
Title: H4D: Human 4D Modeling by Learning Neural Compositional Representation
Author: 1 Fudan University 2 Google
Abstract: 点云序列输入,利用参数模型重建。
Paper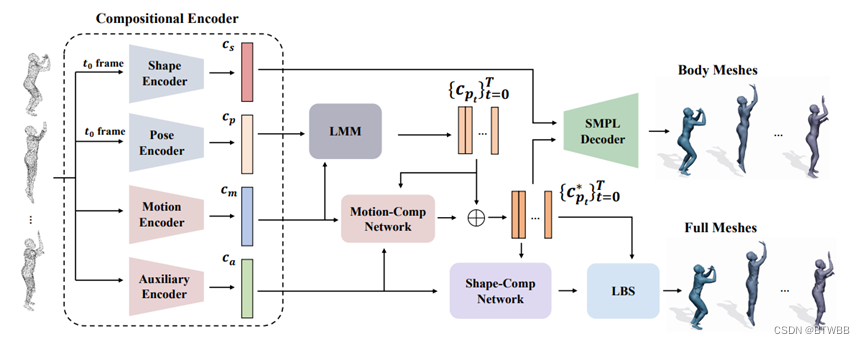
Title: PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence
Author: 1 ETH Zürich, 2 University of Tübingen,3 Max Planck Institute for Intelligent Systems, Tübingen
Abstract: RGB-D输入,核心思想是将深度图融合为一个单一的、一致的表示,并同时学习关节驱动的变形。为此,本文将穿着衣服的人的三维曲面参数化为姿势条件隐式带符号距离场(SDF)和正则空间中的学习变形场。
Paper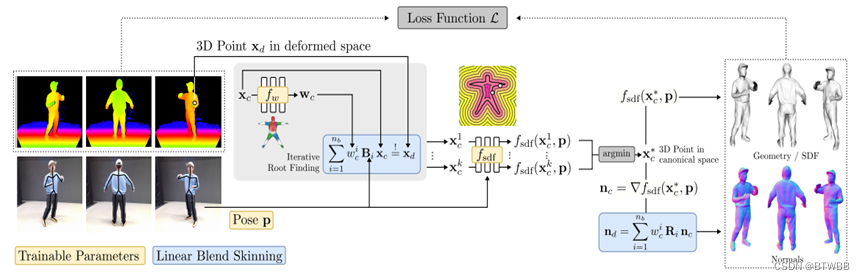
Title: SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
Author: 1University of Science and Technology of China 2 Image Derivative Inc 3Zhejiang University
Abstract: 单目video输入,本文结合显示表征和隐式表征的优点。其利用显式网格的差分掩模损失来获得连贯的整体形状,而隐式曲面的细节则通过可微神经渲染来细化。
Paper
Code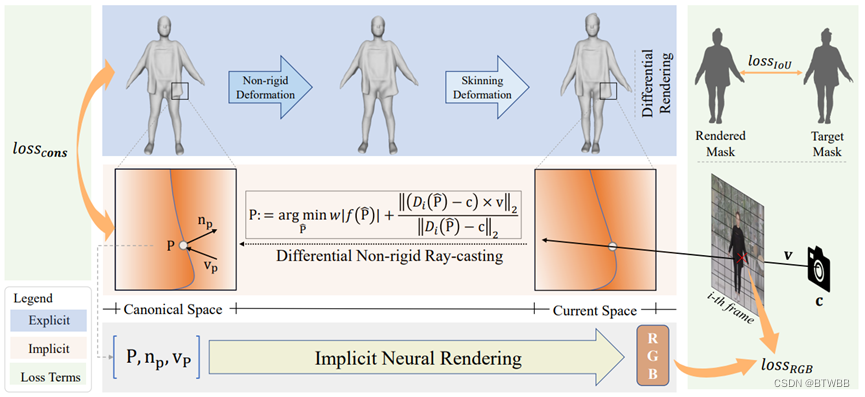
Title: Surface-Aligned Neural Radiance Fields for Controllable 3D Human Synthesis
Author: The University of Tokyo
Abstract: 多目video输入,神经辐射场合成新视角和新的姿态。
Paper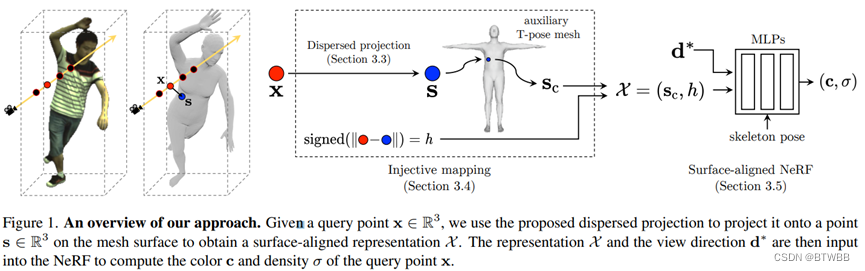
Title: OSSO: Obtaining Skeletal Shape from Outside
Author: 1Max Planck Institute for Intelligent Systems, Tubingen, Germany
Abstract: 本文作者考虑了如何从人体表面预测内部生理学骨架的问题,其在医学和生物力学中有众多应用。作者首先建立了一个包含2000多名男性、女性的人体网格-骨架的数据对,从这些数据构造了一个标准姿态下的人体骨架数据,并提出了一种从任意姿态的人体网格预测其对应骨架的方法!
Paper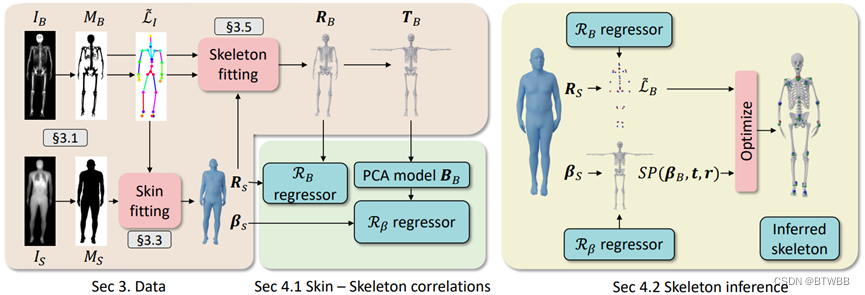
Title: Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing(PHORHUM)
Author: Google Research
Abstract: 单张图片输入,诸如 PIFu、PIFuHD、PAMIR、ARCH、ARCH++ 等众多优秀方法都存在一些问题,这些方法都包含多个步骤,需要先计算一些中间表示,这就给计算和内存提出了更高要求。在大多数现有方法中,颜色都是在几何之后的步骤估计的,但从方法论的角度来看,本文作者认为应该同时计算几何形状和表面颜色,因为阴影 (shading) 是表面几何的一个强有力的线索,且无法解耦。
Paper
Other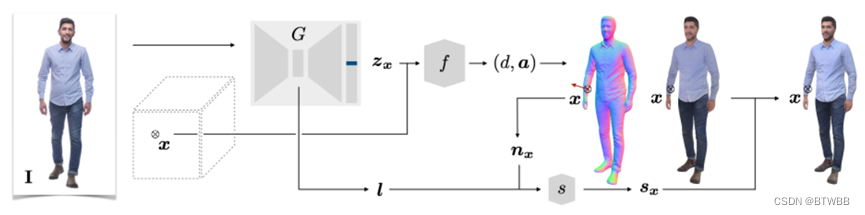
Title: ICON: Implicit Clothed humans Obtained from Normals
Author: Max Planck Institute for Intelligent Systems, Tubingen, Germany
Abstract: 图片输入,扔掉global encoder,SMPL辅助normal预测,normal帮助优化SMPL。
Paper
Code
Other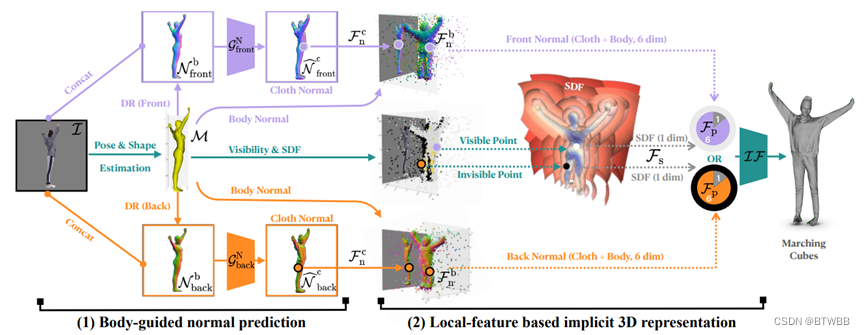
Title: KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoint
Author: 1ETH Z¨urich 2Reality Labs Research
Abstract: 多张图片输入,通过稀疏的3D关节点检测生成三维空间信息,进而生成新的pose,或者视角图像;
Paper
Code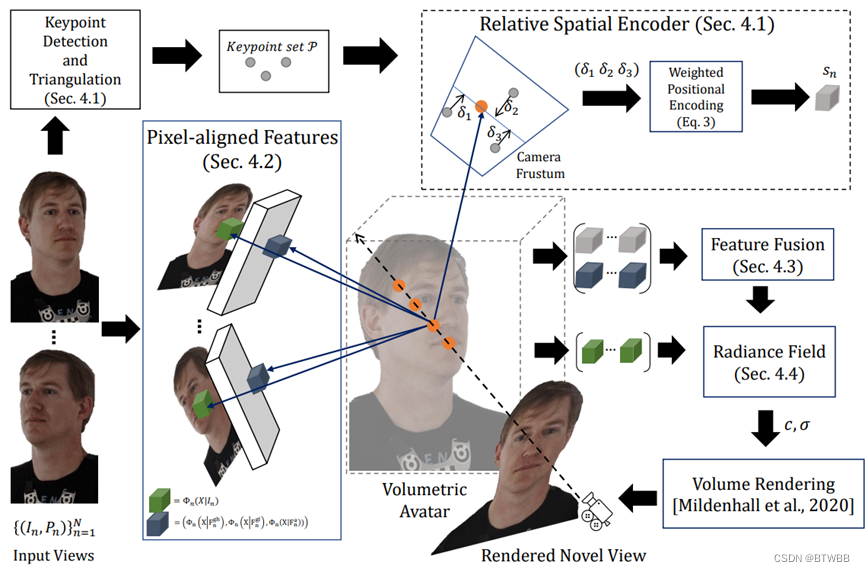
Title: gDNA: Towards Generative Detailed Neural Avatars
Author: 1ETH Zurich, Department of Computer Science ¨ 2University of Tubingen ¨ 3Max Planck Institute for Intelligent Systems, Tubingen
Abstract: 本文通过扫描的人体,统计学习了一个可以表现细节的生成式模型;
Paper
Code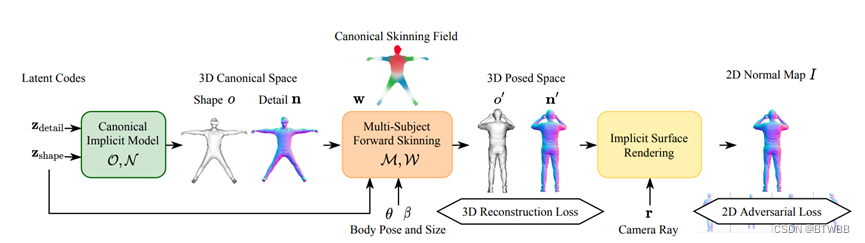
Title: DoubleField: Bridging the Neural Surface and Radiance Fields for High-fidelity Human Reconstruction and Rendering
Author: 1Tsinghua University 2Beihang University 3Kuaishou Technology
Abstract: 多目图像输入,本文介绍了一种结合表面场和辐射场优点的新框架DoubleField,用于高保真的人体重建和渲染。在DoubleField中,表面场和辐射场通过共享特征嵌入和表面引导采样策略联系在一起。此外,还引入了一个视图-视图转换器来融合多视图特征,并从高分辨率输入中直接学习与视图相关的特征。
Paper
Code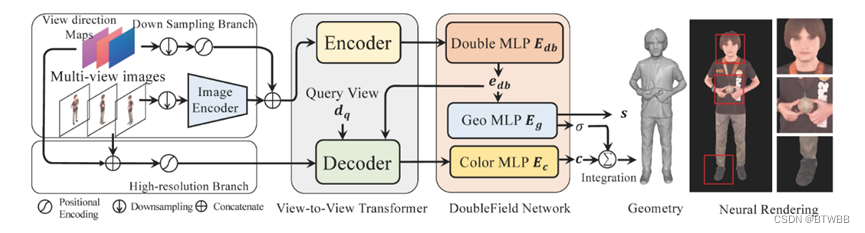
Title: High-Fidelity Human Avatars from a Single RGB Camera(HF-Avatar)
Author: 1Tianjin University, China 2Cardiff University, United Kingdom 3Tsinghua University, China 4VRC Inc., Japan
Abstract: 单目视频输入(A-pose旋转),本文提出了一个由粗到细的框架来从单目视频中重建一个个性化的高保真的人体模型。针对不同帧中姿态和形状变化导致问题,本文设计了一个动态曲面网络来恢复与姿态相关的曲面变形,这有助于解耦人的形状和纹理。为了处理纹理的复杂性并生成逼真的纹理结果,本文提出了一种基于参考的神经绘制网络,并利用一种自下而上的锐化引导微调策略来获得详细的纹理。
Paper
Code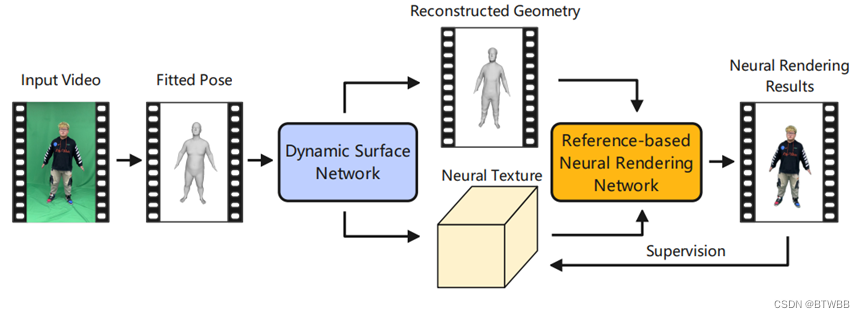
Title: Structured Local Radiance Fields for Human Avatar Modeling
Author: 1Tsinghua University 2OPPO Research Institute
Abstract: 多目视频输入,本文提出了一种新的表示,表示的核心是一组结构化的局部辐射场,它们被锚定在统计人体模板上采样的预定义节点上。这些局部辐射场不仅利用了形状和外观建模中隐式表示的灵活性,而且还将布料变形分解为骨架运动、节点剩余平移和每个辐射场内部的动态细节变化。
Paper
Other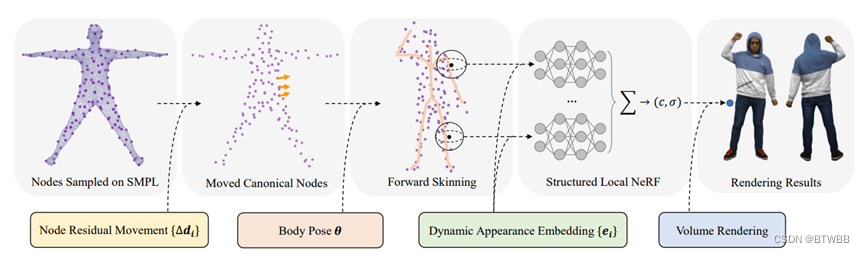
Title: OcclusionFusion: Occlusion-aware Motion Estimation for Real-time Dynamic 3D Reconstruction
Author: School of Software and BNRist, Tsinghua University
Abstract: RGBD为输入,Fusion系列,解决了由于遮挡产生的累计误差。
Paper
Code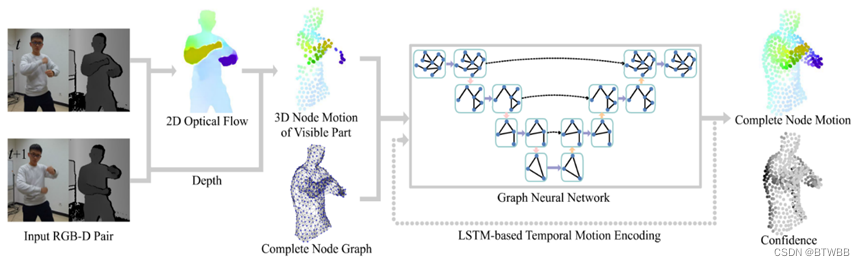
Title: Learning Motion-Dependent Appearance for High-Fidelity Rendering of Dynamic Humans from a Single Camera
Author: †University of Minnesota ♯Adobe Research
Abstract: 单目RGB视频输入,本文想法是穿着的人的外表会经历复杂的变化,这不仅仅是由静态姿势引起的,也受其动力学的影响。
Paper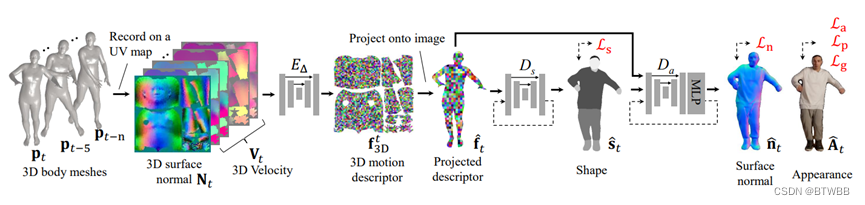
Title: JIFF: Jointly-aligned Implicit Face Function for High Quality Single View Clothed Human Reconstruction
Author: 1The University of Hong Kong 2The Future Network of Intelligence Institute (FNii), CUHK-Shenzhen
Abstract: RGB输入,继承隐函数PIFuHD重建,解决脸部细节刻画问题;
Paper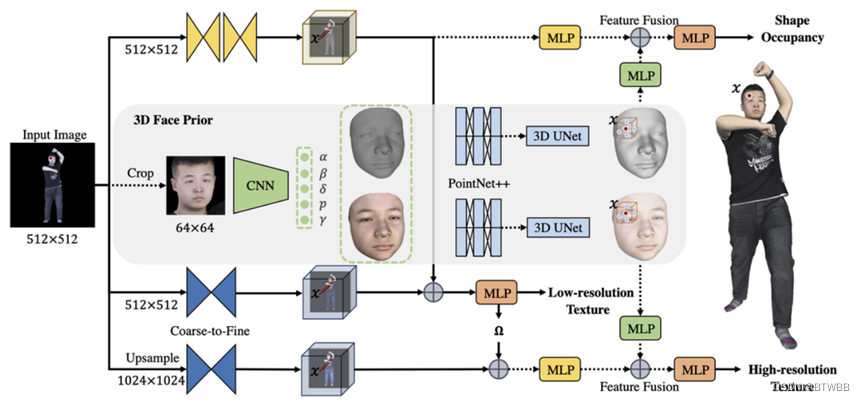
Title: Human Mesh Recovery From Multiple Shots
Author: University of California, Berkeley
Abstract: 解决从多摄像头拍摄的同一对象的视频序列中优化参数模型。
Paper

Title: Occluded Human Mesh Recovery
Author: 1Carnegie Mellon University 2Max Planck Institute for Intelligent Systems, Tubingen
Abstract: 单目RGB输入,解决多人相互遮挡,重建参数模型。
Paper
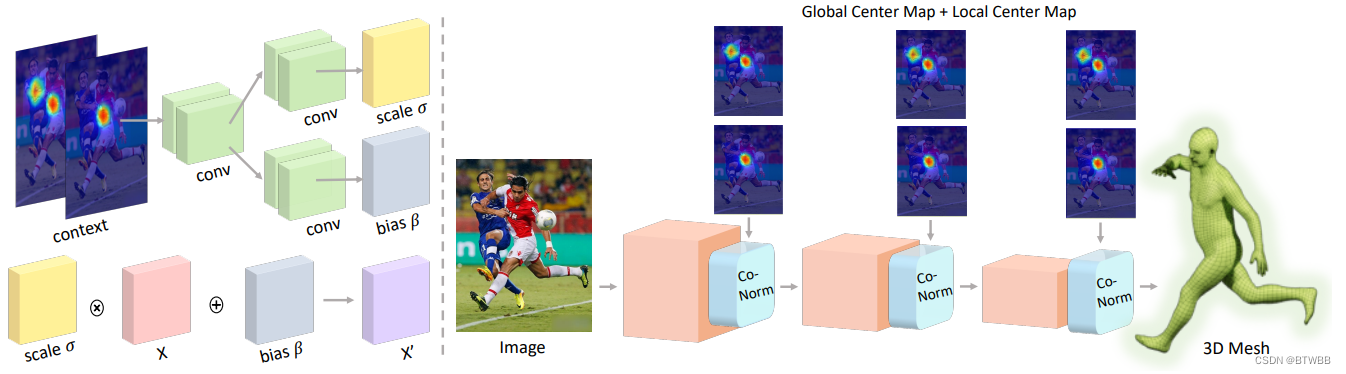
Title: H4D: Human 4D Modeling by Learning Neural Compositional Representation
Author: 1Fudan University 2Google
Abstract: 输入是点云序列,利用参数模型的先验信息,重建精细的人体模型。
Paper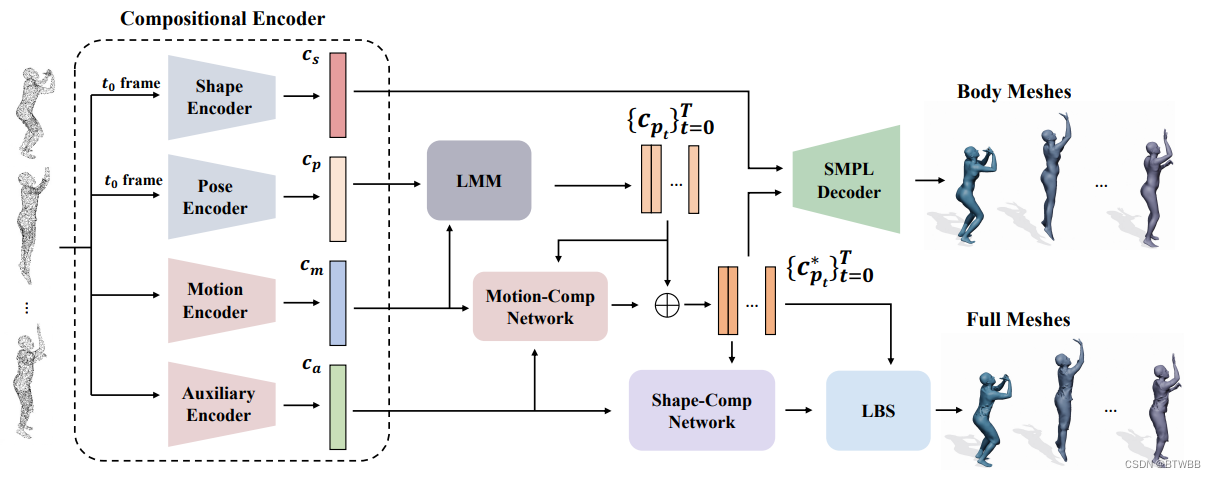
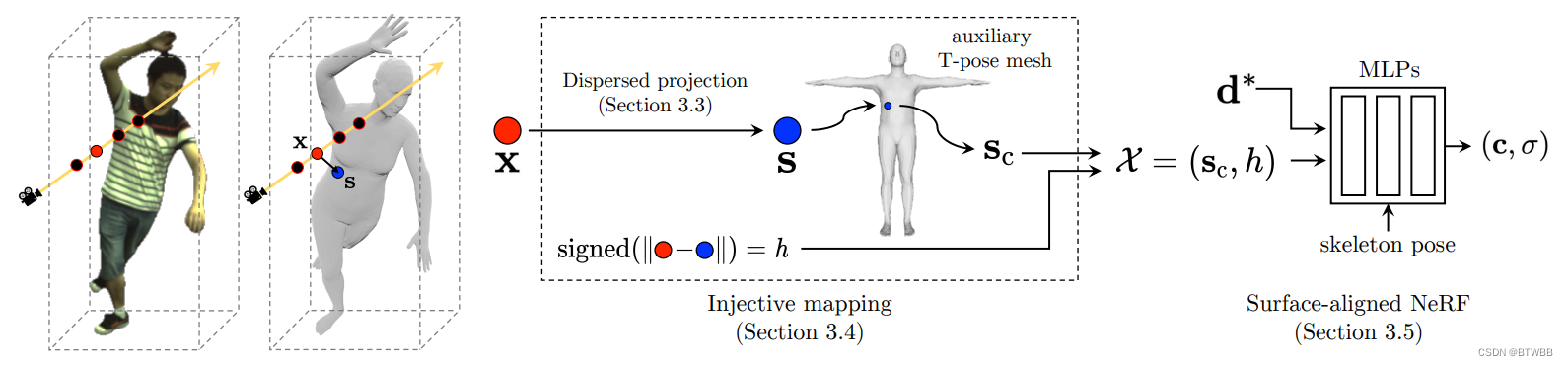
Title: Surface-Aligned Neural Radiance Fields for Controllable 3D Human Synthesis
Author: The University of Tokyo
Abstract: 本文从多目视频重建三维人体模型,提出了新的表面对齐神经辐射场,使用所提出的映射可以很容易地使用SMPL参数控制。与现有的方法相比,本文的方法在新的视角和新的姿态合成上显示了更好的泛化性能,同时支持对体型和衣服的改变等操作。
Paper
Title: GLAMR: Global Occlusion-Aware Human Mesh Recovery With Dynamic Cameras
Author: 1NVIDIA 2Carnegie Mellon University
Abstract: 本文提出了一种从动态摄像机记录的单目视频中恢复三维全局人体网格的方法。
Paper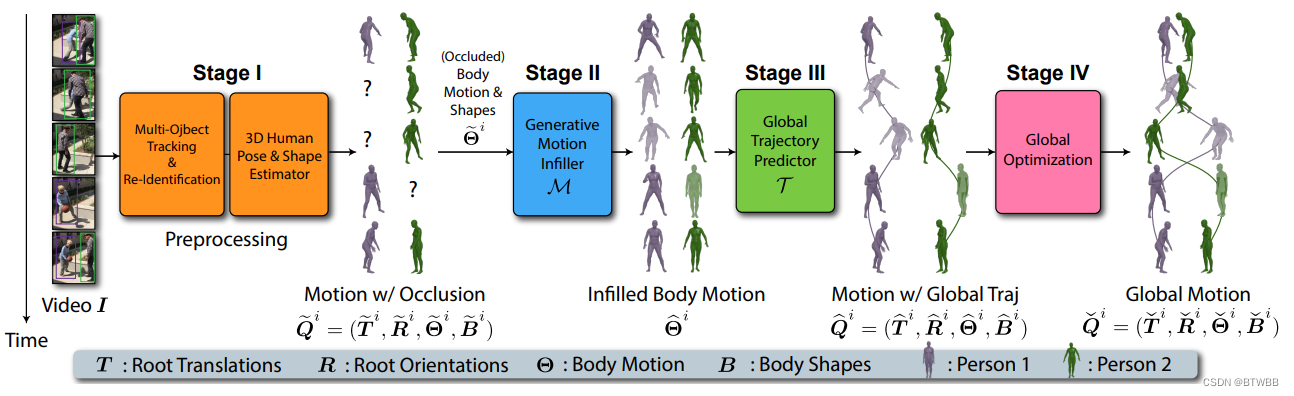
Title: Differentiable Dynamics for Articulated 3D Human Motion Reconstruction
Author: 1Google Research, 2Lund University
Abstract: 本文介绍了DiffPhy,一个从视频重建可微的物理模型铰接式三维人体运动。
Paper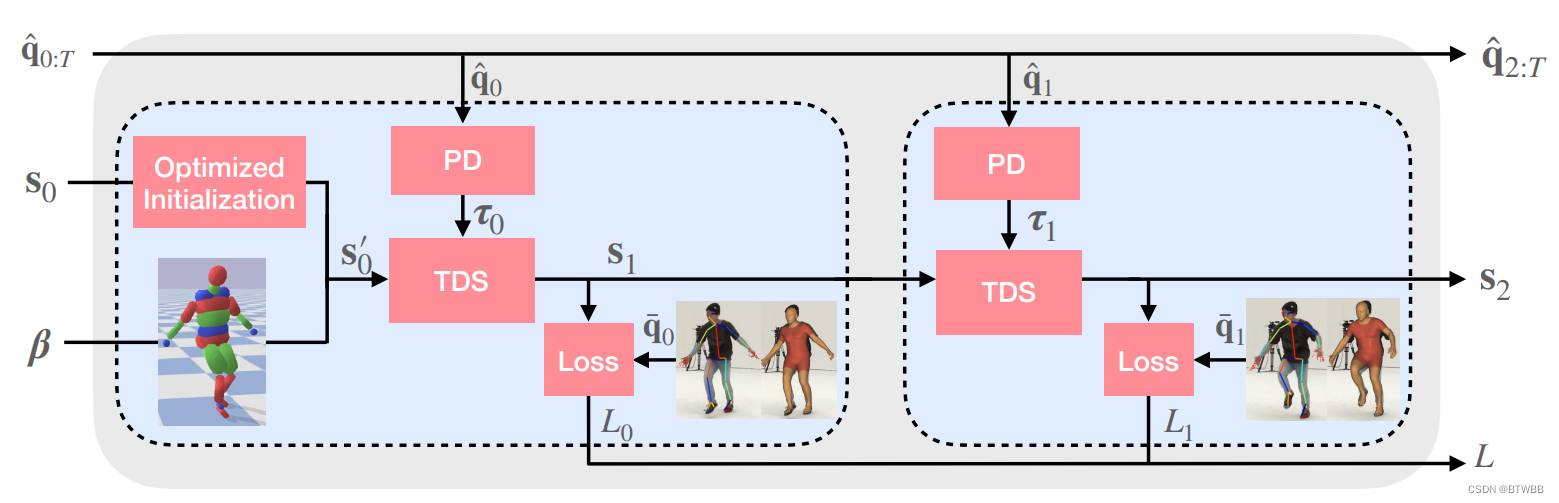
Title: Learning To Estimate Robust 3D Human Mesh From In-the-Wild Crowded Scenes
Author: 1Dept. of ECE & ASRI, 2IPAI, Seoul National University, Korea
Abstract: 本文解决了恢复室外拥挤场景的单人3D人体网格的问题。
Paper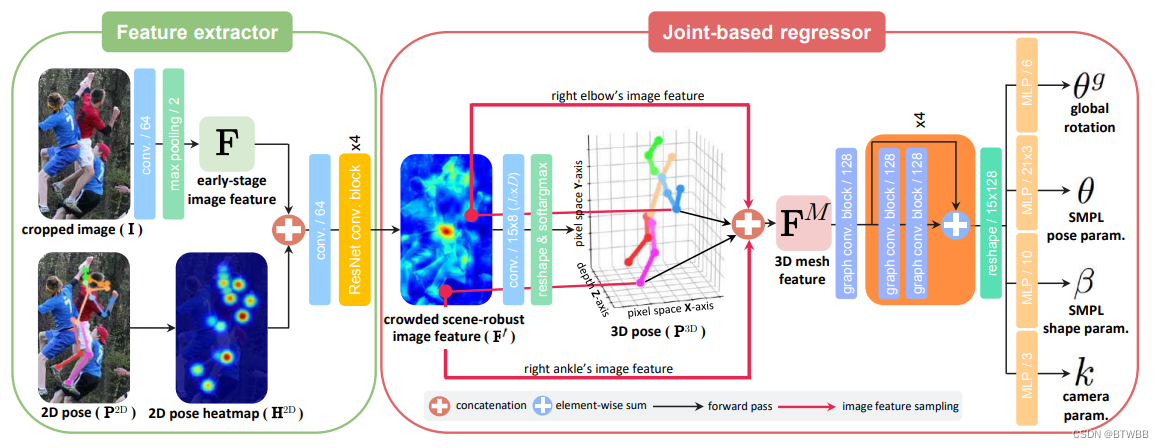
Title: Capturing Humans in Motion: Temporal-Attentive 3D Human Pose and Shape Estimation From Monocular Video
Author: Institute of Information Science, Academia Sinica, Taiwan
Abstract: 本文解决从单目视频中恢复精确的时序一致的参数模型。
Paper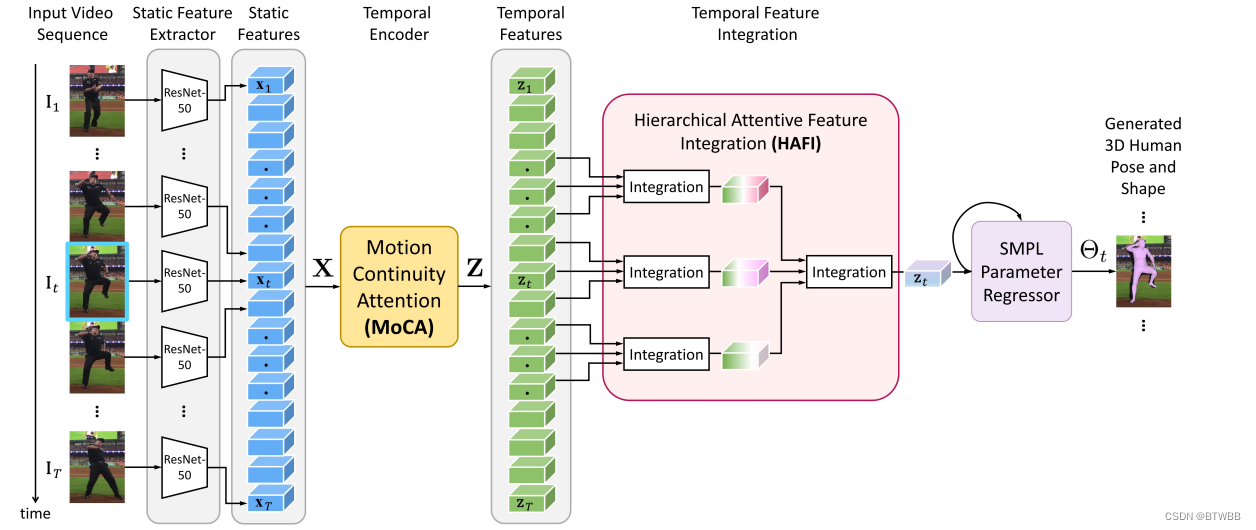
Title: FLAG: Flow-Based 3D Avatar Generation From Sparse Observations
Author: Mixed Reality & AI Lab, Microsoft
Abstract: 利用给定的HMD输入重建参数模型。
Paper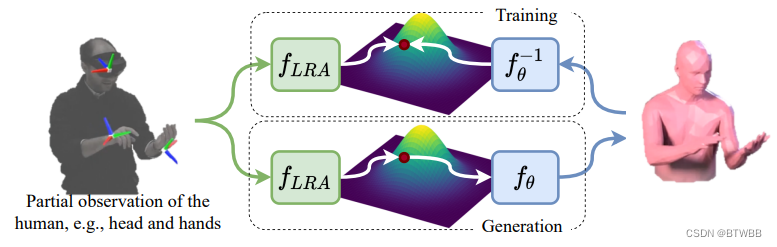
Title: Trajectory Optimization for Physics-Based Reconstruction of 3D Human Pose From Monocular Video
Author: 1Google Research, 2Lund University
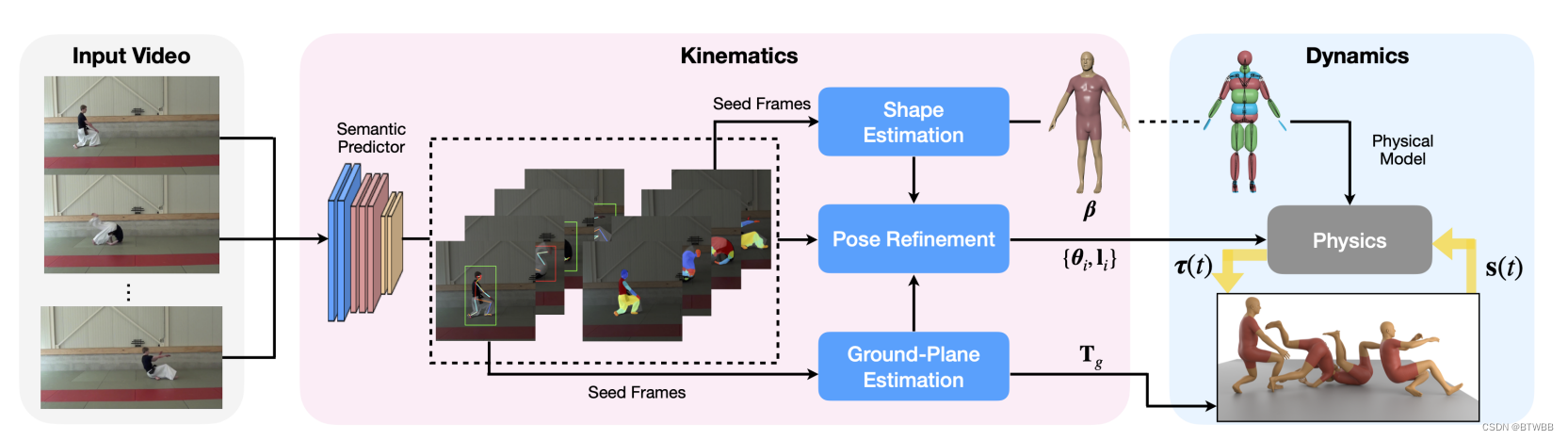
Abstract: 从单目视频中估计参数模型,将物理学运用到姿态估计。
Paper
版权归原作者 BTWBB 所有, 如有侵权,请联系我们删除。