
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种常用的多元统计分析方法,通常被用于分类和特征提取。它的目的是在给定一组带有标签的数据的情况下,找到一个线性变换,将数据投影到一个低维空间中,使得不同类别的数据点在该低维空间中能够更加容易地区分开来。简而言之,LDA 的目的是将高维数据投影到低维空间中,同时最大化类别之间的差异性,最小化类别内部的差异性。
LDA 的基本思想是,将数据在低维空间中找到一个合适的投影方向,使得类别之间的距离最大化,同时类别内部的距离最小化。为了实现这个目的,LDA 首先需要计算数据的协方差矩阵,然后对协方差矩阵进行特征值分解,得到协方差矩阵的特征向量和特征值。这些特征向量构成了投影矩阵,可以将原始数据映射到新的低维空间中。投影后的数据可以使用简单的分类器(如线性分类器)来进行分类。
LDA 和 PCA(Principal Component Analysis,主成分分析)有相似之处,但它们的目标不同。PCA 的目标是在不降低数据的可区分性的前提下,将数据投影到一个低维空间中,以最大化数据的方差。而 LDA 的目标是最大化类别之间的距离,最小化类别内部的距离,以提高分类的准确性。
总之,LDA 是一种经典的分类算法,具有较好的分类性能和解释性。在实际应用中,LDA 常常被用于面部识别、语音识别、图像分类等领域。
LDA 的数学推导可以分为两个步骤:第一步是计算数据的协方差矩阵,第二步是找到一个合适的投影方向。
首先,假设有 N 个样本,每个样本有 p 个特征,数据矩阵为 X_{N\times p},其中 X_i 表示第 i 个样本的特征向量。假设数据被分为 K个类别,每个类别包含 N_k 个样本,其中 sum_{k=1}^{K}N_k=N。每个类别的均值向量为 mu_k,总体均值向量为 mu。类内散度矩阵为 S_w,类间散度矩阵为 S_b。则有:

其中,C_k 表示第 k个类别。
接下来,我们需要找到一个投影方向 w,将数据矩阵 X 映射到一维空间中。投影后的数据为 y=Xw。我们希望在投影后的一维空间中,不同类别的数据点能够更加容易地区分开来。因此,我们希望在一维空间中最大化类间散度矩阵 S_b,同时最小化类内散度矩阵 S_w。
类间散度矩阵 S_b 在一维空间中的表达式为:

类内散度矩阵 S_w 在一维空间中的表达式为:
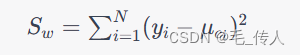
其中,c_i 表示第 i 个样本所属的类别,mu_{c_i} 表示第 i个样本所属类别的均值。y_i 表示第 i个样本在一维空间中的投影。
为了最大化 S_b,我们需要找到一个投影方向 w,使得 w^T(\mu_1-\mu_2)^2w 最大化。这等价于找到一个方向 w,使得 w^TS_bw最大化。
为了最小化 S_w,我们需要找到一个投影方向 w,使得 w^T\sum_{i=1}^{N}(y_i-\mu_{c_i})^2w 最小化。因为 y=Xw,所以有:
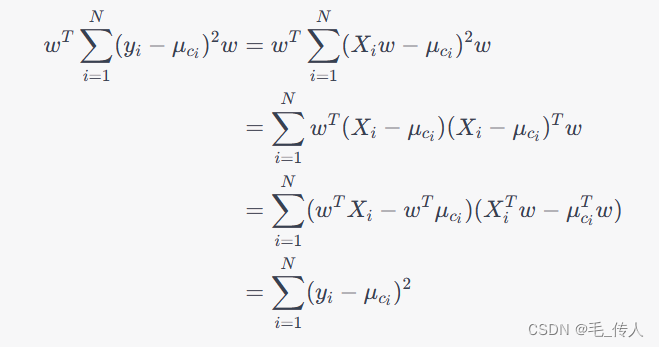
因此,我们需要最小化 sum_{i=1}^{N}(y_i-\mu_{c_i})^2,即最小化类内散度矩阵 S_w。
综上所述,我们需要找到一个投影方向 w,使得 w^TS_bw 最大化,w^TS_ww 最小化。这是一个标准的广义瑞利商问题,可以通过求解广义特征值问题来解决。具体来说,我们需要求解下面的广义特征值问题:
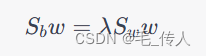
求解出特征值和特征向量之后,我们可以选择最大的 d 个特征向量,将数据矩阵X映射到 d 维空间中,从而进行分类。
当我们得到数据矩阵 X和类别向量 y 后,可以使用 Python 中的
sklearn.discriminant_analysis.LinearDiscriminantAnalysis
类来进行线性判别分析。下面是一个简单的例子:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 创建 LDA 模型对象
lda = LinearDiscriminantAnalysis()
# 使用 LDA 拟合数据
lda.fit(X, y)
# 对新数据进行预测
y_pred = lda.predict(X_new)
其中,
X
是形状为 (n_samples, n_features)的数据矩阵,
y
是形状为 (n_samples,) 的类别向量,
X_new
是形状为 (m, n_features) 的新数据矩阵,
y_pred
是形状为 (m,) 的预测结果向量。
在实际使用中,我们可以先将数据集拆分成训练集和测试集,然后使用训练集来拟合 LDA 模型,最后使用测试集来评估模型的分类性能。下面是一个完整的例子:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.metrics import accuracy_score
# 生成样本数据
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_classes=2, random_state=42)
# 将数据集拆分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建 LDA 模型对象
lda = LinearDiscriminantAnalysis()
# 使用训练集拟合 LDA 模型
lda.fit(X_train, y_train)
# 对测试集进行预测
y_pred = lda.predict(X_test)
# 计算分类准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
在这个例子中,我们首先使用
make_classification
函数生成一个二分类数据集,然后将数据集拆分成训练集和测试集,使用训练集来拟合 LDA 模型,最后使用测试集来评估模型的分类性能。在这个例子中,我们使用了分类准确率来评估模型的性能。
除了使用
sklearn
库提供的
LinearDiscriminantAnalysis
类之外,我们还可以手动实现线性判别分析算法。下面是一个基于 NumPy 的简单实现:
import numpy as np
class LinearDiscriminantAnalysis:
def __init__(self, n_components=None):
self.n_components = n_components
self.w = None
def fit(self, X, y):
# 计算类别数量、总均值和类内散度矩阵
self.classes_ = np.unique(y)
self.mean_ = np.mean(X, axis=0)
Sw = np.zeros((X.shape[1], X.shape[1]))
for c in self.classes_:
Xc = X[y == c]
mean_c = np.mean(Xc, axis=0)
Sw += (Xc - mean_c).T.dot(Xc - mean_c)
self.Sw_ = Sw
# 计算类间散度矩阵和投影方向
Sb = np.zeros((X.shape[1], X.shape[1]))
for c in self.classes_:
Xc = X[y == c]
mean_c = np.mean(Xc, axis=0)
Sb += Xc.shape[0] * (mean_c - self.mean_).reshape(-1, 1).dot((mean_c - self.mean_).reshape(1, -1))
eigvals, eigvecs = np.linalg.eig(np.linalg.inv(self.Sw_).dot(Sb))
eigvecs = eigvecs[:, np.argsort(eigvals)[::-1]]
if self.n_components is not None:
self.w = eigvecs[:, :self.n_components]
else:
self.w = eigvecs
def transform(self, X):
return X.dot(self.w)
def fit_transform(self, X, y):
self.fit(X, y)
return self.transform(X)
在这个实现中,我们首先定义了一个
LinearDiscriminantAnalysis
类,其中
n_components
参数指定了投影的维数,如果不指定,则默认为原始特征的维数。
在
fit
方法中,我们首先计算了类别数量、总均值和类内散度矩阵
Sw
,然后计算了类间散度矩阵
Sb
和投影方向
w
。我们使用
numpy.linalg.eig
函数来求解广义特征值问题,然后将特征向量按照特征值从大到小排序,并选择前
n_components
个特征向量作为投影方向。最后,我们将投影方向保存在
w
属性中。
在
transform
方法中,我们将数据矩阵
X
乘以投影方向
w
,得到经过投影后的数据矩阵。在
fit_transform
方法中,我们先调用
fit
方法来拟合模型,然后调用
transform
方法来进行投影。
对于分类问题,我们可以使用投影后的数据进行训练和预测。下面是一个完整的示例,演示了如何使用上面的实现来训练和评估模型:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成样本数据
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
lda = LinearDiscriminantAnalysis(n_components=1)
X_train_lda = lda.fit_transform(X_train, y_train)
# 预测测试集
X_test_lda = lda.transform(X_test)
y_pred = np.zeros_like(y_test)
for c in lda.classes_:
y_c = y_train == c
mu_c = np.mean(X_train_lda[y_c], axis=0)
sigma_c = np.var(X_train_lda[y_c], axis=0, ddof=1)
p_c = np.sum(y_c) / len(y_train)
y_pred += p_c * stats.norm.pdf(X_test_lda, mu_c, np.sqrt(sigma_c))
# 计算准确率
y_pred = np.argmax(y_pred, axis=1)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
在这个示例中,我们首先生成了一个样本数据集,并将其划分为训练集和测试集。然后,我们实例化了一个
LinearDiscriminantAnalysis
类,并使用训练集拟合了模型。接下来,我们将训练集和测试集投影到一维空间,并使用高斯分布来拟合每个类别的投影值分布。最后,我们使用贝叶斯公式来计算每个测试样本属于每个类别的概率,并选择具有最大概率的类别作为预测结果。我们使用
accuracy_score
函数来计算准确率。
可视化代码实现
下面我们以鸢尾花数据集为例,来展示如何使用线性判别分析进行分类。
首先,我们从Scikit-learn库中导入鸢尾花数据集,并将其分为训练集和测试集。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
接下来,我们使用
LinearDiscriminantAnalysis
类来训练线性判别分析模型,并使用训练集对其进行拟合。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)
然后,我们可以使用训练好的模型对测试集进行预测,并计算分类准确率。
from sklearn.metrics import accuracy_score
y_pred = lda.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
最后,我们可以使用Matplotlib库将训练集和测试集在二维平面上可视化,以及绘制决策边界。
import numpy as np
import matplotlib.pyplot as plt
# 将训练集和测试集投影到二维平面
X_train_lda = lda.transform(X_train)
X_test_lda = lda.transform(X_test)
# 绘制训练集和测试集
plt.figure(figsize=(8,6))
for i, target_name in enumerate(iris.target_names):
plt.scatter(X_train_lda[y_train == i, 0], X_train_lda[y_train == i, 1], label=target_name)
plt.scatter(X_test_lda[y_test == i, 0], X_test_lda[y_test == i, 1], marker='x', label=target_name)
# 绘制决策边界
x_min, x_max = X_train_lda[:, 0].min() - 1, X_train_lda[:, 0].max() + 1
y_min, y_max = X_train_lda[:, 1].min() - 1, X_train_lda[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
Z = lda.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, colors='black', alpha=0.5)
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.title('Linear Discriminant Analysis')
plt.legend()
plt.show()
在这个图中,每个类别用不同的颜色表示。我们可以看到,训练集和测试集在投影后可以明显地分开。决策边界是一个非线性的分割线,它将不同的类别分开。
版权归原作者 秦_天明 所有, 如有侵权,请联系我们删除。