
社团结构的划分及实现过程
022036930019 张志龙 2022.11.18
题目
什么是网络社团结构,介绍给出社团结构划分几种常见算法,并且给出你实现的过程。同时对一些真实网络进行划分与真实情况进行比较,并且给出你的解释。
文章目录
社团结构划分的算法介绍
从Barabasi在1999年首次发表关于无标度网络的论文后,对复杂网络的研究引起许多研究工作者的关注。复杂网络存在于人类现实社会中,存在于虚拟空间中,形态各异,复杂多变,但在统计意义上呈现很多相似的属性[1]。在这些复杂网络中,存在一些内部链接紧密,外部链接稀疏的节点,这些节点组成的网络结构称为网络社团结构。
在网络科学中对社团的定义,主要从以下几点假设出发:
1) 网络的社团结构仅由其连接模式决定。
2)社团是网络中局部紧密连接的子图。
社团结构的划分通常是利用网络连接的结构信息从网络中发现模块化的社团结构,通常也被称为社团检测和图聚类。社团结构划分有很多算法,以下列出四种:
1)GN(Girvan-Newman)算法[2]
GN算法是分裂算法,该算法依据边不属于社团的程度,逐步删除不同社区的节点之间的连接,最终将网络拆解成彼此独立的社区。GN算法复杂度量级为O(L2N),在稀疏网络上为O(N3)。
2)Louvain算法
Louvain算法是贪婪算法。由Blondel [3]等人提出,是基于模块化,进行局部优化的层次凝聚方法。该算法的优点在于速度快,可以较短时间内实现大规模网络以不同粒度的社团划分,并且无需指定社团的数量,当模块化不再增益时,迭代自动停止。Louvain算法复杂度量级为O(nlogn)。该算法优点是:1. 时间复杂度小;2.支持权重图;3.提供分层的社区结果,可根据需要选择层级;4.适用于研究大型网络。
3)FN算法
Newman[4]在GN算法基础上提出快速模块度优化FN算法,FN算法是一种基于贪婪算法思想的凝聚算法。该算法先使每个顶点初始化一个社团,选择使模块度增值最大的社团进行合并,从而在此过程中形成树图。最后在树图的所有层次中选择模块度最大的社团划分作为最终划分。
4)CNN算法
针对FN算法的缺点,付常雷[5]提出一种基于Newman快速算法改进的社团划分算法,将社团贡献度(community contribution)作为社团合并依据。CNN算法的合并步骤直接根据各个社团的贡献度大小,然后选择贡献度最小且相连的两个社团合并,在时间性能上较FN算法有较大程度的提高。
算法实现
GN算法的实现
借助python中的networkx、community库,可以很方便的实现GN算法。
1)导入网络数据
2)调用community库里的girvan-Newman函数
comp = community.girvan_newman(G) # GN算法
GN算法步骤:
① 计算网络中所有边介数
②找到介数最高的边并删除,然后重新计算边介数
③重复第二步,直到所有边都被移除
k = 4 # 想要4个社区
limited = itertools.takewhile(lambda c: len(c) <= k, comp) # 层次感迭代器
for communities in limited:
b = list(sorted(c) for c in communities)
3)绘制网络图
pos = nx.spring_layout(G) # 节点的布局为spring型
NodeId = list(G.nodes())
print("NodeID:%s"%NodeId)
node_size = [G.degree(i)**1.2*90 for i in NodeId] # 节点大小
plt.figure(figsize = (8,6)) # 图片大小
nx.draw(G,pos, with_labels=False, node_size =node_size, node_color='w', node_shape = '.')
'''
node_size表示节点大小
node_color表示节点颜色
node_shape表示节点形状
with_labels=True表示节点是否带标签
'''
color_list = ['brown','orange','r','g','b','y','m','gray','black','c','pink']
# node_shape = ['s','o','H','D']
print(len(b))
for i in range(len(b)):
# nx.draw_networkx_nodes(G, pos, nodelist=b[i], node_color=color_list[i], node_shape=node_shape[i], with_labels=True)
print (b[i])
nx.draw_networkx_nodes(G, pos, nodelist=b[i], node_color=color_list[i], with_labels=True)
plt.show()
Louvain算法的实现
借助python中的networkx、community库,可以快速实现Louvain算法。
1)导入网络数据
2)调用community库里的Louvain库
partition = community_louvain.best_partition(G)
在Louvain算法过程中,每个阶段分为两步:
- Step 1:模块度优化通过对局部的节点社团进行改变,优化模块度,计算模块度增益。
- Step2:社团合并将识别出的社团聚合为超级节点,以构建新的网络。跳转到第一步,直至模块度不再提升,或者提升小于某个阈值。
3)绘制网络图
# draw the graph
pos = nx.spring_layout(G)
# color the nodes according to their partition
cmap = cm.get_cmap('viridis', max(partition.values()) + 1)
nx.draw_networkx_nodes(G, pos, partition.keys(), node_size=40,
cmap=cmap, node_color=list(partition.values()))
nx.draw_networkx_edges(G, pos, alpha=0.5)
plt.show()
真实网络的划分和真实情况的比较
权力的游戏
《权力的游戏》是2011年美国HBO推出的史诗奇幻题材的电视剧,里面人物众多,关系错综复杂。分析《权力的游戏》中人物的社团结构,有助于理解人物之间的关系。
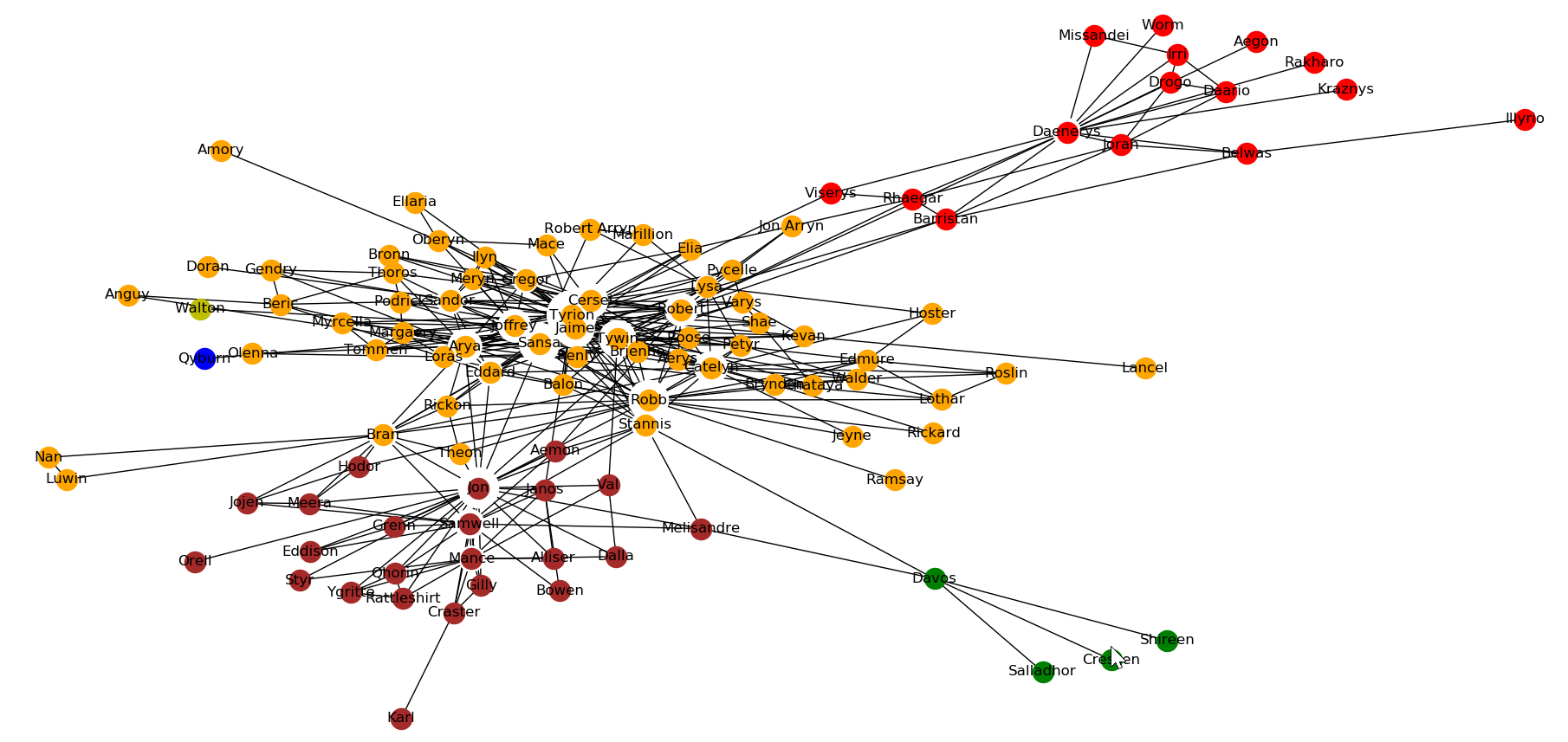
以《权力的游戏》的人物关系为数据集,通过GN算法划分的社团结构如下图所示:
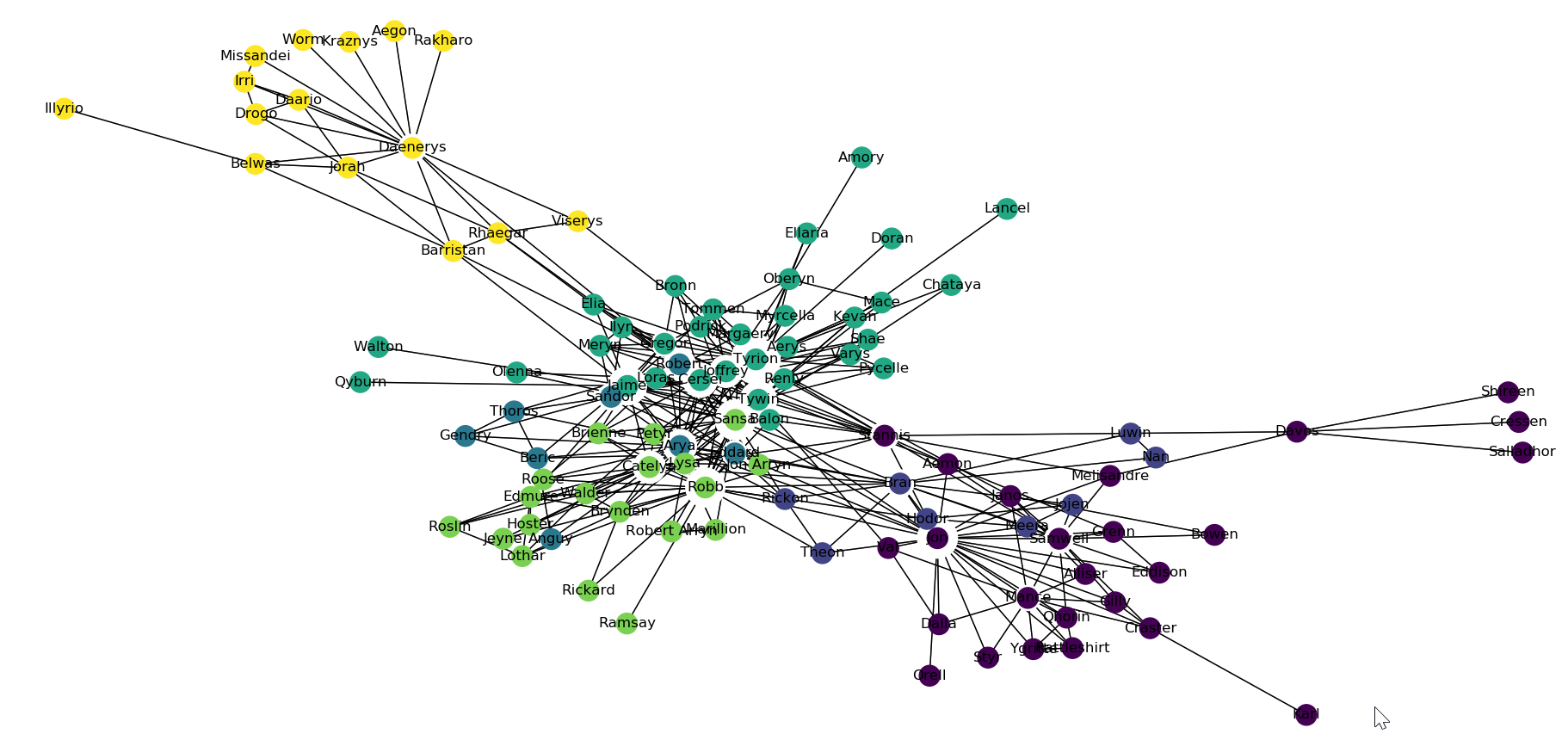
通过Louvain算法划分的社团结构如下图所示:
比较以上两种算法的社团划分,根据度大小排序如下:
['Tyrion', 'Tywin', 'Lysa', 'Pycelle', 'Qyburn', 'Myrcella', 'Luwin', 'Stannis', 'Styr', 'Grenn', 'Arya', 'Bran', 'Brynden', 'Gregor', 'Brienne', 'Bronn', 'Craster', 'Drogo', 'Irri', 'Kraznys', 'Cressen', 'Orell', 'Robert', 'Joffrey', 'Jon', 'Roose', 'Loras', 'Hodor', 'Jojen', 'Podrick', 'Lothar', 'Hoster', 'Robb', 'Roslin', 'Jorah', 'Worm', 'Tommen', 'Bowen', 'Jon Arryn', 'Robert Arryn', 'Doran', 'Anguy', 'Amory', 'Alliser', 'Illyrio', 'Elia', 'Ilyn', 'Olenna', 'Ellaria', 'Rickon', 'Missandei', 'Viserys', 'Gilly', 'Rickard', 'Thoros', 'Theon', 'Shae', 'Rhaegar', 'Qhorin', 'Chataya', 'Shireen', 'Ygritte', 'Aemon', 'Aerys', 'Beric', 'Cersei', 'Gendry', 'Belwas', 'Meera', 'Jeyne', 'Petyr', 'Meryn', 'Aegon', 'Renly', 'Kevan', 'Melisandre', 'Edmure', 'Eddard', 'Eddison', 'Oberyn', 'Samwell', 'Jaime', 'Mance', 'Sandor', 'Balon', 'Barristan', 'Nan', 'Walder', 'Catelyn', 'Sansa', 'Varys', 'Karl', 'Daario', 'Daenerys', 'Rakharo', 'Davos', 'Salladhor', 'Janos', 'Margaery', 'Dalla', 'Rattleshirt', 'Val', 'Lancel', 'Marillion', 'Mace', 'Ramsay', 'Walton']
根据社团来分,输出如下:
{'Aemon': 0, 'Grenn': 0, 'Samwell': 0, 'Aerys': 1, 'Jaime': 1, 'Robert': 3, 'Tyrion': 1, 'Tywin': 1, 'Alliser': 0, 'Mance': 0, 'Amory': 1, 'Oberyn': 1, 'Arya': 3, 'Anguy': 3, 'Beric': 3, 'Bran': 6, 'Brynden': 5, 'Cersei': 1, 'Gendry': 3, 'Gregor': 1, 'Joffrey': 1, 'Jon': 0, 'Rickon': 6, 'Roose': 5, 'Sandor': 3, 'Thoros': 3, 'Balon': 1, 'Loras': 1, 'Belwas': 2, 'Barristan': 2, 'Illyrio': 2, 'Hodor': 6, 'Jojen': 6, 'Luwin': 6, 'Meera': 6, 'Nan': 6, 'Theon': 6, 'Brienne': 5, 'Bronn': 1, 'Podrick': 1, 'Lothar': 5, 'Walder': 5, 'Catelyn': 5, 'Edmure': 5, 'Hoster': 5, 'Jeyne': 5, 'Lysa': 5, 'Petyr': 5, 'Robb': 5, 'Roslin': 5, 'Sansa': 5, 'Stannis': 1, 'Elia': 1, 'Ilyn': 1, 'Meryn': 1, 'Pycelle': 1, 'Shae': 1, 'Varys': 1, 'Craster': 0, 'Karl': 0, 'Daario': 2, 'Drogo': 2, 'Irri': 2, 'Daenerys': 2, 'Aegon': 2, 'Jorah': 2, 'Kraznys': 2, 'Missandei': 2, 'Rakharo': 2, 'Rhaegar': 2, 'Viserys': 2, 'Worm': 2, 'Davos': 4, 'Cressen': 4, 'Salladhor': 4, 'Eddard': 3, 'Eddison': 0, 'Gilly': 0, 'Qyburn': 1, 'Renly': 1, 'Tommen': 1, 'Janos': 0, 'Bowen': 0, 'Kevan': 1, 'Margaery': 1, 'Myrcella': 1, 'Dalla': 0, 'Melisandre': 0, 'Orell': 0, 'Qhorin': 0, 'Rattleshirt': 0, 'Styr': 0, 'Val': 0, 'Ygritte': 0, 'Jon Arryn': 5, 'Lancel': 1, 'Olenna': 5, 'Marillion': 5, 'Robert Arryn': 5, 'Ellaria': 1, 'Mace': 1, 'Rickard': 5, 'Ramsay': 5, 'Chataya': 1, 'Shireen': 4, 'Doran': 1, 'Walton': 1}
处于社团0的有:Aemon,Grenn,Samwell,Alliser,Mance,Jon,Karl,Eddison,Gilly,Janos,Bowen,Dalla,Melisandre,Orell,Qhorin,Rattleshirt,Styr,Val,Ygritte
处于社团1的有:Aerys,Jaime,Tyrion,Tywin,Amory,Oberyn,Cersei,Gregor,Joffrey,Loras,Bronn,Podrick,Elia,Ilyn,Meryn,Pycelle,Shae,Varys,Kevan,Tommen,Renly,Margaery,Myrcella,Mace,Chataya,Walton。
根据《权力的游戏》中人物关系,Tyrion(小指头)、Aerys(疯王),Tywin(瑟后父亲),Cersei(瑟后),Jaime(弑君者),Gregor(魔山)、Oberyn(红毒蛇),这些都是围绕着Cersei为中心的人物,而Louvain算法也成功的把他们划分到一个社团里。可以发现Louvain算法不仅速度快,而且准确性也比较高。
微博粉丝圈
随着社交媒体的发展,网络空间的数据种类和规模大幅度增长,特别是以微博、抖音为代表的各类社交平台蓬勃发展。这些复杂网络中的网络结构承载着各种关系模式,蕴含了很多有价值的结构信息。本文以微博平台上大V的粉丝圈进行研究对象,研究粉丝关注的人员是否有共同的属性。
以某微博ID号为例,首先爬取微博的粉丝以及粉丝的关注者,形成微博粉丝数据集。因处理能力有限,只抓取前600名粉丝,然后研究600名粉丝的关注者情况。每个粉丝的关注者限定为600个,那么数据集的数据一共不超过600*600=360000条(有些粉丝关注对象没有600个)。360000条关系数据应该算是比较大规模的网络了。
采用GN算法最大的问题是对应大规模网络时计算时间较长,不如Lovain算法收敛快,时间短。
通过Louvain算法划分的社团结构如下图所示:
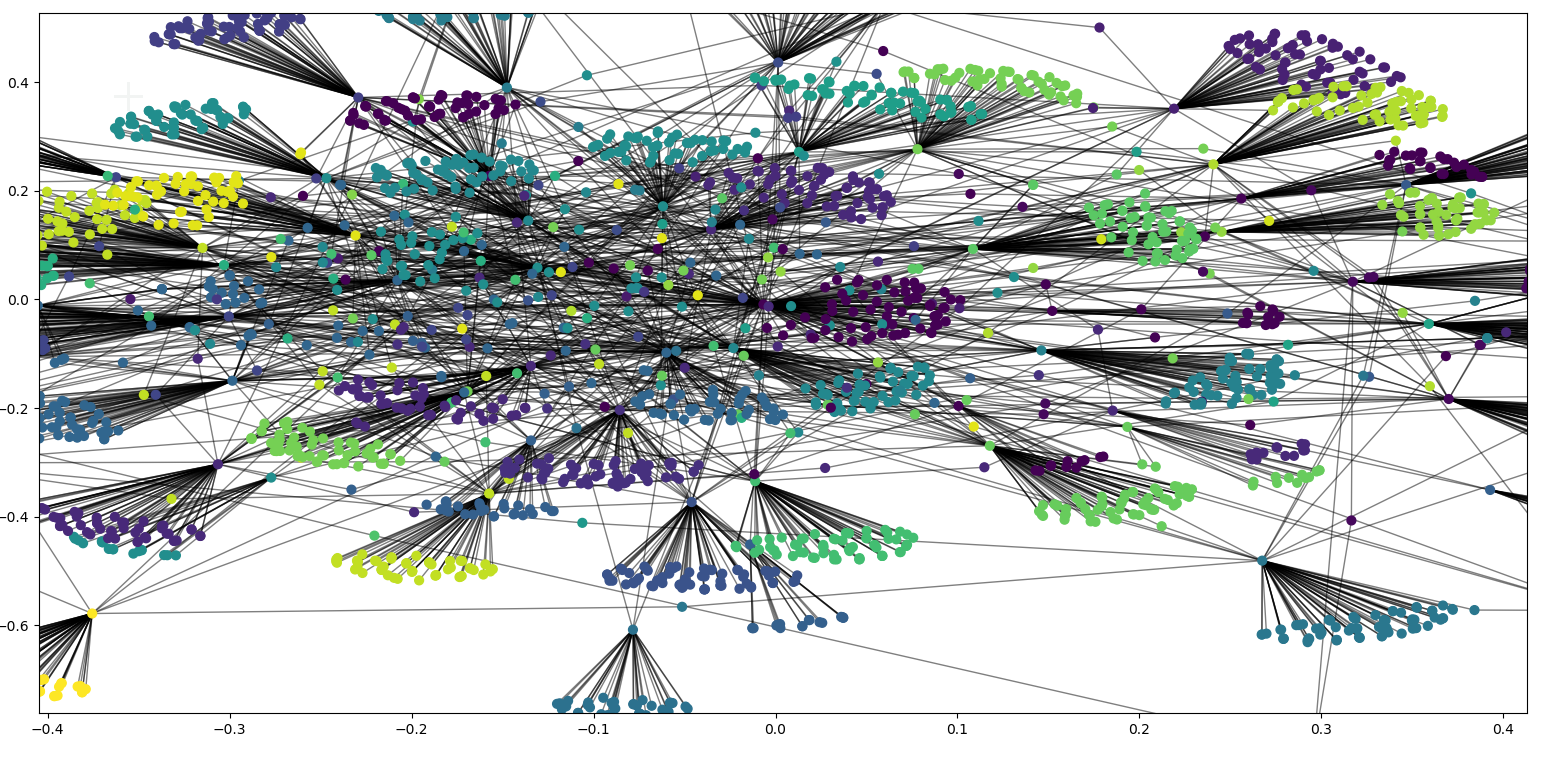
可以看出Louvain算法能够划分出比较好的社团结构,粉丝关注的对象相同的作为一个社团,体现了“物以类聚,人以群分”,与实际的情况相似。(由于网络规模较大,GN算法时间复杂度是O(N3),最终由于CPU处理能力有限,未成功计算出社团结构的划分。)
代码实现
见附录。
另参见https://github.com/zealane/weibofan
参考文献
[1] 李辉,陈福才,张建朋,等. 复杂网络中的社团发现算法综述[J]. 计算机应用研究,2021,38(6):1611-1618. DOI:10.19734/j.issn.1001-3695.2020.06.0211.
[2] Newman M E J, Girvan M. Finding and evaluating community structure in networks[J]. Physical Review E, 2004, 69(2):026113.
[3] Blondel V D, Guillaume J L, Lambiotte R, et al. Fast unfolding of
communities in large networks[ J]. Journal of Statistical Mechanics:Theory and Experiment, 2008, 2008(10):P10008.
[4] NEWMAN M E J. Fast algorithm for detecting community structure in networks[J]. Physical Review E,2004,69(6):066133
[5] 付常雷. 一种基于Newman快速算法改进的社团划分算法[J]. 计算机技术与发展,2018,28(1):33-35,40. DOI:10.3969/j.issn.1673-629X.2018.01.007.
附录
weibofan.py
#!/usr/bin/python
# -*-coding:utf-8-*-
import json
import os
import subprocess
import sys
import time
import csv
import requests
def get_fans(uid, page, type, ck):
'''
根据type类型,获取指定uid的粉丝或关注人数据
:param uid: 目标用户uid
:param page: 分页
:param type: 类型。0:粉丝,1:关注者
:param ck: cookie
:return: dict
'''
u = 'https://weibo.com/ajax/friendships/friends'
p = {
"page": page,
"uid": uid,
}
if type == 0:
p.update({
"relate": "fans",
"type": "fans",
"newFollowerCount": "0"
})
h = {
'authority': 'weibo.com',
'cache-control': 'max-age=0',
'sec-ch-ua': '"Google Chrome";v="89", "Chromium";v="89", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': 'https://weibo.com/u/page/follow/2671109275?relate=fans',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': ck
}
r = requests.get(url=u, headers=h, params=p)
try:
return json.loads(r.text)
except:
print('执行失败,cookie可能失效')
input()
sys.exit(1)
def write_data(uid, fan_id, name, province, city, location, type):
'''
追加写入结果
:param uid:
:param fan_id:
:param name:
:param province:
:param city:
:param location:
:param type:
:return:
'''
os.makedirs('data', exist_ok=True)
with open(os.path.join('data', '%s___%s.txt' % (uid, type)), 'a') as f:
# 粉丝uid 昵称 省份代码 城市代码 所在地
f.write('%s\t%s\t%s\t%s\t%s\t\n' % (fan_id, name, province, city, location))
def write_tocsv(row_str):
with open ("fans.csv", "w", newline='') as csvfile:
writer = csv.writer (csvfile)
writer.writerows (row_str)
# f_fan.write(row_str)
# f_fan.write("\n")
csvfile.close ()
def get_appionted_fans(uid, cookie):
type = 0
init_info = get_fans (uid, 1, type, cookie)
if init_info["ok"] == 0: # 如果无法获得粉丝列表,则返回0
display_total_number = 0
else:
display_total_number = init_info["display_total_number"]
print ('%s的粉丝数:%s'%uid % display_total_number)
page_nums = display_total_number // 20
if (page_nums > NP):
page_nums = NP
print ('分页数:%s' % page_nums)
# 开始遍历,如果只想获取部分,可直接修改display_total_number为对应数值
for i in range (1, page_nums):
print ('第【%s】页' % i)
fans_list = get_fans (uid, i, type, cookie)['users']
for fan in fans_list:
fan_id = fan['id']
name = fan['name']
str = [uid, fan['id'], fan['name']]
row_str.append (str)
time.sleep (0.2)
# write_data(uid, fan_id, name, province, city, location, type)
type = 1 # 关注者
for k in range (0, NP):
uid = row_str[k][1]
print ("##########【%s】#################" % k)
# 计算对应类型的分页
init_info = get_fans (uid, 1, type, cookie)
if init_info["ok"] == 0:
display_total_number = 0
else:
display_total_number = init_info["total_number"]
print ('关注数:%s' % display_total_number)
page_nums = display_total_number // 20
if (page_nums > NP):
page_nums = NP
print ('分页数:%s' % page_nums)
# 开始遍历,如果只想获取部分,可直接修改page_nums为对应数值
for i in range (1, page_nums):
print ('第【%s】页' % i)
fans_list = get_fans (uid, i, type, cookie)['users']
for fan in fans_list:
str = [uid, fan['id'], fan['name']]
row_str_fan.append (str)
time.sleep (0.2)
write_tocsv(row_str_fan)
if __name__ == '__main__':
NP = 20
row_str = [] # 大V的粉丝
row_str_fan = [] # 粉丝的关注对象
# 获取用户输入参数
BASE_DIR = os.path.abspath(os.path.dirname(__file__))
ck = input('请输入cookie,输入完成后回车:')
uid = '1647486362'
get_appionted_fans(uid, ck)
uid = '7454177482'
get_appionted_fans (uid, ck)
# 打开输出目录
# subprocess.Popen(
# r'explorer "%s"' % (os.path.join(BASE_DIR, 'data')))
# input('\n\n运行结束,正在打开输出目录...')
weibo_gn.py
import networkx as nx
import csv
import matplotlib.pyplot as plt
from networkx.algorithms import community #
import itertools
import matplotlib.pyplot as plt
#G = nx.karate_club_graph() # 空手道俱乐部
filePath="fans.csv"
G = nx.Graph()
with open(filePath,'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
# print(row[0])
#
# print(row[1])
G.add_edge(row[0],row[1])
#print (G.degree)
degrees = G.nodes()
print(sorted(degrees, key=lambda x:x[1], reverse=True))
comp = community.girvan_newman(G) # GN算法
k = 6 # 想要4个社区
limited = itertools.takewhile(lambda c: len(c) <= k, comp) # 层次感迭代器
for communities in limited:
b = list(sorted(c) for c in communities)
pos = nx.spring_layout(G) # 节点的布局为spring型
NodeId = list(G.nodes())
#print("NodeID:%s"%NodeId)
node_size = [G.degree(i)**1.2*90 for i in NodeId] # 节点大小
plt.figure(figsize = (8,6)) # 图片大小
nx.draw(G,pos, with_labels=True, node_size =node_size, node_color='w', node_shape = '.')
'''
node_size表示节点大小
node_color表示节点颜色
node_shape表示节点形状
with_labels=True表示节点是否带标签
'''
color_list = ['brown','orange','r','g','b','y','m','gray','black','c','pink']
# node_shape = ['s','o','H','D']
print(len(b))
for i in range(len(b)):
# nx.draw_networkx_nodes(G, pos, nodelist=b[i], node_color=color_list[i], node_shape=node_shape[i], with_labels=True)
#print (b[i])
nx.draw_networkx_nodes(G, pos, nodelist=b[i], node_color=color_list[i], with_labels=True)
plt.show()
weibo_louvain.py
import networkx as nx
import csv
import matplotlib.pyplot as plt
import matplotlib.cm as cm
#from networkx.algorithms import community #
import itertools
import community as community_louvain
#G = nx.karate_club_graph() # 空手道俱乐部
filePath="fans.csv"
G = nx.Graph()
with open(filePath,'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
# print(row[0])
#
# print(row[1])
G.add_edge(row[0],row[1])
# print(G.number_of_nodes())
# for n in G.nodes():
# print("degree",G.degree(n))
# if G.degree(n)==1:
# print("del")
# G.remove_node(n)
#获取平均度
d = dict(G.degree)
# print(d)
print("平均度:",sum(d.values())/len(G.nodes))
print(sorted(d, key=lambda x:x[1], reverse=True))
#获取度分布
# nx_h=nx.degree_histogram(G)
#
# #度分布直方图
# x= list(range(max(d.values())+1))
# y= [i/sum(nx.degree_histogram(G)) for i in nx_h]
#
# plt.bar(x,y,width=0.5,color="blue")
# plt.xlabel("$k$")
# plt.ylabel("$p_k$")
# plt.xlim([0,100])
#first compute the best partition
partition = community_louvain.best_partition(G)
print(partition)
# compute the best partition
#partition = community_louvain.best_partition(G)
# draw the graph
pos = nx.spring_layout(G)
NodeId = list(G.nodes())
print("NodeID:%s"%NodeId)
node_size = [G.degree(i)**1.2*90 for i in NodeId] # 节点大小
nx.draw(G,pos, with_labels=True, node_size =node_size, node_color='w', node_shape = '.')
# color the nodes according to their partition
cmap = cm.get_cmap('viridis', max(partition.values()) + 1)
# nx.draw_networkx_nodes(G, pos, partition.keys(), node_size=40,
# cmap=cmap, node_color=list(partition.values()),with_labels=True)
nx.draw_networkx_nodes(G, pos, partition.keys(),node_color=list(partition.values()),with_labels=True)
nx.draw_networkx_edges(G, pos, alpha=0.5)
plt.show()
版权归原作者 张志龙 所有, 如有侵权,请联系我们删除。