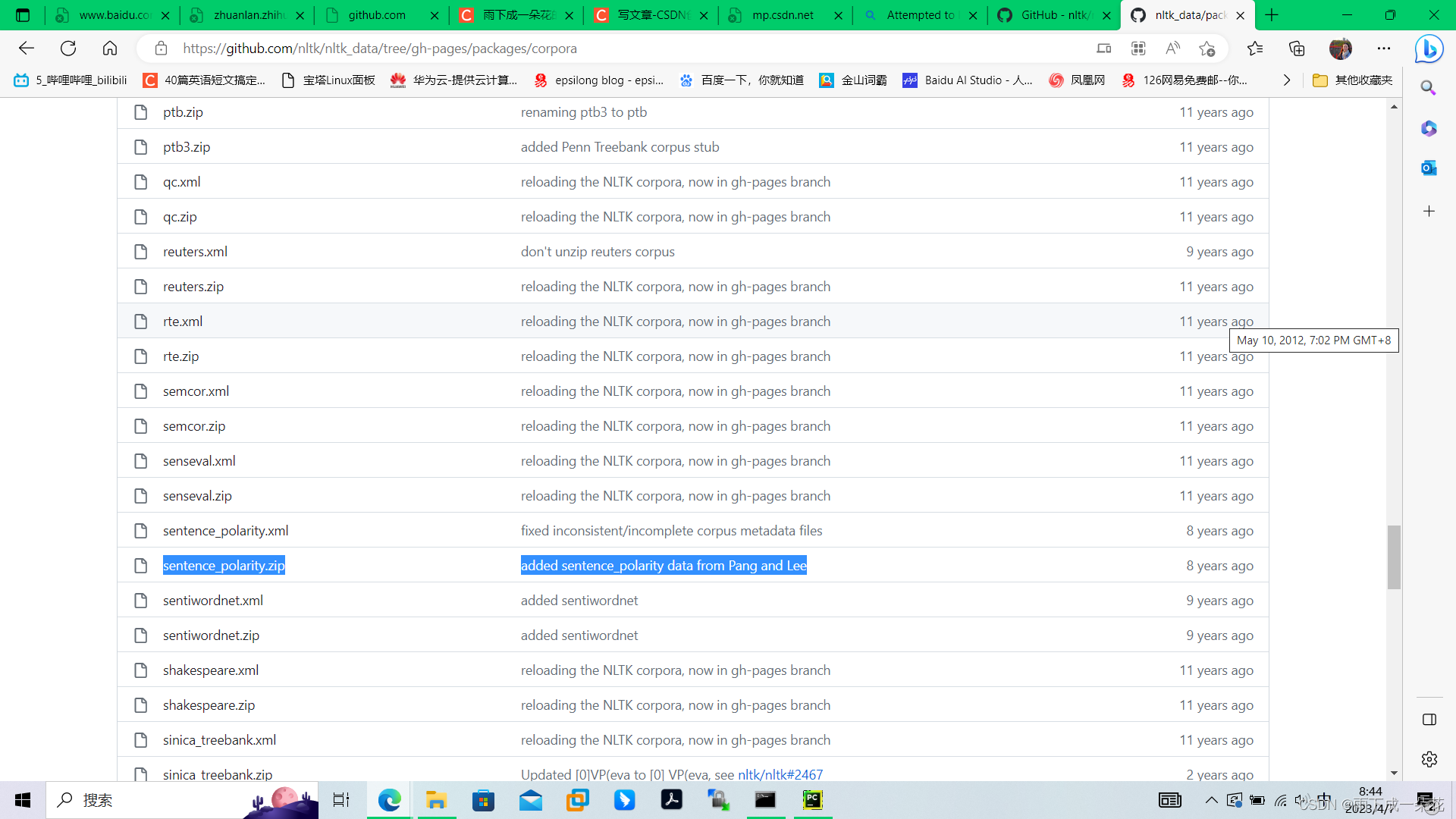
将下载的文件中的sentence_polarity.zip放在上面报错中的目录的任意一个子目录下,程序调用时依次搜寻这些路径,一旦在某个路径下,找到数据格式,即可完成数据的加载。
这里报错是无法加载到数据:
加载数据2023.4.7(见transformers代码)
train_data, test_data, vocab = load_sentence_polarity()
数据包下载后,大概整个nltk_data有706兆,于是把该包放在项目所在的环境目录env下的D:\\soft\\anaconda3\\envs\\nlp-book\\nltk_data下面,之前这里通过清华镜像没有安装到位。这里有个奇怪的现象,进入包的子目录下下载sentence_polarity.zip,无法下载,但是整个包nltk_data可以全部下载到位。这个在上机的实践课上要小心一点。2023.4.7中广班
复制包的数据后重新执行 python transformer_sent_polarity.py还是报错,类似前一个错误,无法加载数据。根据报错提示Attempted to load corpora/sentence_polarity.zip/sentence_polarity/。于是改写路径目录nltk_data/corpora/sentence_polarity
现在可以执行了,也就是可以加载数据了。
**8)训练,测试数据**
加载情感数据集sentence_polarity,然后分割数据集
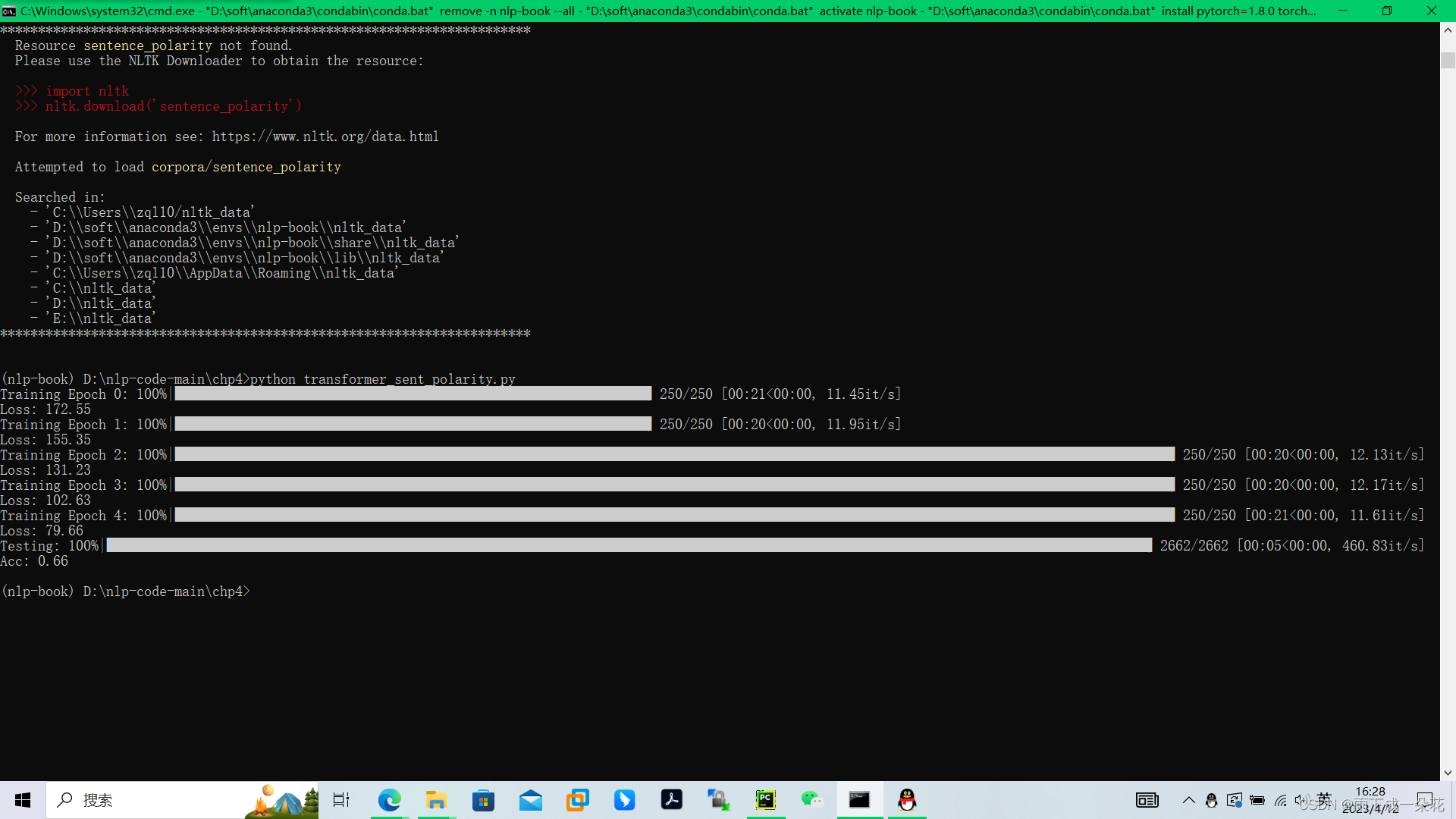

9)结果:
Testing: 100%|██████████| 2662/2662 [00:05<00:00, 468.51it/s]
Acc: 0.68
附录:transformer情感分类代码
import math
import torch
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence
from collections import defaultdict
from vocab import Vocab
from utils import load_sentence_polarity, length_to_mask
tqdm是一个Pyth模块,能以进度条的方式显式迭代的进度
from tqdm.auto import tqdm
class TransformerDataset(Dataset):
def init(self, data):
self.data = data
def len(self):
return len(self.data)
def getitem(self, i):
return self.data[i]
def collate_fn(examples):
lengths = torch.tensor([len(ex[0]) for ex in examples])
inputs = [torch.tensor(ex[0]) for ex in examples]
targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long)
# 对batch内的样本进行padding,使其具有相同长度
inputs = pad_sequence(inputs, batch_first=True)
return inputs, lengths, targets
class PositionalEncoding(nn.Module):
def init(self, d_model, dropout=0.1, max_len=512):
super(PositionalEncoding, self).init()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return x
class Transformer(nn.Module):
def init(self, vocab_size, embedding_dim, hidden_dim, num_class,
dim_feedforward=512, num_head=2, num_layers=2, dropout=0.1, max_len=128, activation: str = "relu"):
super(Transformer, self).init()
# 词嵌入层
self.embedding_dim = embedding_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.position_embedding = PositionalEncoding(embedding_dim, dropout, max_len)
# 编码层:使用Transformer
encoder_layer = nn.TransformerEncoderLayer(hidden_dim, num_head, dim_feedforward, dropout, activation)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)
# 输出层
self.output = nn.Linear(hidden_dim, num_class)
def forward(self, inputs, lengths):
inputs = torch.transpose(inputs, 0, 1)
hidden_states = self.embeddings(inputs)
hidden_states = self.position_embedding(hidden_states)
attention_mask = length_to_mask(lengths) == False
hidden_states = self.transformer(hidden_states, src_key_padding_mask=attention_mask)
hidden_states = hidden_states[0, :, :]
output = self.output(hidden_states)
log_probs = F.log_softmax(output, dim=1)
return log_probs
embedding_dim = 128
hidden_dim = 128
num_class = 2
batch_size = 32
num_epoch = 5
加载数据
train_data, test_data, vocab = load_sentence_polarity()
train_dataset = TransformerDataset(train_data)
test_dataset = TransformerDataset(test_data)
train_data_loader = DataLoader(train_dataset, batch_size=batch_size, collate_fn=collate_fn, shuffle=True)
test_data_loader = DataLoader(test_dataset, batch_size=1, collate_fn=collate_fn, shuffle=False)
加载模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Transformer(len(vocab), embedding_dim, hidden_dim, num_class)
model.to(device) # 将模型加载到GPU中(如果已经正确安装)
训练过程
nll_loss = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(train_data_loader, desc=f"Training Epoch {epoch}"):
inputs, lengths, targets = [x.to(device) for x in batch]
log_probs = model(inputs, lengths)
loss = nll_loss(log_probs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Loss: {total_loss:.2f}")
测试过程
acc = 0
for batch in tqdm(test_data_loader, desc=f"Testing"):
inputs, lengths, targets = [x.to(device) for x in batch]
with torch.no_grad():
output = model(inputs, lengths)
acc += (output.argmax(dim=1) == targets).sum().item()
输出在测试集上的准确率
print(f"Acc: {acc / len(test_data_loader):.2f}")
项目总结:
(1)
在执行代码 python transformer_sent_polarity.py 可能会报错。
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
仔细想了一下,参考了车万翔老师的建议。
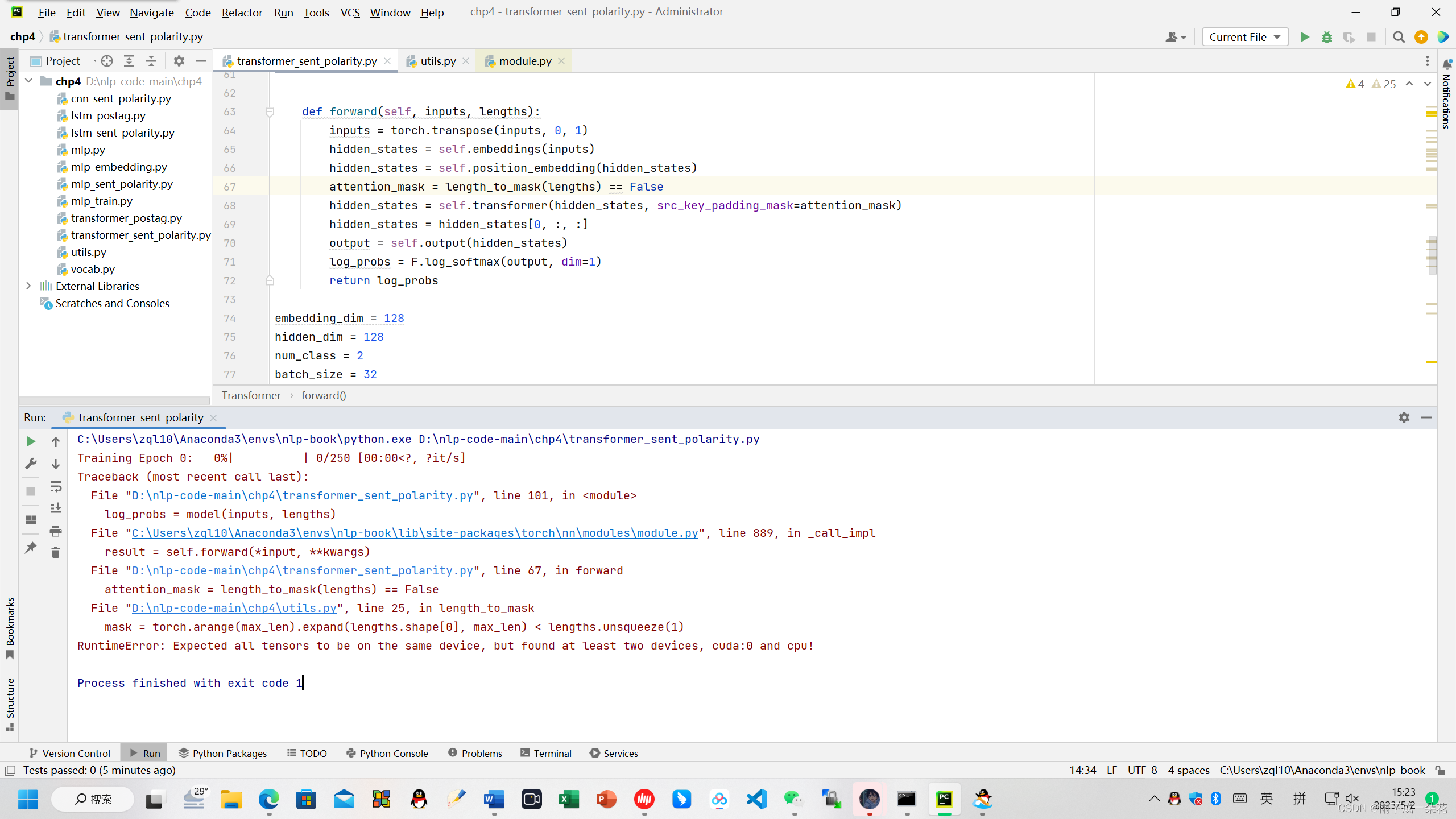
在下列位置修改了代码:
def length_to_mask(lengths):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
max_len = torch.max(lengths)**.to(device)**
mask = torch.arange(max_len).expand(lengths.shape[0], max_len)**.to(device)**< lengths.unsqueeze(1)**.to(device)**
return mask
目的是将torch.arrange(max_len)的设备加载到gpu。然后运行就成功了
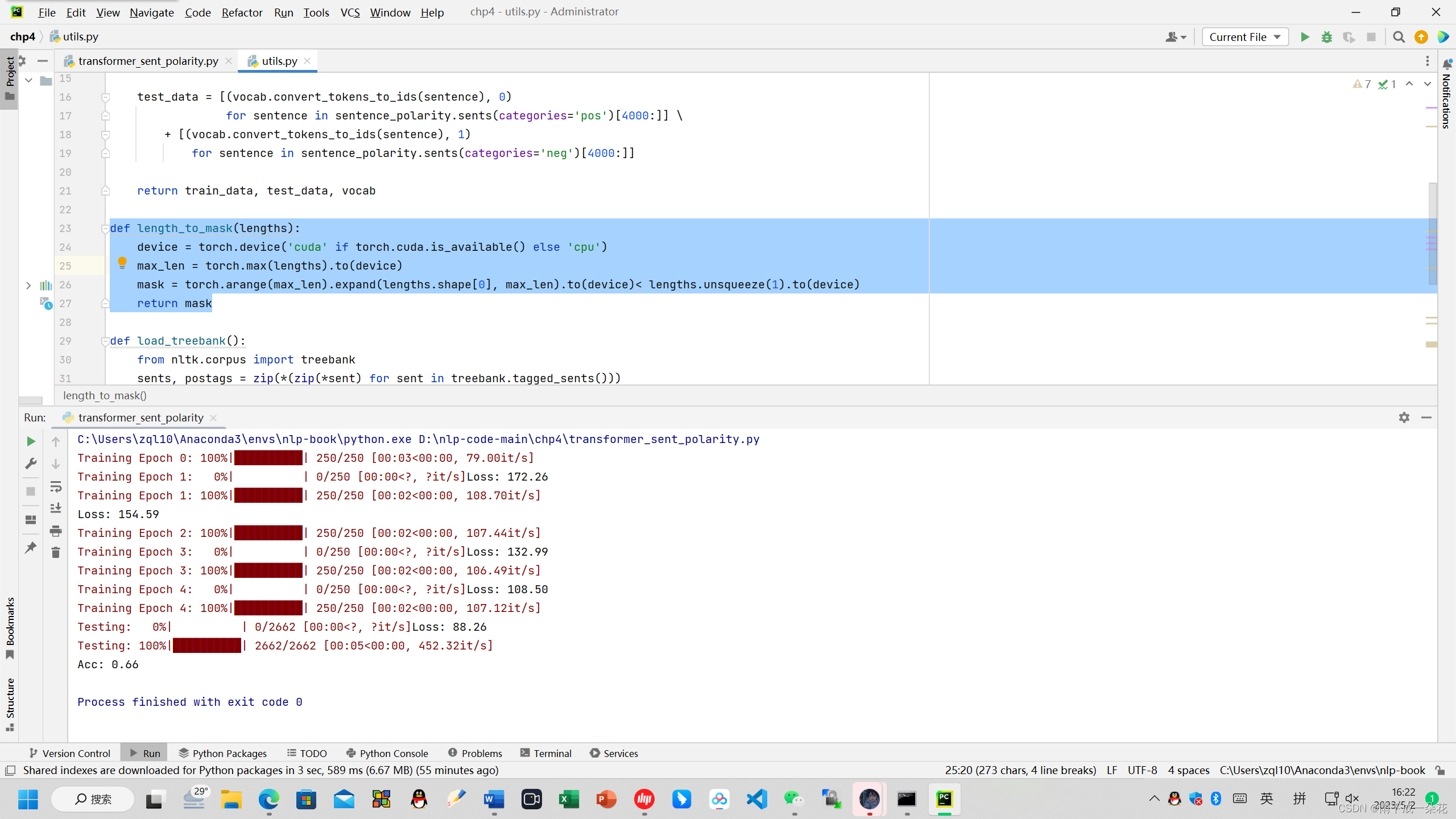
(2) 执行lstm_postag.py 长短期记忆神经网络数据标注时会报错,length是一维的cpu设备计算的,此时必须修改代码:
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(train_data_loader, desc=f"Training Epoch {epoch}"):
inputs, lengths, targets, mask =** [x for x in batch]**
# 因为lengths是cpu设备
** inputs=inputs.to(device)
targets=targets.to(device)**
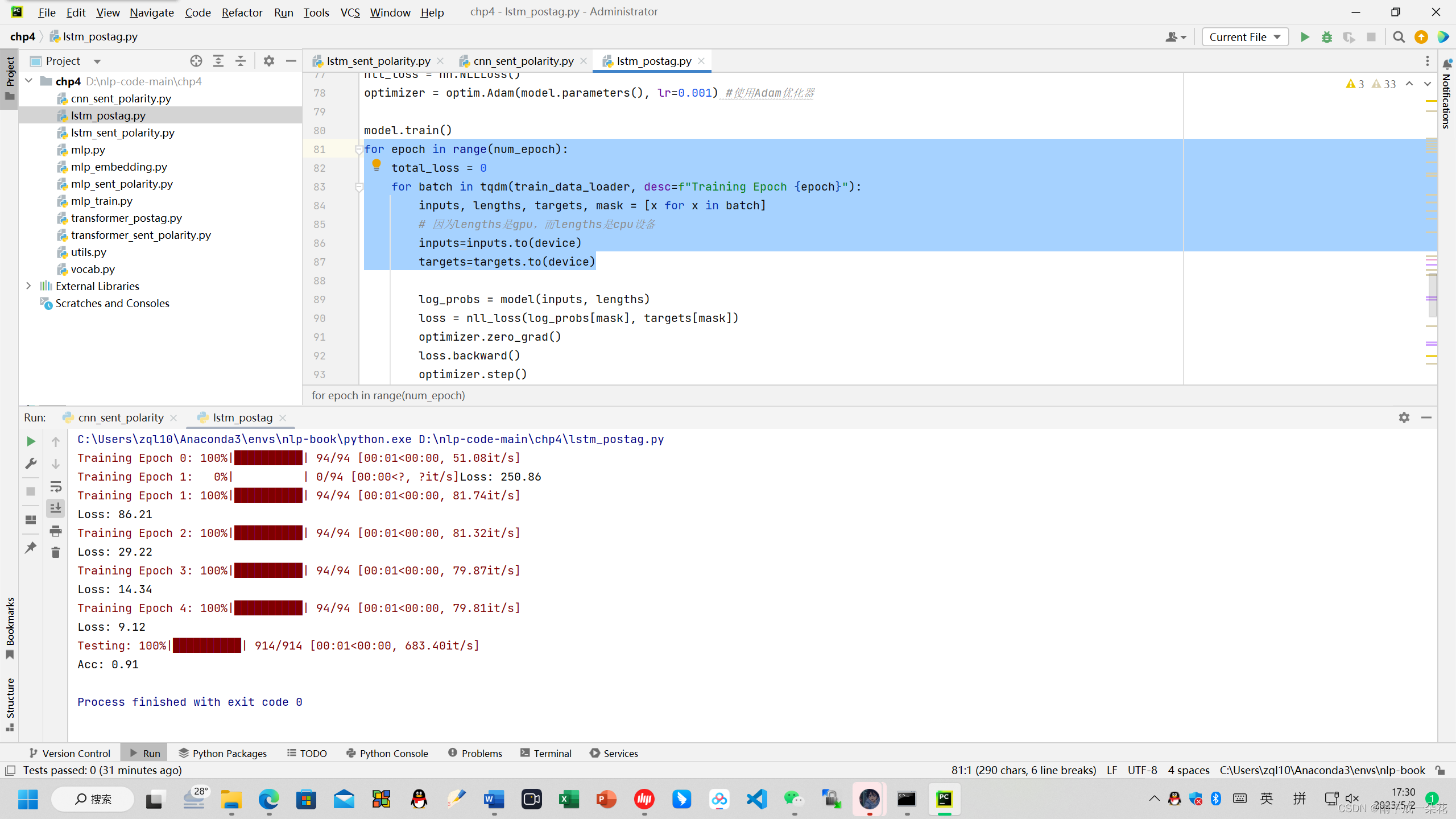
修改后,代码可以完成训练测试标注。
(3)在3070显卡上通过skipgram生成word2vec, 需要十分钟。但是在笔记本上执行要6个小时。

下载修改好的代码:
(363条消息) transformer执行情感分析,CBOW,Skipgram生成词向量代码资源-CSDN文库
版权归原作者 雨下成一朵花 所有, 如有侵权,请联系我们删除。