
💐文章适合于所有的相关人士进行学习💐
🍀各位看官看完了之后不要立刻转身呀🍀
🌿期待三连关注小小博主加收藏🌿
🍃小小博主回关快 会给你意想不到的惊喜呀🍃
各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!
文章目录

🐾前言
上一次在第八式中我们讲解了关于无监督学习得聚类算法,其中包括了K-means算法和DBSCAN聚类算法(密度聚类算法),目的就是为了通过计算和相关知识,将数据点分成一个一个簇,从而进行相关研究,这一部分无论在本科论文或者式研究生论文中做学科交叉都用的比较多,希望各位引起重视,内容属于简单易学,非常适合我们新手进行学习,接下来,我们讲继续讲解关于监督学习得相关内容,其中包括关于决策树得相关内容,我们目标是在决策树单棵树上继续做出改进,得到提升树,来提升预测或者分类得精度。然后我们闲话少叙,进入今天得正题。
😆模型讲解
🌳AdaBoost模型介绍
提升树算法与线性回归模型得思想类似,所不同得是该算法实现了多颗决策树F(x)加权运算,最具有代表性得提升树算法为AdaBoost算法: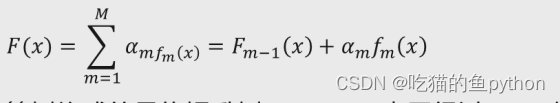
(这里由于我不太会使用富文本编辑器编辑公式,所以只能这样用图片代替公式了。)
其中我们这里做出解释,F(x)是由M棵基础决策树构成得最终提升树,Fm-1(X)表示经过m-1轮迭代后得提升树,am为m棵基础决策树所对应得权重,Fm(X)为m棵基础决策树。
我们通俗一点来讲就是,首先我们利用决策树得相关知识确定一颗基础树,然后接下来给基础树分配权重,然后将正确预测得保留,将预测错误得继续进行预测,然后最终得到理想得预测效果。
每一棵树都是对于前面一棵树结果得优化。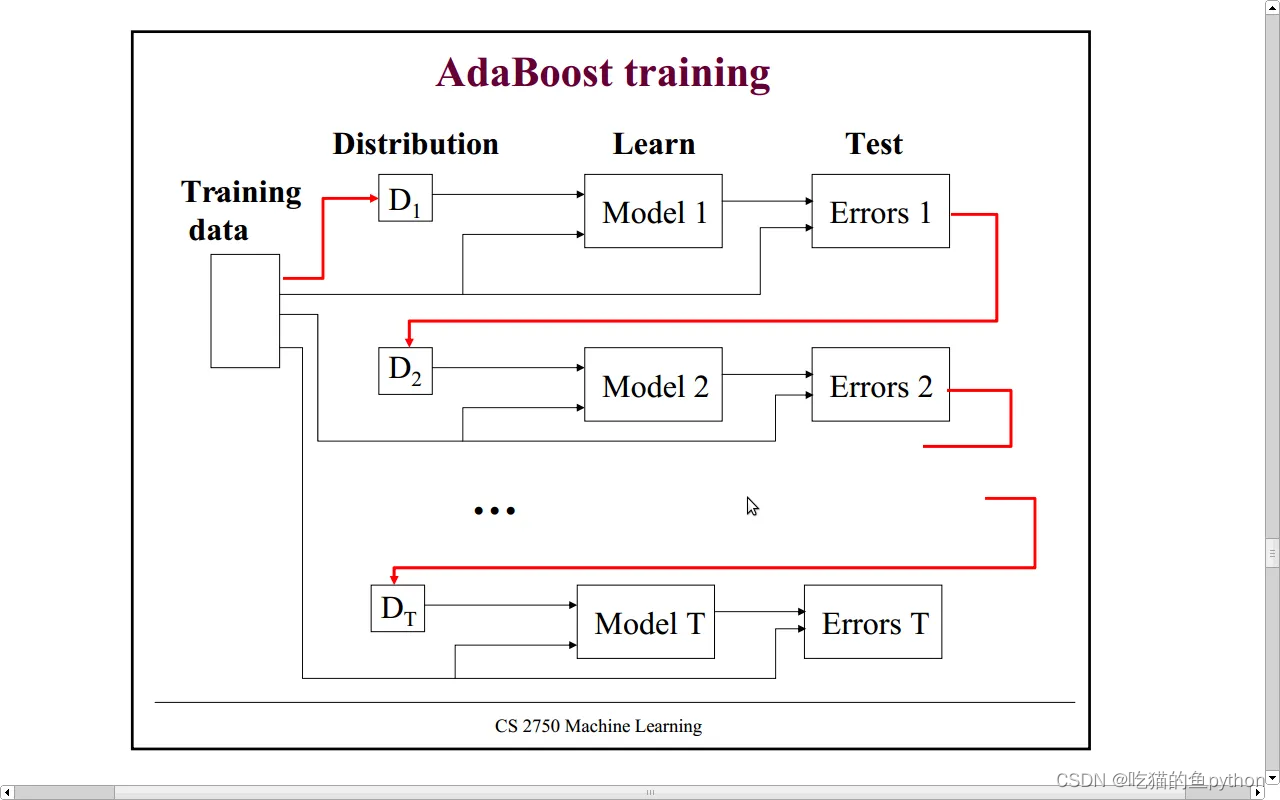
这就是我们关于AdaBoost提升树得一个简单得图形描述。
对于AdaBoost算法而言,每一棵基础决策树都是基于前一棵基础决策树得分类结果对样本设置不同得权重,如果在前一棵基础决策树中将某一个样本点计算错误,就会增大该样本点权重,否则会相应降低样本点得权重,进而构建下一棵基础决策树,继而更加关注权重大得样本点。所以,对于AdaBoost算法我们需要解决得三大难题就是:
1.如何确定样本点权重Wmi。
2.基础决策树f(x)如何选择。
3.每一颗决策树所对应的权重Am该如何计算。
🌳AdaBoost损失函数
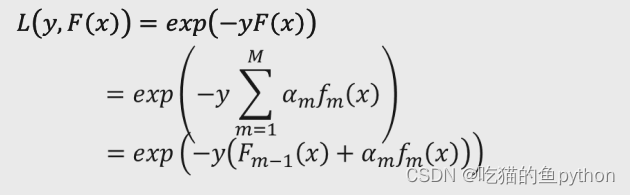
其中y表示实际结果得数值,如果是正例那么表示为+1,如果是负例错误,那么表示-1。对于F(x)表示算法预测得结果,如果预测为正例那么表示为+1,如果预测为负例,那么表示为-1.综上所述:我们可以得到就是关于-yF(x)得结果无非就有两种,+1和-1,那么+1表示原本样本点就是正例样本点,我预测得也恰恰是正例样本点,表示预测正确,那么我们得到的结果是-1,那么做一下指数运算就会得到e得-1次方。同理,如果本来就是负例,我们预测得也是负例子,那么两两相乘得到的结果依旧是+1,那么得到得损失函数结果依旧是e得-1次方。
还有两种情况就是当我们实际是正例,但是我们预测结果是负例或者是实际是负例但是我们得到的预测结果是正例,那么我们得到得-yF(x)的结果就是+1,那么损失函数就是e的+1次方。那么e的-1次方明显比e的+1次方要小,所以如果预测的结果越好,损失函数也就越小。在这里我们将上方的AdaBoost模型的目标函数带入得到了损失函数展开的结果。
如果提升树Fm-1(x)还能够继续提升,就说明了损失函数还能够继续降低,换句话说就是,如果将所有训练样本点带入损失函数中,一定存在一个最佳的参数Am和Fm(x),可以使得损失函数尽量最大化的降低,即: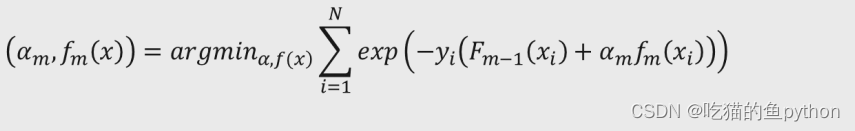
我们将上述公式进行展开,可以发现exp(-yiFm-1(xi))是已知的,所我们可以继续精进一下公式: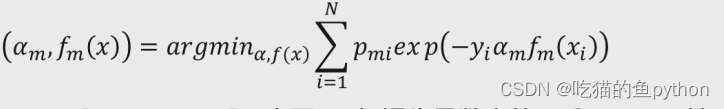
其中Pmi部分就是exp(-yiFm-1(xi)),那么我们可以得到结论,就是接下来我们重点关注点将不会放到Pmi这个部分。会放在后面这个exp(-yiamfm(xi))这一部分上。那么对于exp(-yiamfm(xi))这一部分当m棵基础决策树能够准确预测时,yi与fm(x)的乘积是1,这个我们之间就分析过,否则就为-1,于是对于exp(-yiamfm(xi))的结果无非就是两种,一个是exp(-am),一个是exp(am),对于某一个固定数值am而言,损失函数中的和式仅仅是关于am的式子。所以,要想求得损失函数的最小值,首先我们要找到最佳的Fm(x),使得所有的训练样本点xi带入Fm(x)后,误判结果越少越好,即最佳的fm(x)可以表示为: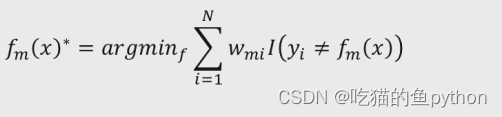
其中,f表示为所有可用的基础决策树空间,目标函数就是从f空间中寻找到的第m轮基础决策树,它能够使加权训练样本点的分类错误率最小,I表示当第m棵基础决策树预测结果与实际值不相等时返回1。
继而继续展开我们可以得到: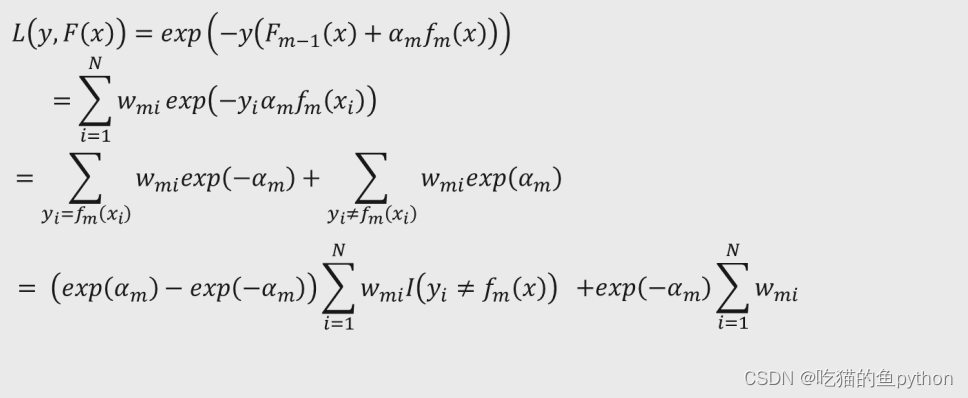
求其偏导数,我们可以到到: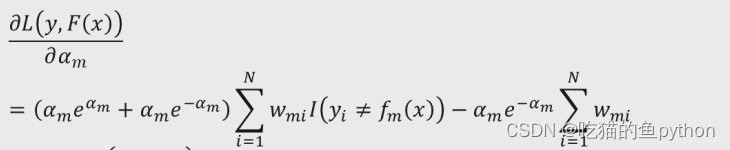
令偏导数等于0:
我们得到参数结果是: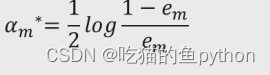
其中: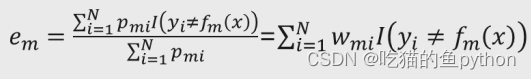
em表示基础决策树m的错误率。
🌳Adaboost算法的具体步骤
1.在每一轮的基础决策树f1(x)的构建中,会设置一个样本点的权重w均为1/N。
2.计算基础决策树fm(x)在训练集上的误判率:
3.计算基础决策树Fm(x)所对应的权重:
4.根据基础决策树Fm(x)的预测结果,计算下一轮用于构建基础决策树的样本点权重Wm+1,i*: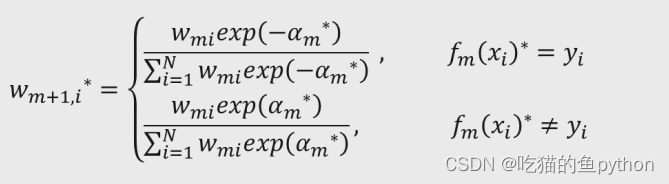
🌳Adaboost算法的函数介绍
🌻Adaboost分类算法
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
1.base_estimator:用于指定提升算法所应用的基础分类器,默认为分类决策树(CART),也可以是其他基础分类器,但是分类器必须支持带样本权重的学习,如神经网络。
2.n_estimators:用于指定基础分类器的数量,默认为50个,当模型在训练集中得到完美的拟合后,可以提前结束算法,不一定非得构建完指定个数的基础分类器。
3.learning_rate:这里指模型迭代的学习率也称为步长,即所对应的提升模型F(x)可以表示为F(x)=Fm-1(x)+vamfm(x),其中v就是该参数的指定值,默认值为1;对于较小的学习率v而言,则需要迭代更多次的基础分类器,通常情况下需要利用交叉验证法确定合理的基础分类器个数和学习率。
4.algorithm:用于指定AdaBoostClassifier分类器的算法,默认为’SAMME.R’,也可以使用 ‘SAMME’;使用’SAMME.R’时,基础模型必须能够计算类别的概率值;一般言,‘SAMME.R’算法 相比于’SAMME’算法,收敛更快、误差更小、迭代数量更少。
5.loss:用于指定AdaBoostRegressor回归提升树的损失函数,可以是’linear’,表示使用线性损失函 数;也可以是’square’,表示使用平方损失函数;还可以是’exponential’,表示使用指数损失函数; 该参数的默认值为’linear’。
6.random_state:用于指定随机数生成器的种子。
🌻Adaboost回归算法
AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None)
🐾GBDT模型讲解
🌳GBDT模型介绍
梯度提升树算法实际上是提升算法的扩展版,在原始的提升算法中,如果损失函数为平方损失或指数 损失,求解损失函数的最小值问题会非常简单,但如果损失函数为更一般的函数,目标值的求解就会相对 复杂很多。GBDT就是用来解决这个问题,利用损失函数的负梯度值作为该轮基础模型损失值的近似,并利 用这个近似值构建下一轮基础模型。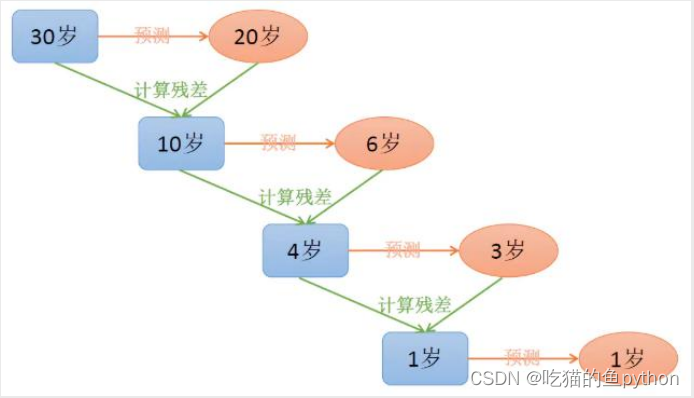
我们这个图就解释了关于GBDT模型的相关概念,首先我们第一个数预测结果是20岁,可是实际结果是30岁,那么我们返回残差值10岁,然后第二棵树预测结果是6岁,那么返回的残差值是4岁,继续预测,直到预测完成。那么这个时候我们将预测的数值反向加和,就得到了最终的预测结果30岁。
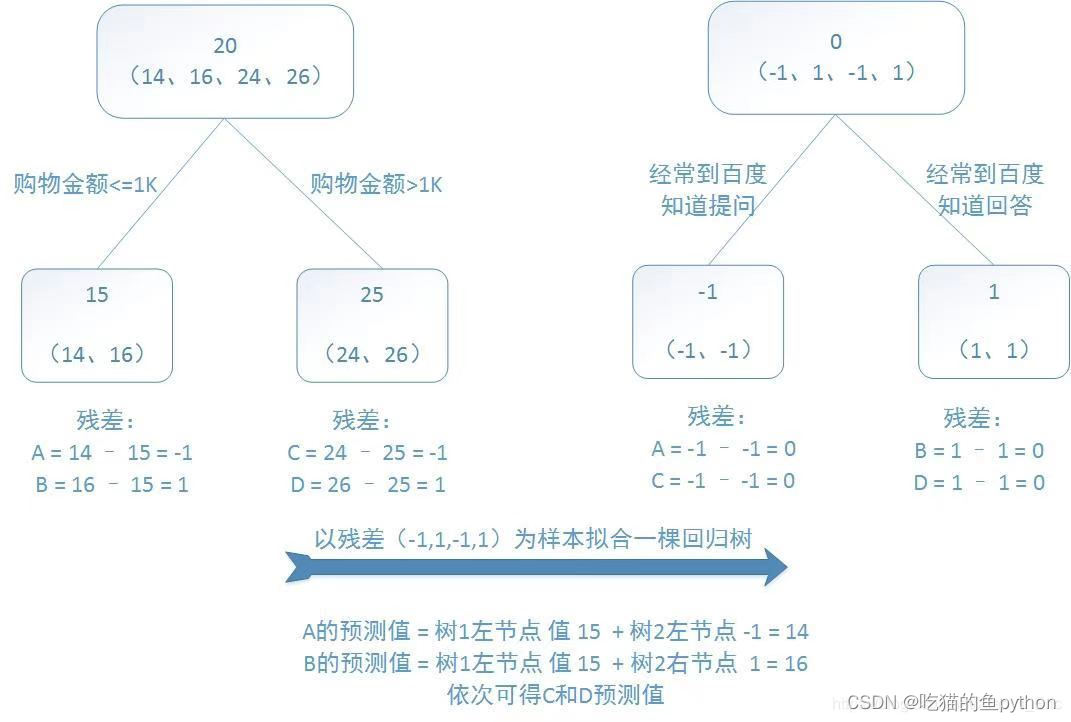
🌳GBDT算法步骤
1.初始化一颗仅仅包含根节点的决策树,并且寻找一个常数Count能够使损失函数达到极小值;
2.计算损失函数的负梯度值,用作残差的估计值: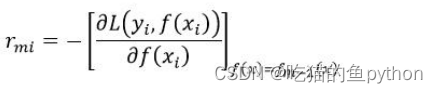
3.利用数据集拟合下一轮基础模型,得到对应的叶子节点,然后计算每一个叶子节点的最佳拟合数值,用作估计残差: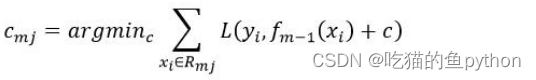
4.进而得到第m轮的基础模型,再结合前面的基础模型,得到最终的梯度提升树模型: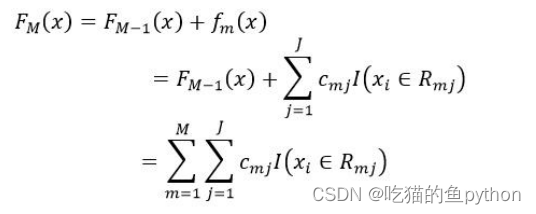
🌳GBDT算法的函数介绍


🐾非平衡数据的特征
在实际应用中,类别型的因变量可能存在严重的偏倚,即类别之间的比例严重失调。如欺诈问题中, 欺诈类观测在样本集中毕竟占少数;客户流失问题中,忠实的客户往往也是占很少一部分;在某营销活动 的响应问题中,真正参与活动的客户也同样只是少部分。
如果数据存在严重的不平衡,预测得出的结论往往也是有偏的,即分类结果会偏向于较多观测的类。 为了解决数据的非平衡问题,2002年Chawla提出了SMOTE算法,即合成少数过采样技术,它是基于随机 过采样算法的一种改进方案。
🌳SMOTE算法的思想
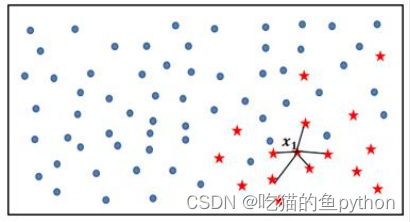
SMOTE算法的基本思想就是对少数类别样本进行分析和 模拟,并将人工模拟的新样本添加到数据集中,进而使原始数 据中的类别不再严重失衡。
🌳SMOTE算法的步骤
1.采样最邻近算法,计算出每个少数类样本的K个近邻。
2. 从K个近邻中随机挑选N个样本进行随机线性插值。
3. 构造新的少数类样本。
4.将新样本与原数据合成,产生新的训练集。
🌳 SMOTE算法的手工案例
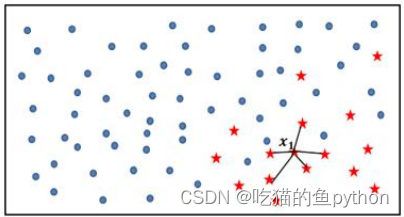
1.首先利用我们所学习过的KNN算法,选择离样本点x1最近的K个同类样本点,我们这里设置为5.
2.从最近的K个同类样本点中,随机挑选M个样本点,我们这里设置为2,M的选择依赖于最终所希望的平衡率。
3.对于每一个随机选中的样本点,构造新的样本点,新样本点的构造公式需要使用下方公式: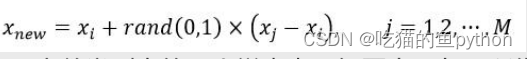
假设图中样本点x1的观测值为(2.3.10.7),从图中5个近邻随机挑选两个样本点,他们的观测值分别是(1.1.5.8)和(2.1.7.6),由此得到两个新样本点为:

4.重复1.2.3步骤,直到模型达到理想的状态。
🌳SMOTE算法的函数介绍
SMOTE(ratio='auto', random_state=None, k_neighbors=5, m_neighbors=10)
ratio:用于指定重抽样的比例,如果指定字符型的值,可以是’minority’(表示对少数类别的样本进 行样)、‘majority’(表示对多数类别的样本进行抽样)、‘not minority’(表示采用欠采样方 法)、‘all’(表示采用过采样方法),默认为’auto’,等同于’all’和’not minority’。如果指定字典型的 值,其中键为各个类别标签,值为类别下的样本量。
random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器。
k_neighbors:指定近邻个数,默认为5个。
m_neighbors:指定从近邻样本中随机挑选的样本个数,默认为10个。

🐾GBDT的改进之XGBoost算法介绍
🌳XGBoost算法的介绍
XGBoost是由传统的GBDT模型发展而来的,GBDT模型在求解最优化问题时应用了一阶导技 术,而XGBoost则使用损失函数的一阶和二阶导,而且可以自定义损失函数,只要损失函数可一阶 和二阶求导。
XGBoost算法相比于GBDT算法还有其他优点,例如支持并行计算,大大提高算法的运行效 率;XGBoost在损失函数中加入了正则项,用来控制模型的复杂度,进而可以防止模型的过拟合; XGBoost除了支持CART基础模型,还支持线性基础模型;XGBoost采用了随机森林的思想,对字段 进行抽样,既可以防止过拟合,也可以降低模型的计算量。
🌳XGBoost损失函数
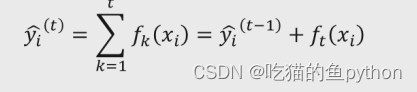
🌳XGBoost目标函数
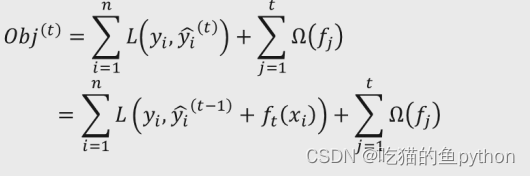
展开的损失函数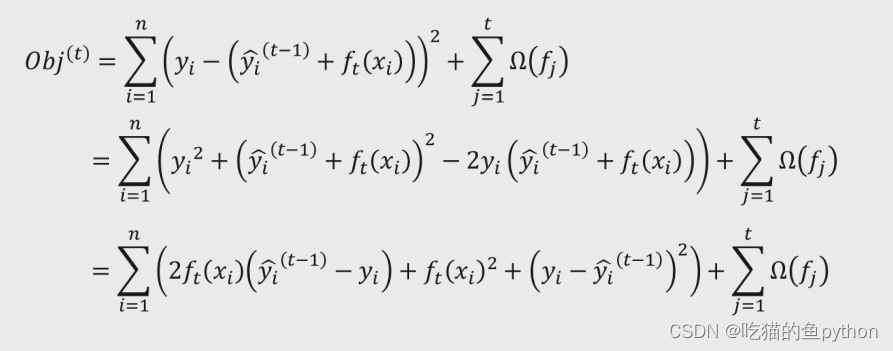
🐾算法实战

🌳画饼状图
# 导入第三方包import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
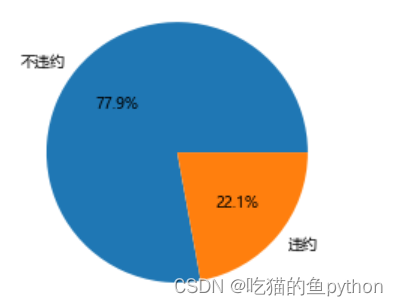
default = pd.read_excel(r'default of credit card.xls')# 数据集中是否违约的客户比例# 为确保绘制的饼图为圆形,需执行如下代码
plt.axes(aspect ='equal')# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False# 统计客户是否违约的频数
counts = default.y.value_counts()# 绘制饼图
plt.pie(x = counts,# 绘图数据
labels=pd.Series(counts.index).map({0:'不违约',1:'违约'}),# 添加文字标签
autopct='%.1f%%'# 设置百分比的格式,这里保留一位小数)# 显示图形
plt.show()
🌳训练拟合
# 导入第三方包from sklearn import model_selection
from sklearn import ensemble
from sklearn import metrics
# 排除数据集中的ID变量和因变量,剩余的数据用作自变量X
X = default.drop(['ID','y'], axis =1)
y = default.y
# 数据拆分
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size =0.25, random_state =1234)# 构建AdaBoost算法的类
AdaBoost1 = ensemble.AdaBoostClassifier()# 算法在训练数据集上的拟合
AdaBoost1.fit(X_train,y_train)# 算法在测试数据集上的预测
pred1 = AdaBoost1.predict(X_test)# 返回模型的预测效果print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred1))print('模型的评估报告:\n',metrics.classification_report(y_test, pred1))
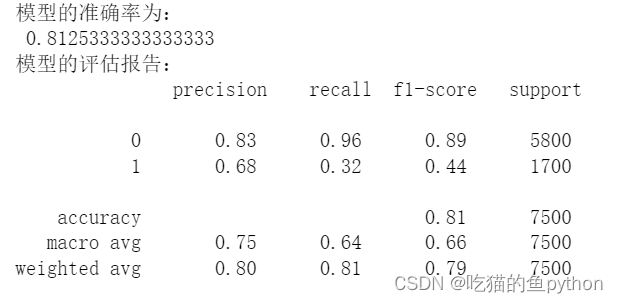
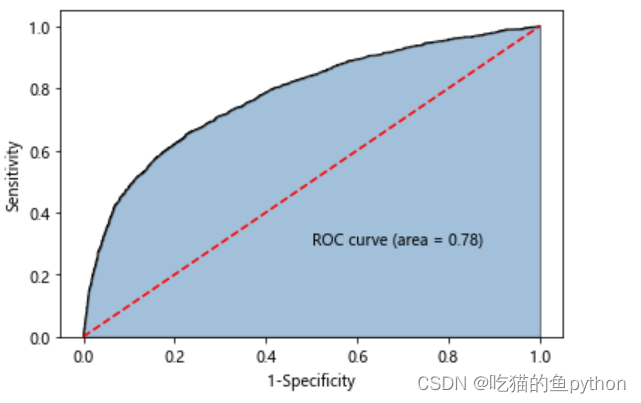
🌳ROC曲线
y_score = AdaBoost1.predict_proba(X_test)[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha =0.5, edgecolor ='black')# 添加边际线
plt.plot(fpr, tpr, color='black', lw =1)# 添加对角线
plt.plot([0,1],[0,1], color ='red', linestyle ='--')# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)'% roc_auc)# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')# 显示图形
plt.show()
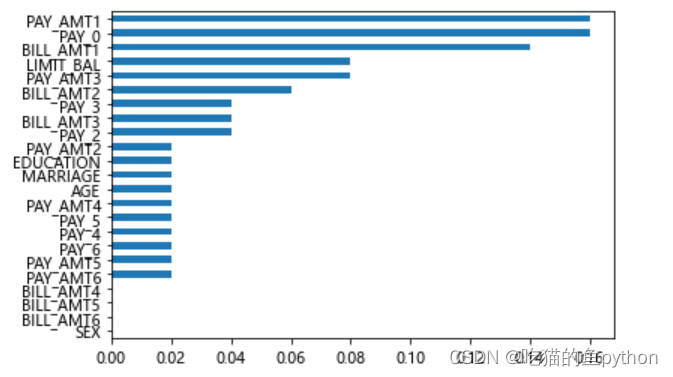
🌳重要性排序
importance = pd.Series(AdaBoost1.feature_importances_, index = X.columns)
importance.sort_values().plot(kind ='barh')
plt.show()
🌳网格搜索法确定参数
predictors =list(importance[importance>0.02].index)
predictors
# 通过网格搜索法选择基础模型所对应的合理参数组合# 导入第三方包from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
max_depth =[3,4,5,6]
params1 ={'base_estimator__max_depth':max_depth}
base_model = GridSearchCV(estimator = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier()),
param_grid= params1, scoring ='roc_auc', cv =5, n_jobs =4, verbose =1)
base_model.fit(X_train[predictors],y_train)# 返回参数的最佳组合和对应AUC值
base_model.best_params_, base_model.best_score_
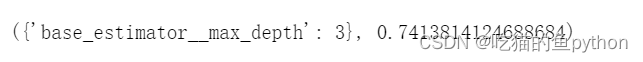
🌳使用参数拟合模型
AdaBoost2 = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth =3),
n_estimators =300, learning_rate =0.01)# 算法在训练数据集上的拟合
AdaBoost2.fit(X_train[predictors],y_train)# 算法在测试数据集上的预测
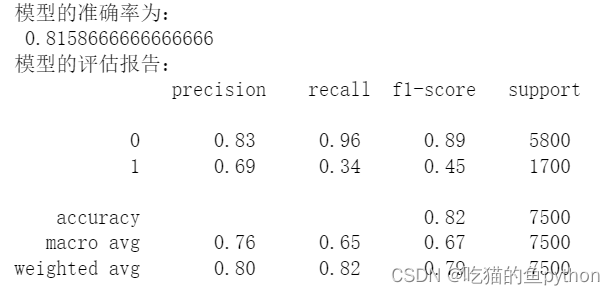
pred2 = AdaBoost2.predict(X_test[predictors])# 返回模型的预测效果print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred2))print('模型的评估报告:\n',metrics.classification_report(y_test, pred2))
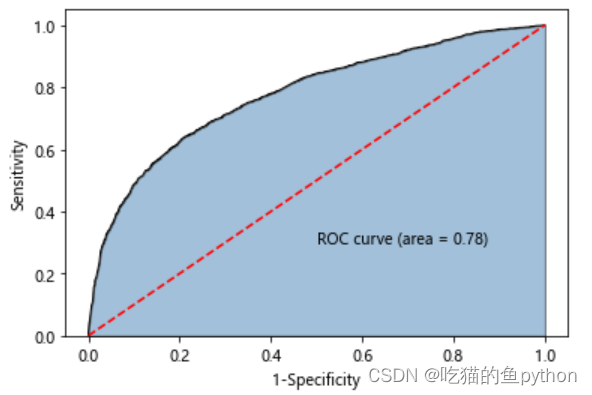
🌳绘制ROC
y_score = AdaBoost2.predict_proba(X_test[predictors])[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha =0.5, edgecolor ='black')# 添加边际线
plt.plot(fpr, tpr, color='black', lw =1)# 添加对角线
plt.plot([0,1],[0,1], color ='red', linestyle ='--')# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)'% roc_auc)# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')# 显示图形
plt.show()
🌳梯度提升树确定参数
learning_rate =[0.01,0.05,0.1,0.2]
n_estimators =[100,300,500]
max_depth =[3,4,5,6]
params ={'learning_rate':learning_rate,'n_estimators':n_estimators,'max_depth':max_depth}
gbdt_grid = GridSearchCV(estimator = ensemble.GradientBoostingClassifier(),
param_grid= params, scoring ='roc_auc', cv =5, n_jobs =4, verbose =1)
gbdt_grid.fit(X_train[predictors],y_train)# 返回参数的最佳组合和对应AUC值
gbdt_grid.best_params_, gbdt_grid.best_score_
🌳梯度提升树进行预测
pred = gbdt_grid.predict(X_test[predictors])# 返回模型的预测效果print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred))print('模型的评估报告:\n',metrics.classification_report(y_test, pred))
🌳ROC曲线
y_score = gbdt_grid.predict_proba(X_test[predictors])[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha =0.5, edgecolor ='black')# 添加边际线
plt.plot(fpr, tpr, color='black', lw =1)# 添加对角线
plt.plot([0,1],[0,1], color ='red', linestyle ='--')# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)'% roc_auc)# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')# 显示图形
plt.show()
🌳SMOTE算法训练
from imblearn.over_sampling import SMOTE
# 运用SMOTE算法实现训练数据集的平衡
over_samples = SMOTE(random_state=1234)# over_samples_X,over_samples_y = over_samples.fit_sample(X_train, y_train)
over_samples_X, over_samples_y = over_samples.fit_sample(X_train.values,y_train.values.ravel())# 重抽样前的类别比例print(y_train.value_counts()/len(y_train))# 重抽样后的类别比例print(pd.Series(over_samples_y).value_counts()/len(over_samples_y))
🌳XGBoost算法训练
import xgboost
import numpy as np
# 构建XGBoost分类器
xgboost = xgboost.XGBClassifier()# 使用重抽样后的数据,对其建模
xgboost.fit(over_samples_X,over_samples_y)# 将模型运用到测试数据集中
resample_pred = xgboost.predict(np.array(X_test))# 返回模型的预测效果print('模型的准确率为:\n',metrics.accuracy_score(y_test, resample_pred))print('模型的评估报告:\n',metrics.classification_report(y_test, resample_pred))
🌳ROC曲线
y_score = xgboost.predict_proba(np.array(X_test))[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha =0.5, edgecolor ='black')# 添加边际线
plt.plot(fpr, tpr, color='black', lw =1)# 添加对角线
plt.plot([0,1],[0,1], color ='red', linestyle ='--')# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)'% roc_auc)# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')# 显示图形
plt.show()

💐文章适合于所有的相关人士进行学习💐
🍀各位看官看完了之后不要立刻转身呀🍀
🌿期待三连关注小小博主加收藏🌿
🍃小小博主回关快 会给你意想不到的惊喜呀🍃
各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!
版权归原作者 吃猫的鱼python 所有, 如有侵权,请联系我们删除。