
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
LSTM 是序列建模任务(例如语言建模和时间序列预测)中广泛使用的技术。此类任务通常具有长期记忆和短期记忆,因此学习两种模式以进行准确预测和估计非常重要。基于 Transformers 的技术正在兴起,这种技术有助于对长期依赖进行建模并且比lstm好得多,但由于需要大量数据的训练和部署复杂性,Transformer 不能用于每个应用程序。在这篇文章中,我将在 LSTM 和 TCN 的长期信息学习方面进行比较。
本文假设读者对 LSTM 和 CNN 神经网络的模型理论和架构有初步的了解。
技术背景
LSTM是一种长期记忆神经网络,广泛用于学习序列数据(NLP、时间序列预测等)。由于递归神经网络(RNN)存在梯度消失问题,阻碍了网络学习长时间的依赖关系,而LSTM通过引入遗忘门、输入门和输出门来减少这个问题。有了这些门,它就有了代表长期记忆的cell状态,而hidden状态则代表短期记忆。遗憾的是,LSTM仍然不是一个保留长期信息的完美解决方案,因为遗忘门倾向于从之前的步骤中删除这些模式(信息衰减)——如果模式对50个步骤都不重要,为什么我要保留它?
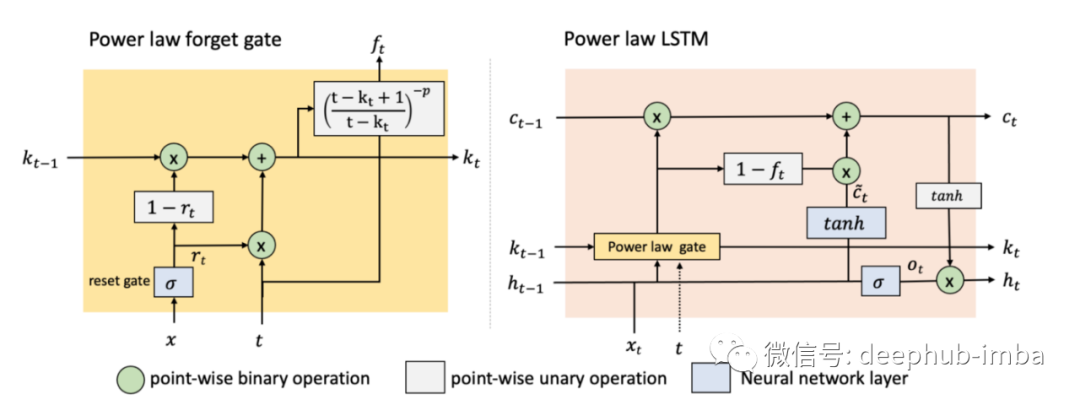
Power Law Forget Gated LSTM (pLSTM)是英特尔公司和约翰霍普金斯大学的研究人员最近开发的。尽管LSTM有所改进,但遗忘机制表现出信息的指数衰减限制了它捕获长时间尺度信息的能力。由于 LSTM 中的信息衰减遵循指数模式,因此 pLSTM 向遗忘门添加了衰减因子 p,这允许 LSTM 控制信息衰减率,帮助其更好地学习长期依赖关系。
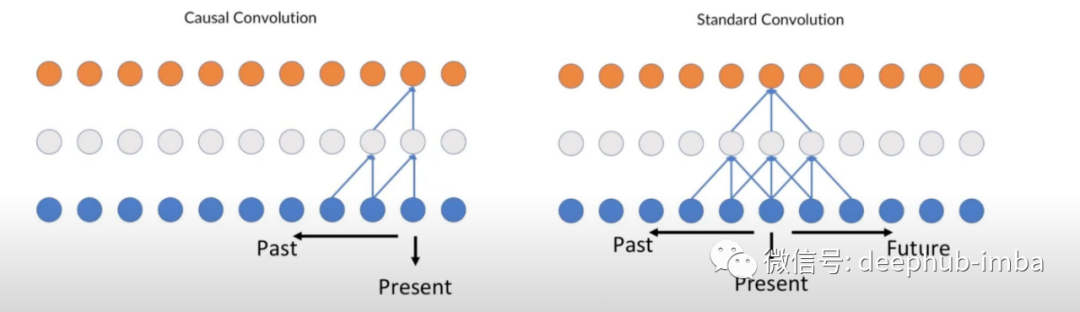
Temporal CNN (TCN)是一种简单的一维卷积网络,可以应用于时间序列数据而不是图像数据。这些层具有时间属性,用于学习数据中的全局和局部模式。卷积层还有助于改善模型延迟,因为预测可以并行化,不需要按顺序排列。由于每个预测只能依赖于其先前的预测,所以CNN 也是可以有因果关系的,不会有来自未来的数据泄漏。TCN 使用深度神经网络和扩张卷积的组合构成了能够保存非常长的有效历史大小的模型。TCN 有多种变体,例如基于注意力的 CNN,将 LSTM 与 CNN 相结合,并融合其他类型的架构,但在本篇文章中,我将使用普通的 TCN 以保持简单性。
合成数据
让我们从一个简单的加法函数开始:
Y = f(xⁿ)+ f(x¹)
每个人都可以设计自己的函数,现在我们用这个:我们的假设序列越长,LSTM就越难记住X⁰的值,例如,一个2的序列是第1和第2个元素的相加,而一个100的序列是第1(0)和第100(或-1)个元素的相加。序列越大,LSTM需要携带信息的步骤就越多。
import numpy as np
from tensorflow.keras.utils import Sequence
seq = 70
N = 1000
class DataGenerator(Sequence):
def __init__(self, seq, N, batch_size, to_fit=True):
self.seq = seq
self.N = N
self.to_fit = to_fit
self.batch_size = batch_size
def __len__(self):
return int(self.N / self.batch_size)
def __getitem__(self, index):
x = np.array([np.random.normal(0, 1, self.seq) for i in range(self.batch_size)])
if self.to_fit:
y = x[:, 0] + x[:, -1]
return x.reshape(list(x.shape) + [1]), y
return x
trainGen = DataGenerator(seq,N, 256)
validGen = DataGenerator(seq,N*.3, 256*.3)
LSTM 模型架构
我创建了一个普通的 LSTM并试验了超参数以及堆叠的 LSTM 层来验证我们的假设
from tensorflow.keras.layers import Input, LSTM, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import ModelCheckpoint
X = Input(shape=(None,1))
LSTM_1 = LSTM(8, return_sequences=True, activation='softplus')(X)
LSTM_2 = LSTM(6, return_sequences=False, activation='softplus')(LSTM_1)
Y_hat = Dense(1)(LSTM_2)
model = Model(inputs=X, outputs=Y_hat)
print(model.compile(loss='mse'))
print(model.summary())
MODEL_NAME = 'lstm.hdf5'
checkpoint = ModelCheckpoint(MODEL_NAME, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
model.fit(trainGen, validation_data=validGen, epochs=1000, callbacks=callbacks_list, verbose=0)
model.load_weights(MODEL_NAME)
print(model.evaluate(validGen))
CNN模型架构
我创建了一个普通的 TCN 架构,并试验了超参数,例如 kernel_size、核大小和卷积数来验证我们的假设
from tensorflow.keras.layers import Input, Dense, Conv1D, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import ModelCheckpoint
X = Input(shape=(seq,1))
CNN_1 = Conv1D(filters=3, kernel_size=seq, activation='softplus', padding='valid')(X)
FLATTEN_1 = Flatten()(CNN_1)
DENSE_1 = Dense(2, activation='softplus')(FLATTEN_1)
Y_HAT = Dense(1)(DENSE_1)
model = Model(inputs=X, outputs=Y_HAT)
print(model.compile(loss='mse'))
print(model.summary())
MODEL_NAME = 'cnn.hdf5'
checkpoint = ModelCheckpoint(MODEL_NAME, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
model.fit(trainGen, validation_data=validGen, epochs=1000, callbacks=callbacks_list, verbose=0)
model.load_weights(MODEL_NAME)
print(model.evaluate(validGen))
模型性能结果
MSE 是评估非偏态数据的一个很好的方法,但是解释起来不是很简单。为简化起见,我们可以查看当 X 之一发生变化时 Y 的变化百分比(change函数)。由于合成函数是可加的,将 X 中的一个改变 N% 应该会使 Y 发生 N/2% 的变化。其次, 我们使用blinding函数,将 X 中的任何一个设置为 0 时,我们可以根据 MSE 测量 Y 是否等于非零 X。理论上,MSE应该是0.0
def change(test, perc, y_pred, model, idx):
testX_ = test.copy()
testX_[:,idx,:] *= 1+perc/100.
y_pred_ = model.predict(testX_).reshape(-1)
print(round(np.median((y_pred_ - y_pred)/y_pred)*100.,2))
def blinding(test, perc, y_pred, model, idx_on, idx_off):
testX_ = test.copy()[:10]
testX_[:,idx_off,:] = [np.array([0.0]) for i in range(10)]
testX_[:,idx_on,:] = [np.array([i/10.]) for i in range(10)]
print(
round(
np.mean(
(model.predict(testX_) - testX_[:,idx_on,:])**2.
),
3)
)
结果和结论
我独立地对 X[0] 和 X[-1] 应用了 50% 的变化,以了解 Y 的变化并计算第 0 次变化和第 -1 次变化列。LSTM 能够记住从时间序列开始时多达 68 个序列长度的先验信息,但最终在第 69 个序列长度时忘记了,而 TCN 仍然能够做出准确的预测,因为我增加了内核大小,使得模型可以查看序列数据的初始值和结束值。blinding函数的测试显示了相同的结果。当序列长度为 69 的第 0 个值设置为 0 时,MSE 跳至 0.251%。总体而言,LSTM 似乎对第 -1 次变化比对第 0 次变化更敏感。
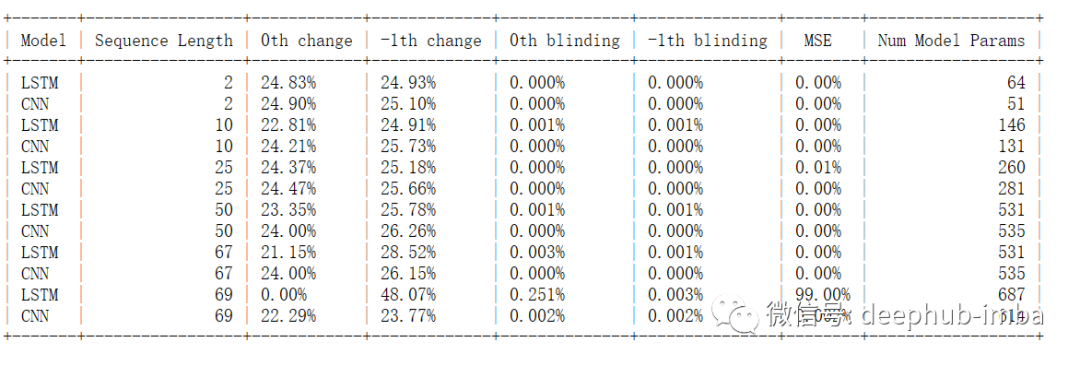
这些结果与 pLSTM 作者在其信息衰减部分中描述的大体相同
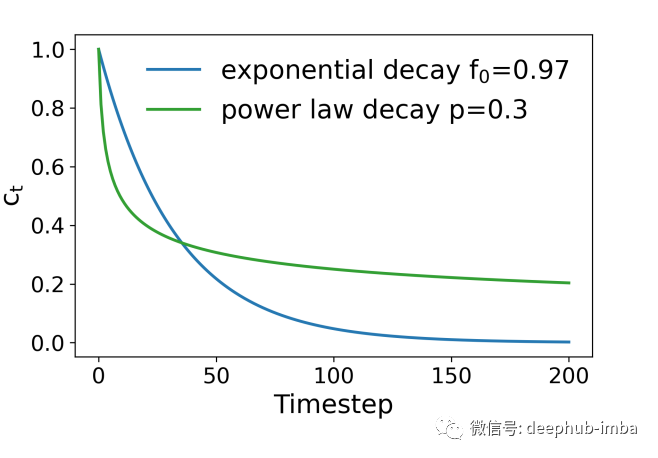
在本文中,没有与 pLSTM 进行比较,因为还没有可用的开源实现,如果有机会我将根据论文实现并进行比较。
这里包含本文的全部源代码:https://github.com/dwipam/medium-3
pLstm论文:https://arxiv.org/abs/2105.05944
作者:Dwipam Katariya
喜欢就关注一下吧:
点个 在看 你最好看!********** **********