
文章目录
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
简介
LeNet模型是在1998年提出的一种图像分类模型,应用于支票或邮件编码上的手写数字的识别,也被认为是最早的卷积神经网络(CNN),为后续CNN的发展奠定了基础,作者LeCun Y也被誉为卷积神经网络之父。LeNet之后一直直到2012年的AlexNet模型在ImageNet比赛上表现优秀,使得沉寂了14年的卷积神经网络再次成为研究热点。
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
LeNet模型结构如下: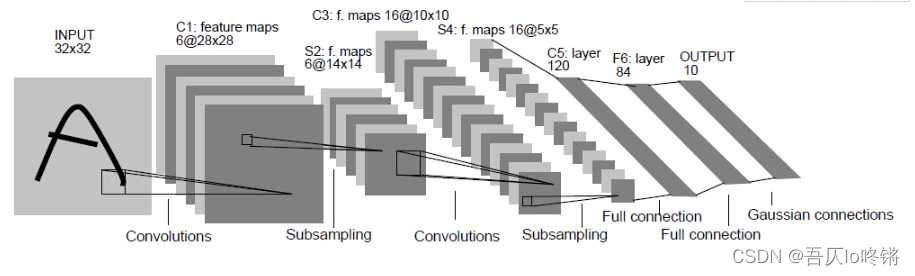
- INPUT(输入层) 输入图像的尺寸为32X32,是单通道的灰色图像。
- C1(卷积层) 使用了6个大小为5×5的卷积核,步长为1,卷积后得到6张28×28的特征图。
- S2(池化层) 使用了6个2×2 的平均池化,步长为2,池化后得到6张14×14的特征图。
- C3(卷积层) 使用了16个大小为5×5的卷积核,步长为1,得到 16 张10×10的特征图。 由于是多个卷积核对应多个输入,论文中采用了如下组合方式:
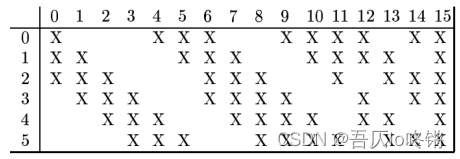
- S4(池化层) 使用16个2×2的平均池化,步长为2,池化后得到16张5×5 的特征图。
- C5(卷积层) 使用120个大小为5×5的卷积核,步长为1,卷积后得到120张1×1的特征图。
- F6(全连接层) 输入维度120,输出维度是84(对应7x12 的比特图)。
- OUTPUT(输出层) 使用高斯核函数,输入维度84,输出维度是10(对应数字 0 到 9)。
数据集
使用torchversion内置的
MNIST
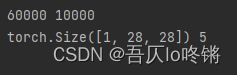
数据集,训练集大小60000,测试集大小10000,图像大小是1×28×28,包括数字0~9共10个类。官网:http://yann.lecun.com/exdb/mnist/
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torchvision
mnist_train = torchvision.datasets.MNIST(root='./datasets/',
train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./datasets/',
train=False, download=True, transform=transforms.ToTensor())print(len(mnist_train),len(mnist_test))# 打印训练/测试集大小
feature, label = mnist_train[0]print(feature.shape, label)# 打印图像大小和标签
dataloader = DataLoader(mnist_test, batch_size=64, num_workers=0)# 每次批量加载64张
step =0
writer = SummaryWriter(log_dir='runs/mnist')# 可视化for data in dataloader:
features, labels = data
writer.add_images(tag='train', img_tensor=features, global_step=step)
step +=1
writer.close()
可视化部分可参考我这篇博客:深度学习-Tensorboard可视化面板
此外,还可以使用torchversion内置的
FashionMNIST
数据集,包括衣服、包等10类图像,也是1×28×28,各60000、10000张。
模型搭建
使用Pytoch进行搭建和测试。
在第一个卷积层C1设置padding为2,因为数据集是28×28大小,原模型是32×32大小。
import torch
from torch import nn, optim
classLeNet(nn.Module):def__init__(self)->None:super().__init__()
self.model = nn.Sequential(# (-1,1,28,28)
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),# (-1,6,28,28)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),# (-1,6,14,14)
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),# (-1,16,10,10)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),# (-1,16,5,5)
nn.Flatten(),
nn.Linear(in_features=16*5*5, out_features=120),# (-1,120)
nn.Sigmoid(),
nn.Linear(120,84),# (-1,84)
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10)# (-1,10))defforward(self, x):return self.model(x)
leNet = LeNet()print(leNet)
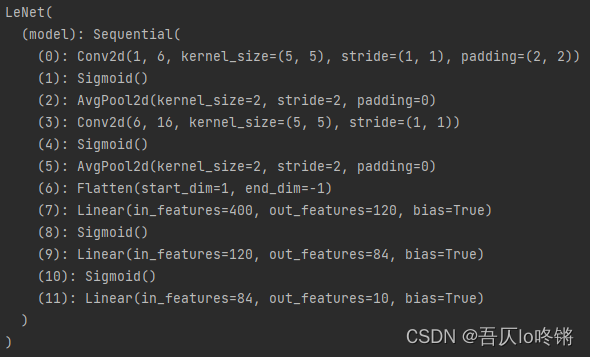
模型训练
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
from torch import nn
from torch.utils.tensorboard import SummaryWriter
classLeNet(nn.Module):def__init__(self)->None:super().__init__()
self.model = nn.Sequential(# (-1,1,28,28)
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),# (-1,6,28,28)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),# (-1,6,14,14)
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),# (-1,16,10,10)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),# (-1,16,5,5)
nn.Flatten(),
nn.Linear(in_features=16*5*5, out_features=120),# (-1,120)
nn.Sigmoid(),
nn.Linear(120,84),# (-1,84)
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10)# (-1,10))defforward(self, x):return self.model(x)# 创建模型
leNet = LeNet()
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')
leNet = leNet.to(device)# 若支持GPU加速# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)# 优化器
learning_rate =1e-2
optimizer = torch.optim.Adam(leNet.parameters(), lr=learning_rate)
total_train_step =0# 总训练次数
epoch =10# 训练轮数
writer = SummaryWriter(log_dir='./runs/LeNet/')# 数据
mnist_train = torchvision.datasets.MNIST(root='./datasets/',
train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./datasets/',
train=False, download=True, transform=transforms.ToTensor())
dataloader_train = DataLoader(mnist_train, batch_size=64, num_workers=0)# 每次批量加载64张
dataloader_test = DataLoader(mnist_test, batch_size=64, num_workers=0)# 每次批量加载64张for i inrange(epoch):print("-----第{}轮训练开始-----".format(i +1))
leNet.train()# 训练模式
train_loss =0for data in dataloader_train:
imgs, labels = data
imgs = imgs.to(device)# 适配GPU/CPU
labels = labels.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()# 清空之前梯度
loss.backward()# 反向传播
optimizer.step()# 更新参数
total_train_step +=1# 更新步数
train_loss += loss.item()
writer.add_scalar("train_loss_detail", loss.item(), total_train_step)
writer.add_scalar("train_loss_total", train_loss, i +1)
torch.save(leNet,"./models/LeNet.pkl")# 保存模型#leNet = torch.load("./models/LeNet") 加载模型
writer.close()
(插播反爬信息 )博主CSDN地址:https://wzlodq.blog.csdn.net/
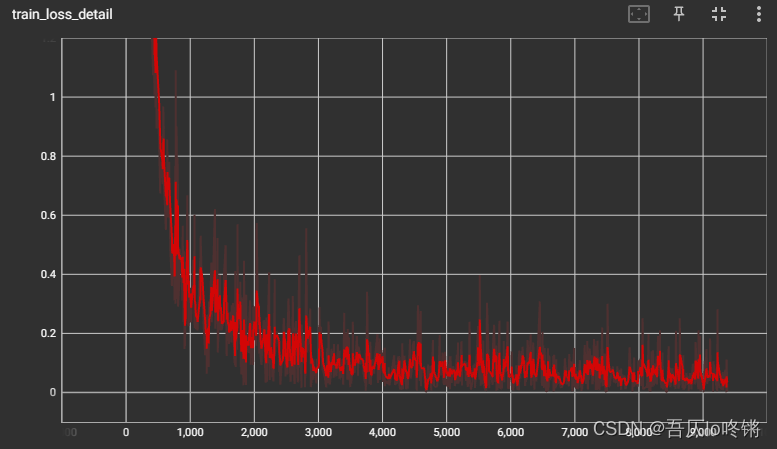
由于打印了每轮各个批次64张图的损失,不同批次损失不同,所以上下震荡大,但总体仍是减少收敛的。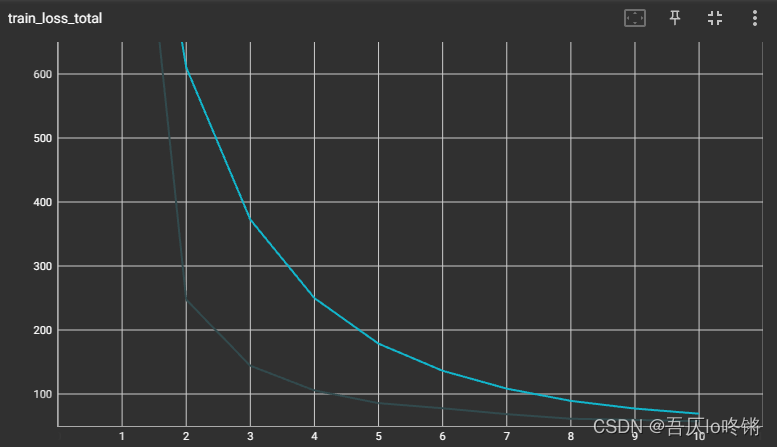
模型测试
leNet.eval()# 测试模式
total_test_loss =0# 当前轮次模型测试所得损失
total_accuracy =0# 当前轮次精确率with torch.no_grad():# 关闭梯度反向传播for data in dataloader_test:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy =(outputs.argmax(1)== targets).sum()
total_accuracy = total_accuracy + accuracy
writer.add_scalar("test_loss", total_test_loss, i+1)
writer.add_scalar("test_accuracy", total_accuracy/len(mnist_test), i+1)
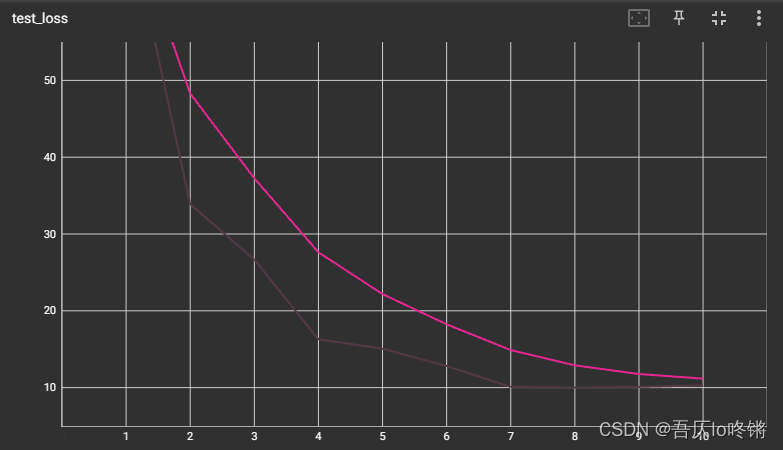
随着训练轮数增加,对应模型测试的损失减少并收敛。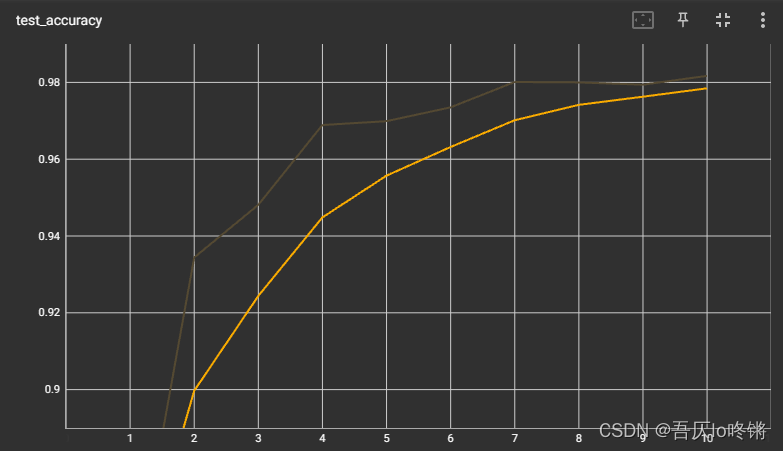
精确率在几轮后就趋于98%以上,就是说感受到了来自98年的科技~
最后,附完整代码:
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
from torch import nn
from torch.utils.tensorboard import SummaryWriter
classLeNet(nn.Module):def__init__(self)->None:super().__init__()
self.model = nn.Sequential(# (-1,1,28,28)
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),# (-1,6,28,28)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),# (-1,6,14,14)
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),# (-1,16,10,10)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),# (-1,16,5,5)
nn.Flatten(),
nn.Linear(in_features=16*5*5, out_features=120),# (-1,120)
nn.Sigmoid(),
nn.Linear(120,84),# (-1,84)
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10)# (-1,10))defforward(self, x):return self.model(x)# 创建模型
leNet = LeNet()
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')
leNet = leNet.to(device)# 若支持GPU加速# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)# 优化器
learning_rate =1e-2
optimizer = torch.optim.Adam(leNet.parameters(), lr=learning_rate)
total_train_step =0# 总训练次数
epoch =10# 训练轮数
writer = SummaryWriter(log_dir='./runs/LeNet/')# 数据
mnist_train = torchvision.datasets.MNIST(root='./datasets/',
train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./datasets/',
train=False, download=True, transform=transforms.ToTensor())
dataloader_train = DataLoader(mnist_train, batch_size=64, num_workers=0)# 每次批量加载64张
dataloader_test = DataLoader(mnist_test, batch_size=64, num_workers=0)# 每次批量加载64张for i inrange(epoch):print("-----第{}轮训练开始-----".format(i +1))
leNet.train()# 训练模式
train_loss =0for data in dataloader_train:
imgs, labels = data
imgs = imgs.to(device)# 适配GPU/CPU
labels = labels.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()# 清空之前梯度
loss.backward()# 反向传播
optimizer.step()# 更新参数
total_train_step +=1# 更新步数
train_loss += loss.item()
writer.add_scalar("train_loss", loss.item(), total_train_step)
writer.add_scalar("train_loss", train_loss, i +1)
leNet.eval()# 测试模式
total_test_loss =0# 当前轮次模型测试所得损失
total_accuracy =0# 当前轮次精确率with torch.no_grad():# 关闭梯度反向传播for data in dataloader_test:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy =(outputs.argmax(1)== targets).sum()
total_accuracy = total_accuracy + accuracy
writer.add_scalar("test_loss", total_test_loss, i+1)
writer.add_scalar("test_accuracy", total_accuracy/len(mnist_test), i+1)
torch.save(leNet,"./models/LeNet.pkl")# 保存模型#leNet = torch.load("./models/LeNet") 加载模型
writer.close()
原创不易,请勿转载(本不富裕的访问量雪上加霜 )
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
版权归原作者 吾仄lo咚锵 所有, 如有侵权,请联系我们删除。