
AI:ModelScope(一站式开源的模型即服务共享平台)的简介、安装、使用方法之详细攻略
导读:ModelScope旨在打造下一代开源的模型即服务共享平台,汇集了行业领先的预训练模型,减少了开发者的重复研发成本。个人认为,相比于AI公司经常卖一款软件产品或者卖一个算法需求,而ModelScope更偏向于某种功能(model端到端)实现,初级AI从业者也能很容易实现大模型,有点低代码的感觉。当前ModelScope的功能,相比于CV、NLP的丰富内容,它在DS方面、可视化方面、解释性方面的就相对较少,同时,产品定位 To B和To C的功能域划分,也不算是很清晰,当然这也是该领域一个共同困扰。首次,当然可以先初级版本开源,其次,平台可以集大智慧,最后,模型迭代实现功能升级。对比国外也有类似平台或服务产品,六年的快速发展,如今实现估值十多亿美元。而在国内,随着人工智能场景的无处不在,也有着上千万的开发者,国内人工智能领域活跃度也异常空前,且有达摩院品牌的加持,ModelScope,六年的时间,会走到哪里呢?是否会迎来一个面向机器学习社区的新生态?一个崭新的独角兽?让我们拭目以待吧……
ModelScope的简介
汇聚机器学习领域中最先进的开源模型,为开发者提供简单易用的****模型构建、训练、部署****等一站式产品服务,让模型应用更简单。
ModelScope旨在打造下一代开源的****模型即服务****共享平台,为****泛AI开发者****提供****灵活********、易用、低成本****的****一站式模型服务****产品,让****模型应用更简单****!
我们希望在汇集行业****领先的预训练模型****,减少开发者的重复研发成本,提供更加绿色环保、开源开放的****AI开发环境和模型服务****,助力绿色“数字经济”事业的建设。 ModelScope平台将以开源的方式提供多类优质模型,开发者可在平台上免费体验与下载使用。
若您也和我们有相同的初衷,欢迎关注我们,我们鼓励并支持个人或企业开发者与我们联系,平台将为您构建更好的支持服务,共同为泛AI社区做出贡献。
官网文档:https://modelscope.cn/docs/%E6%A6%82%E8%A7%88%E4%BB%8B%E7%BB%8D
**1、ModelScope **社区简介
ModelScope *社区是什么
基于达摩院机器智能、大模型、xr实验室等一些前沿技术所诞生的模型即服务共享平台。提供*开源数据集、开源模型、模型工具等,用社区的方式免费开发给广大个人、企业用户使用。它提供了模型管理检索、模型下载、模型调优和训练模型推理。目前版本优先开放了模型调优训练和推理,后续会开放模型部署及模型应用服务。
提供什么服务
Ø 开源开发框架:是一套Python的SDK,通过简单地集成方式可以快速的实现模型效果,比如一行代码实现模型推理,几行代码实现模型调优。
Ø 开源模型库:社区会提供一个开源模型库里面包含了全行业的SOTA模型。
Ø 开源数据集:社区会提供达摩院沉淀的电商领域数据集以及一些通用领域的数据集,结合业内一些经典数据集配合工具自动对外开放
Ø 实训框架:集成了PAI机器学习框架及DSW,可以实现在线的模型训练和推理工作,未来DSW中也会集成ModelScope社区整套的开发环境,可以让初阶用户快速的通过PAI和DSW实现模型把玩。同时还支持本地环境直接获取模型和复制相应的模型代码,在本地实现模型调优和推理工作。
Ø 文档教程:社区提供了全套的文档和教程可以更好帮助开发者使用社区相关服务。
Ø 开发者社区:社区提供了开发者交流、沟通及反馈的能力板块。
ModelScope *社区愿景
社区希望支持广大开发者通过社区平台学习和实践AI,从社区中可以获取所需的模型信息。对于*初阶开发者可以在社区中使用模型,对于中高阶开发者可以通过社区调优评测模型并用于自己的个性化业务场景。
同时社区也非常欢迎各类开发者加入社区并分享自身研发或沉淀的模型,通过在社区内不断学习实践及自由交流形成AI领域的意见领袖或行业先锋,为中国AI开源宏伟事业贡献力量。
2、对开发者好处
免费使用平台提供的预训练模型,支持免费下载运行;
一行命令实现模型预测,简单快速验证模型效果;
用自己的数据对模型进行调优,定制自己的个性化模型;
学习系统性的知识,结合实训,有效提升模型研发能力;
分享和贡献你的想法、评论与模型,让更多人认识你,在社区中成长;
3、ModelScope提供的服务

千亿参数大模型全面开放
多领域SOTA“百模”开源
10行代码实现模型finetune
1行代码实现模型推理
丰富的预训练****SOTA模型
覆盖NLP、CV、Audio等多领域的具有竞争力的SOTA模型,更有行业领先的多模态大模型,全部免费开放下载以及使用。
多元开放的****数据集
汇集行业和学术热门的公开数据集,更有阿里巴巴集团贡献的专业领域数据集等你来探索。
一行代码使用模型推理能力
提供基于模型的本地推理接口,以及线上模型推理预测服务,方便开发者快速验证与使用。
十行代码快速构建专属****行业模型
十行代码实现对预训练模型的调优训练(finetune),方便开发者基于行业数据集快速构建专属行业模型。
即开即用的在线开发平台
一键开启在线notebook实训平台,集成官方镜像免除环境安装困扰,链接澎湃云端算力,体验便捷的交互式编程。
灵活的模型框架与部署****方式
兼容主流AI框架,更好地实现模型迁移;多种模型训练与服务部署方式,提供更多自主可控的选择。
丰富的教学内容与技术****资源
提供友好的优质的教程内容与开放的社区氛围,帮助开发者学习成长。(内容持续更新中,敬请关注)
4、 ModelScope 社区平台覆盖多个领域的模型任务——CV、NLP、Audio、Multi-Modal
官方文档:
https://www.modelscope.cn/docs/%E4%BB%BB%E5%8A%A1%E7%9A%84%E4%BB%8B%E7%BB%8D
ModelScope 社区平台提供了覆盖多个领域的模型任务,包括自然语言处理(NLP)、计算机视觉(CV)、语音(Audio)、多模态(Multi-Modal)等,并提供相关任务的推理、训练等服务。
计算机视觉(CV):计算机视觉是指机器感知环境的能力。这一技术类别中的经典任务有图像形成、图像处理、图像提取和图像的三维推理。
自然语言处理(NLP):自然语言处理是人工智能和语言学领域的分支学科。自然语言处理融合了计算机科学,语言学和机器学习的交叉学科,利用计算机技术对语言进行处理和加工的科学,包括对词法、句法、语义等信息的识别、分类、抽取、生成等技术。
语音处理(Audio):语音处理指机器从大量的语音数据中提取语音特征,学习和发现其中蕴含的规律的过程。
多模态(Multi-Modal): 多模态主要是指让机器能够理解和处理自然界或人工定义的多种模态信息,如声音、语言、视觉信息和表格、点云信息等。多模态技术的目的是打通模态之间沟通的桥梁和通过信息互补提升理解各自模态的能力。常见任务有视觉问答,表格问答,图片描述以及目前火热的根据描述生成图片。
当前,ModelScope 社区平台支持的任务类型按照领域分为如下的任务类型,该任务列表将持续更新扩展。若您有新的任务类型和模型,建议提PR给我们,我们欢迎社区成员共同来贡献和维护相应的任务列表!
计算机视觉
任务(英文)任务(中文)任务说明ocr-detection文字检测将图像中的文字检测出来并返回检测点坐标位置ocr-recognition文字识别将图像中的文字识别出来并返回文本内容face-detection人脸检测对图像中的人脸进行检测并返回人脸坐标位置face-recognition人脸识别对图像中的人脸进行检测并返回人脸坐标位置human-detection人体检测对图像中的人体关键点进行检测并返回关键点标签与坐标位置body-2d-keypoints人体2D关键点检测图像中人体2D关键点位置human-object-interaction人物交互关系对图像中的肢体关键点和物品进行检测和识别对坐标信息进行处理face-image-generation人脸生成对图像中的人脸进行区域位置检测并生成虚拟人脸image-classification单标签图像分类对图像中的不同特征根据类别进行区分image-multilabel-classification多标签图像分类解析图像特征支持多个类别区分image-object-detection通用目标检测对输入图像中的较通用物体定位及类别判断image-object-detection目标检测-自动驾驶场景对自动驾驶中的场景进行目标检测,图像中的人、车辆及交通信息等进行实时解析并进行标注portrait-matting人像抠图对输入的图像将人体部分抠出并对背景进行透明化处理image-segmentation通用图像分割识别图像主体与图像背景进行分离image-protrait-enhancement人像增强对图像中的人像主体进行细节增强skin-retouching人像美肤对图像中的人像皮肤进行细节美化image-super-resolution图像超分辨对图像进行倍数放大且不丢失画面质量image-colorization图像上色对黑白图像进行区域解析并对其进行类别上色image-color-enhancement图像颜色增强对图像中色彩值进行解析并对其进行规则处理image-denoising图像降噪对图像中的噪点进行处理降低image-to-image-translation图像翻译将一张图片上的文字翻译成目标语言并生成新的图片image-to-image-generation以图生图根据输入图像生成新的类似图像image-style-transfer风格迁移对图像或视频的色彩风格进行另一种风格转化image-portrait-stylization人像卡通化对输入的图像进行卡通化处理,实现风格变化image-embedding图像表征对输入图像特征进行多模态匹配image-search搜索推荐根据输入图像进行范围匹配image-evaluation审核评估对图像进行解析并自动给出一个评估信息video-processing视频处理对视频信息进行自动运算处理live_category直播商品类目识别实时解析识别直播画面中的商品类别进行信息展示action_recognition行为识别对视频中的动作行为进行识别并返回类型video_category短视频内容分类解析短视频语义进行场景分类video-detecction视频检测对视频信息进行内容解析video-segmentation视频分割对视频信息进行背景和主体分离video-generation视频生成对视频进行解析匹配视频信息进行生成video-editing视频编辑对视频进行解析转化为可编辑状态video-embedding视频表征对视频特征进行多模态匹配video-search视频检索对视频解析根据规则提取部分信息reid-and-tracking目标跟踪及重识别可对图片和视频进行目标识别可重复识别video-evaluation视频审核评估根据规则对视频解析并给出评估结果video-ocr视频文本识别对视频中的文字内容进行识别video-captioning视频到文本将视频中的音频转化为文本信息virtual-try-on虚拟试衣给定模特图片和衣服图片,合成模特穿上给定衣服的图片3d-reconstruction三维重建对三维模型解析并重新构建3d-recognition三维识别对三维模型进行识别并进行标注3d-editing三维编辑对三维模型解析转化为可编辑状态3d-driven驱动交互对三维模型解析转为为动态效果3d-rendering渲染呈现对三维模型进行渲染并以图像展示ar-vr增强/虚拟现实对vr图像信息进行画面增强
自然语言处理
任务(英文)任务(中文)任务说明sentence-similarity句子相似度文本相似度服务提供不同文本之间相似度的计算,并输出一个介于0到1之间的分数,分数越大则文本之间的相似度越高nli自然语言推理判断两个句子(Premise, Hypothesis)或者两个词之间的语义关系sentiment-classification情感分类分析并给出文本的情感正负倾向zero-shot-classification零样本分类只需要提供待分类的句子和类别标签即可给出句子类别relation-extraction关系抽取非结构或半结构化数据中找出主体与客体之间存在的关系,并将其表示为实体关系三元组translation翻译将一种语言的文本翻译成指定语言的文本word-segmentation分词分词,将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列part-of-speech词性标注指为自然语言文本中的每个词汇赋予一个词性的过程,如名词、动词、副词等named-entity-recognition命名实体识别指识别自然语言文本中具有特定意义的实体,通用领域如人名、地名、机构名等text-error-correction文本纠错准确识别输入文本中出现的拼写错别字及其段落位置信息,并针对性给出正确的建议文本内容task-oriented conversation任务型对话主要指机器人为满足用户某一需求而产生的多轮对话,机器人通过理解、澄清等方式确定用户意图,继而通过答复、调用API等方式完成该任务open-domain conversation开放型对话无目的、无领域约束能够在开放域内进行有意义的对话text-generation文本生成模型接受各种形式的信息作为输入,包括文本或者非文本结构化信息等,生成可读的文字表述。table-question-answering表格问答给定一张表格和一个query,query是询问表格里面的一些信息,模型给出答案sentence-embedding句向量将输入文本从字符转化成向量表示fill-mask完形填空输入一段文本,同时将里面的部分词mask掉,模型通过理解上下文预测被mask的词multilingual-fill-mask多语言完形填空输入各种语言的文本,同时将里面的部分词mask掉,模型通过理解上下文预测被mask的词text-summarization文本摘要自动抽取输入文本中的关键信息并生成指定长度的摘要question-answering问答给定一长段文字,然后再给一个问题,然后理解长段文字之后,对这个问题进行解答。passage-ranking篇章排序给出大量的候选段落,然后再给一个问题,模型从大量的候选段落找出能回答问题的那个段落
语音处理
任务(英文)任务(中文)任务说明auto-speech-recognition语音识别将人类的语音信号转换成文本或者指令text-to-speech语音合成将文本转换成人类听的到的声音acoustic-noise-suppression语音降噪对语音信号进行处理,消除信号当中的噪声acoustic-echo-cancellation回声消除在信号处理领域用来抵消回波信号的方法keyword-spotting语音唤醒对指定的关键词进行识别audio-claassification音频分类对音频按照事件如“哭声”“爆炸声”“音乐”等事件类型进行识别和分类voice-activity-detection语音端点检测检测人类说话声音的语音起始位置以及中间片段
多模态技术
任务(英文)任务(中文)任务说明image-captioning图像描述根据图片生成一段文本描述visual-grounding视觉定位根据描述,在图片中定位出物体框text-to-image-synthesis文本生成图片根据描述,生成符合描述的图片multi-modal-embedding多模态表征抽取模态的向量表征,这些向量在同一个空间中(目前主要是图片和文本)visual-question-answering视觉问答根据图片和问题,给出文本答案visual-entailment视觉蕴含根据图片和一段假设,判断二者的蕴含关系image-text-retrieval图文检索根据图片/文本直接搜索文本/图片的数据
ModelScope的安装
ModelScope Library目前支持tensorflow,pytorch深度学习框架进行模型训练、推理, 在Python 3.7+, Pytorch 1.8+, Tensorflow1.15,Tensorflow 2.x上测试可运行。
注意:语音相关的功能仅支持 python3.7, tensorflow1.15.4的Linux环境使用。 其他功能可以在linux、mac x86等环境上安装使用。
T1、基于Anaconda安装
第一步,python环境配置
conda create -n modelscope python=3.7
conda activate modelscope
第二步,安装相关DL框架
pip3 install torch torchvision torchaudio
pip install --upgrade tensorflow
第三步,安装ModelScope library
NLP
如仅需体验NLP功能,可执行如下命令安装依赖:
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
CV
如仅需体验CV功能,可执行如下命令安装依赖:
pip install "modelscope[cv]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
多模态
如仅需体验多模态功能,可执行如下命令安装依赖:
pip install "modelscope[multi-modal]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
语音
如仅需体验语音功能,请执行如下命令:
pip install "modelscope[audio]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
第四步,测试
python -c "from modelscope.pipelines import pipeline;print(pipeline('word-segmentation')('今天天气不错,适合 出去游玩'))"
T2、直接在基于PAI-DSW的Jupyterlab内建模
ModelScope的使用方法
1、在线体验模型
模型库:https://www.modelscope.cn/models

2、创建模型或数据集并共享至ModelScope社区
管方文档:
https://modelscope.cn/docs/%E6%A8%A1%E5%9E%8B%E5%BA%93%E4%BB%8B%E7%BB%8D
第一步,登录账号,点击创建模型或数据集
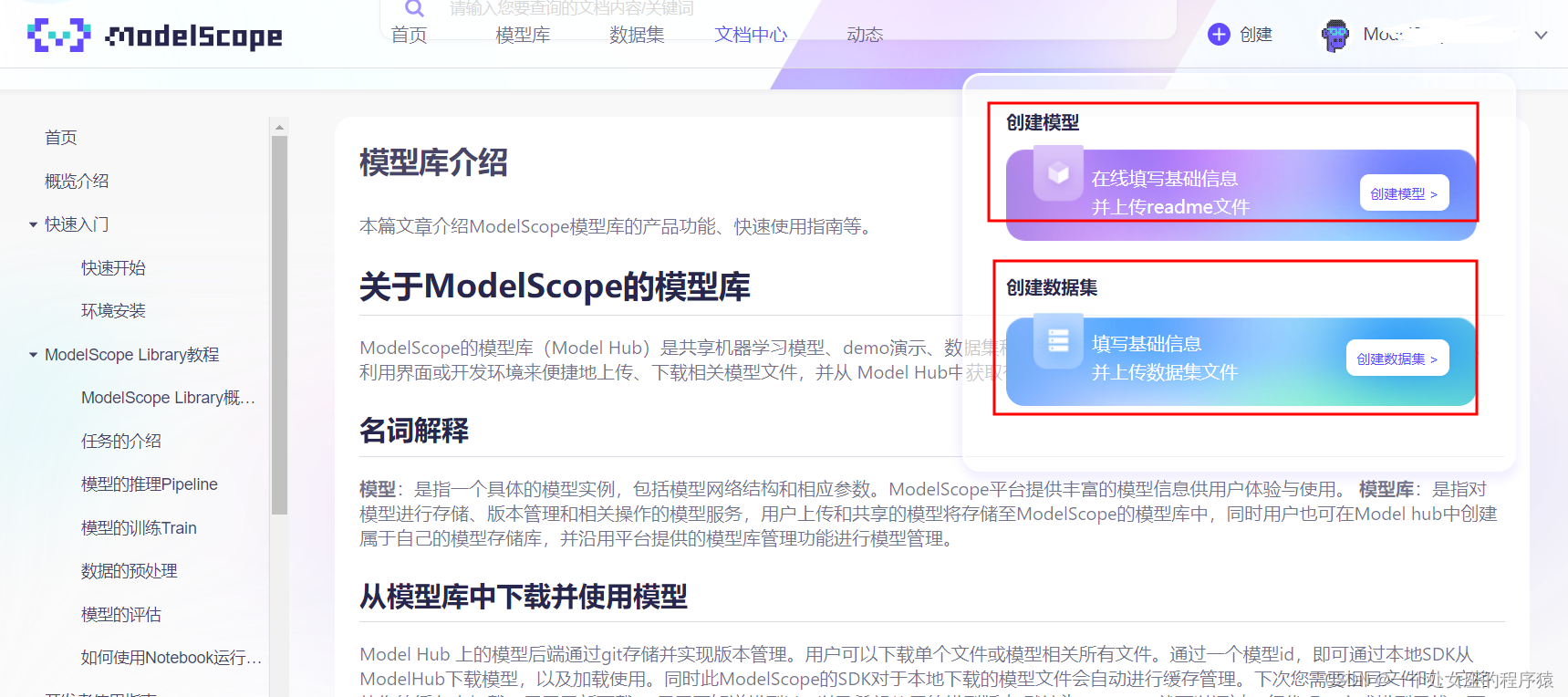
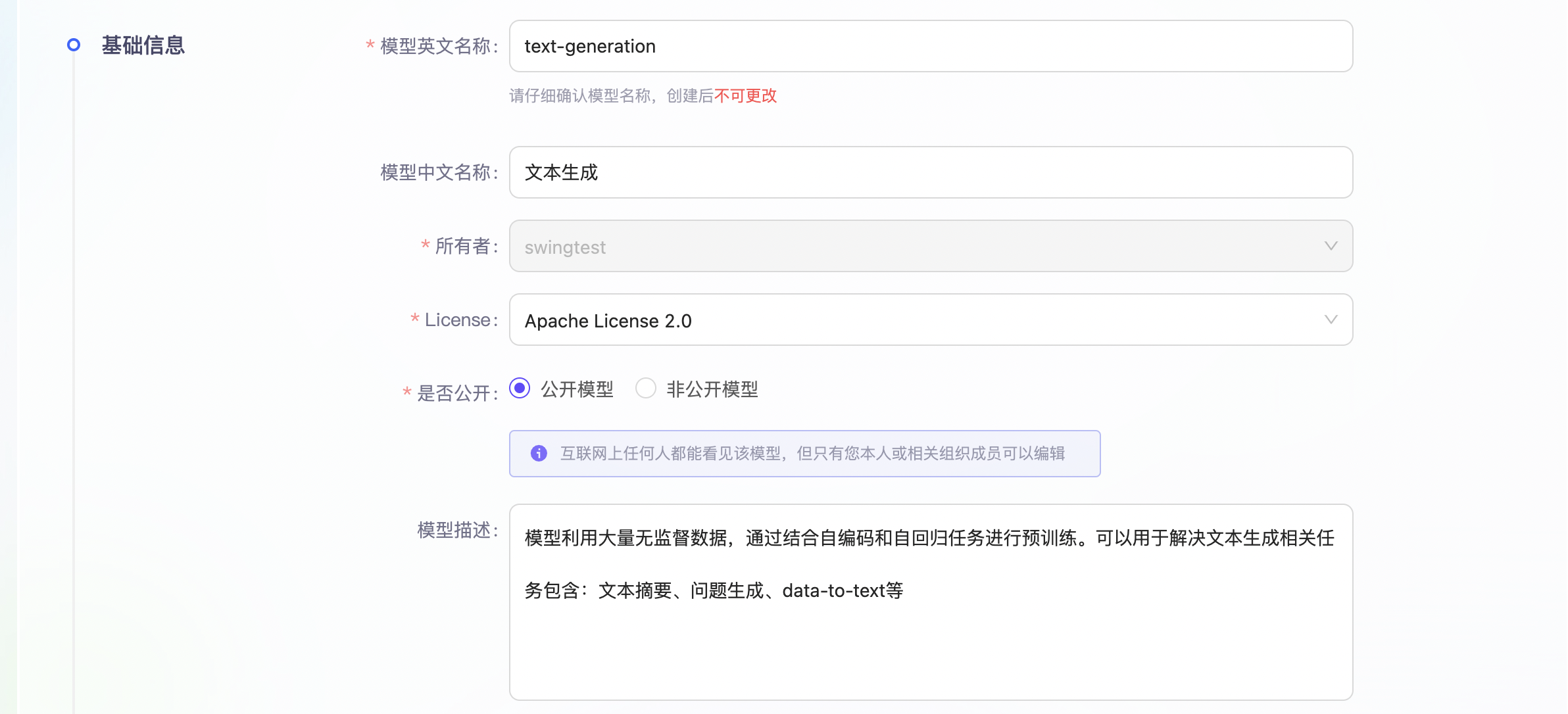
第二步,填写基础信息
1)基础信息包括您的模型英文名称、中文名、所有者、许可证类型、是否公开和模型描述。
- 许可证类型决定您的模型遵循对应的开源协议。
- 是否公开决定您的模型是否能被其他用户检索查看,若设置为非公开模型,则其他用户无法查看,仅您自己查看。您也可以创建后在设置页面进行权限的修改配置。
- 模型描述建议介绍您的模型的特性和应用场景,将展现在模型列表页方便用户搜索查询。
2)上传README文档。若您已有README文档,可直接在此处上传。若您没有README文档,系统将为您自动创建一个README文档。 为了让模型介绍更容易被理解和检索,我们推荐您按照模型卡片规范进行书写,具体可查看如何写好用的模型卡片。

第三步, 点击创建模型
系统将根据您上传的README.md文件进行解析,并展示在模型介绍页面。
右侧的demo根据task进行支持,当前支持的task类型将逐步开放,若您在readme中按照要求填写task和demo的示例代码等信息,系统将自动渲染出来。
若您没有README文档,可在模型文件中找到README.md并点击编辑进行在线编辑。

完成创建后,平台将为您分配一个存储地址,如下:
git lfs install
git clone http://... modelscope.cn/swingtest/text-generation.git
可通过页面或者git的方式将文件添加至该模型库中,也可通过页面上传相关的模型文件。
第四步,使用python SDK的方式添加模型
其中ACCESS_TOKEN可以通过用账号密码登录网站, 前往【个人中心】->【访问令牌】获取
from modelscope.hub.api import HubApi
# 1、登录
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)
# 2、创建模型
api.create_model(
model_id="damo/cv_unet_image-matting_damo",
visibility=ModelVisibility.PUBLIC,
license=Licenses.APACHE_V2,
chinese_name="这是我的第一个模型",
)
以上例子中,创建出模型的完整模型id为"damo/cv_unet_image-matting_damo",可以在Model/Pipeline种使用。
3、具体案例应用
CV之ModelScope:基于ModelScope框架的人脸人像数据集利用DCT-Net算法实现人像卡通化图文教程之详细攻略
CV之ModelScope:基于ModelScope框架的人脸人像数据集利用DCT-Net算法实现人像卡通化图文教程之详细攻略_一个处女座的程序猿的博客-CSDN博客
NLP之ModelScope:基于ModelScope框架的afqmc数据集利用StructBERT预训练模型的文本相似度算法实现文本分类任务图文教程之详细攻略
NLP之ModelScope:基于ModelScope框架的afqmc数据集利用StructBERT预训练模型的文本相似度算法实现文本分类任务图文教程之详细攻略_一个处女座的程序猿的博客-CSDN博客
版权归原作者 一个处女座的程序猿 所有, 如有侵权,请联系我们删除。