

📚引言
🙋♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读👨🎓,曾获得华为杯数学建模国家二等奖🏆,MathorCup 数学建模竞赛国家二等奖🏅,亚太数学建模国家二等奖🏅。
✍️研究方向:复杂网络科学
🏆兴趣方向:利用python进行数据分析与机器学习,数学建模竞赛经验交流,网络爬虫等。
在机器学习的过程中我们经常会见到最大似然估计,最大似然估计可以说是应用非常广泛的一种参数估计的方法。下面我们就从头开始介绍最大似然估计的理论,一文带你读懂最大似然估计。
📖概率与似然
我们首先来看概率和似然的定义:
概率(Probability):描述给定了模型以及参数后,描述结果的可能性,并不关于观察到的任何数据。
似然(Likelihood):描述已知随机变量输出结果时,未知参数的可能取值,倾向于从观察到的数据描述参数是否合理。
- 抛一枚均匀的硬币10次,6次拋得正面的可能性有多大?这里我们提到的可能性就是概率,因为我们预先假定硬币是均匀的,所以我们求得概率。
- 抛一枚硬币10次,我们观察到6次是正面向上的,问这个硬币是否为均匀质地的可能性(即正反面的概率都为0.5)?这时,我们从观察到的结果出发去估计这个正反面的概率,这就是似然。
📖最大似然估计的定义
最大似然估计:一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
给定一个概率分布
D
D
D,假定其概率密度函数(连续分布)或概率聚集函数(离散分布)为
f
D
f_D
fD,以及一个分布参数
θ
\theta
θ,我们可以从这个分布中抽出一个具有
n
n
n个值的采样
X
1
,
X
2
,
.
.
.
X
n
X_1,X_2,...X_n
X1,X2,...Xn,通过利用
f
D
f_D
fD,我们就可以计算出概率:
P
(
x
1
,
x
2
,
.
.
.
x
n
)
=
f
D
(
x
1
,
x
2
,
.
.
.
,
x
n
∣
θ
)
P(x_1,x_2,...x_n)=f_D(x_1,x_2,...,x_n|\theta)
P(x1,x2,...xn)=fD(x1,x2,...,xn∣θ)
但是当我们并不知道这个参数的值的时候,我们希望从这个分布中抽出一个具有
n
n
n个值的采样
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X1,X2,...,Xn,然后用这些采样数据来估计
θ
\theta
θ。
要实现最大似然估计法,我们首先要定义可能性:
lik
(
θ
)
=
f
D
(
x
1
,
x
2
,
…
,
x
n
∣
θ
)
\operatorname{lik}(\theta)=f_{D}\left(x_{1}, x_{2}, \ldots, x_{n} \mid \theta\right)
lik(θ)=fD(x1,x2,…,xn∣θ)
并且在
θ
\theta
θ的所有取值上,使得这个可能性最大。这就被称为
θ
\theta
θ的**最大似然估计**。
📖最大似然估计的原理
为了更好的理解最大似然估计的原理,我们来看一个例子。
假设有一个盒子里边有很多很多红色和蓝色的小球,而我们想估计抽到红色和蓝色小球的概率。
这里我们设抽到红色小球的概率为
θ
\theta
θ,而我们抽到蓝色小球的概率即为
1
−
θ
1-\theta
1−θ。如下表格所示:
红色蓝色
θ
\theta
θ
1
−
θ
1-\theta
1−θ
我们分别从盒子中抽出了五个球,得到了以下的结果:
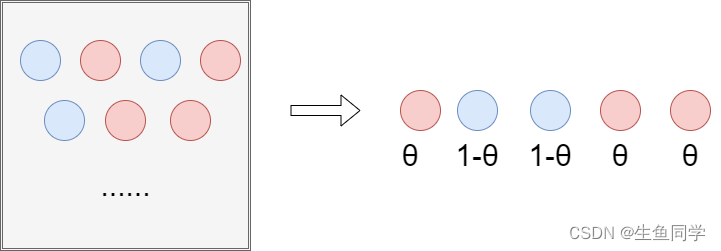
我们就能够得到这组样本的概率
θ
3
(
1
−
θ
)
2
\theta^3(1-\theta)^2
θ3(1−θ)2,这就是**似然函数**即
L
(
θ
)
=
θ
3
(
1
−
θ
)
2
L(\theta)=\theta^3(1-\theta)^2
L(θ)=θ3(1−θ)2。
最大似然估计基于这样一个假设,即目前我们观测到的样本所呈现的状态已经是其最大可能出现的状态。
所以我们只需要看似然函数什么时候能达到最大,其取得最大值的时候的
θ
\theta
θ就是我们希望得到的
θ
\theta
θ。
因此,我们的问题就转换为了对
L
(
θ
)
=
θ
3
(
1
−
θ
)
2
L(\theta)=\theta^3(1-\theta)^2
L(θ)=θ3(1−θ)2求最大值的问题。
相信大家通过这个例子已经大概了解了最大似然估计的原理。
📍总结
本文从浅入深介绍了最大似然估计的原理并举了相关例子,旨在于对最大似然估计进行全面的介绍和了解。
在我们学习机器学习的过程中,会遇到很多数学相关的问题,而这决定了我们扎实的基础,还需要不断学习和实践。
今天就是这样,如果你感觉本文对你有帮助,请帮我点个赞或者收藏一下,我们下次再见。

版权归原作者 生鱼同学 所有, 如有侵权,请联系我们删除。