
Qualcomm® AI Engine Direct 使用手册(6)
4.1.2 HTP - QNN HTP 分析(1)
QNN HTP 分析
基本分析
用于执行的基本分析报告提供了主机和加速器上的图形推理摘要。
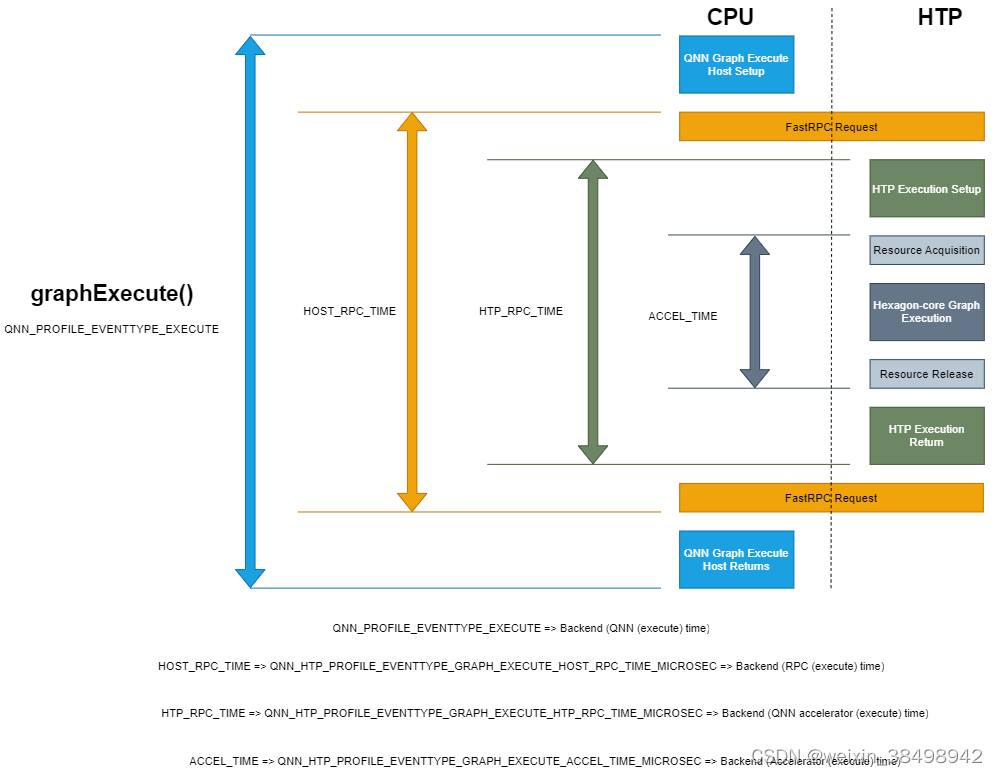
HTP 执行基本分析事件 图表说明了 基本 HTP 执行分析事件以及在推理过程中如何测量它们。
HTP 执行基本分析事件
详细和 Linting 分析
详细的分析报告按周期计数而不是以微秒为单位的时间提供每个操作的分析结果。 由于并行执行,没有从周期计数到微秒的直接转换方法 行动的。因此,建议使用每层周期时序作为比较/测量的参考 相对性能,以了解其中哪些正在使用较低/较高的周期来完成执行。
特定于 HTP 的 linting 分析报告提供主线程上的每个操作周期计数以及后台 执行信息。在主线程上,每个操作都必须等待一些周期,因为执行 开始执行自己之前的最后一个操作。此等待期可归因于多种因素,例如 调度或等待某些后台 HVX 或 DMA 活动完成。在 linting 分析报告中,每个 op 有一个与之关联的周期计数,表示实际执行该 op 所花费的周期数 主线程。还有一个与每个操作关联的“等待”条目,对应于等待时间 前面提到过。除了描述主线程活动的这两个周期计数之外,每个操作还有两个 更多条目来描述后台活动。这两个条目中的第一个是“重叠”条目,表示 当操作在主线程上执行时,至少一个后台操作所花费的周期数。下一个, 每个操作都有一个“重叠(等待)”条目,该条目类似于“等待”条目,但周期 本条目中报告的对应于“等待”期(即,在至少一个后台操作上花费的周期,而 主线程正在等待)。不考虑主线程操作正在等待的后台操作 作为背景活动,因此不会对重叠条目报告的计数产生影响。每一个 重叠条目后面还有几条缩进线(最多 10 条),指示操作的名称 这有助于各自的重叠周期计数。最后,每个操作还有一个“资源”条目列表 该操作使用的不同资源。 可以通过在以下情况下指定 --profiling_level=backend 来启用特定于 HTP 的 linting 分析级别: 运行 qnn-net-run 以便使用后端特定配置文件中指定的分析级别。请 请参阅 qnn-net-run 的文档以了解有关 libQnnHtpNetRunExtensions.so 和特定于后端的更多信息 配置文件。对于 linting 分析,后端特定的配置文件应指定以下选项 与任何其他所需的选项:
{"graphs":{...},"devices":[{..."profiling_level":"linting",..."cores":[{...}]}]}
请注意,上述配置结构将从 SDK 2.20 版本开始弃用,支持的新配置如下所示:
{"graphs":[{....}....],"devices":[{..."profiling_level":"linting",..."cores":[{...}]}]}
使用此分析级别生成的分析输出可以使用 qnn-profile-viewer 工具及其 libQnnHtpProfilingReader.so 或 libQnnChrometraceProfilingReader.so 读取器插件。 libQnnHtpProfilingReader.so reader 提供每次运行的原始输出,而 libQnnChrometraceProfilingReader.so 提供平均值 所有运行的输出。此外,还可以生成包含 chrometrace 格式的分析数据的文件 如果在使用以下命令运行 qnn-profile-viewer 工具时使用 --output 选项指定了输出文件 libQnnChrometraceProfilingReader.so 阅读器插件。
要从推理中检索 linting 信息,需要执行以下步骤:
- 将 $QNN_SDK_ROOT 设置为您所需的 QNN 版本
- 运行“源$QNN_SDK_ROOT/bin/envsetup.sh”
- 将需要的文件推送到设备- $QNN_SDK_ROOT/lib/aarch64-android/libQnnHtpNetRunExtensions.so- backend_extension_config.json- htp_config.json
- 在设备上运行推理,确保添加以下参数:“–profiling_level=backend 和 --config_file=backend_extension_config.json”
- 将输出日志拉取到linux
- 使用 qnn-profile-viewer 时,请确保指定以下参数:“–-reader $QNN_SDK_ROOT/lib/x86_64-linux-clang/libQnnHtpProfilingReader.so” backend_extension_config.json
{"backend_extensions":{"shared_library_path":"./libQnnHtpNetRunExtensions.so","config_file_path":"./htp_config.json"}}
htp_config.json
{"devices":[{"profiling_level":"linting"}]}
推理命令示例
./qnn-net-run --retrieve_context sample_model.bin --backend libQnnHtp.so --input_list target_raw_list.txt --config_file backend_extension_config.json --output_dir output_htp --profiling_level backend
配置文件查看器命令示例
$QNN_SDK_ROOT/bin/x86_64-linux-clang/qnn-profile-viewer --reader $QNN_SDK_ROOT/lib/x86_64-linux-clang/libQnnHtpProfilingReader.so --input_log ./output/qnn-profiling-data_0.log
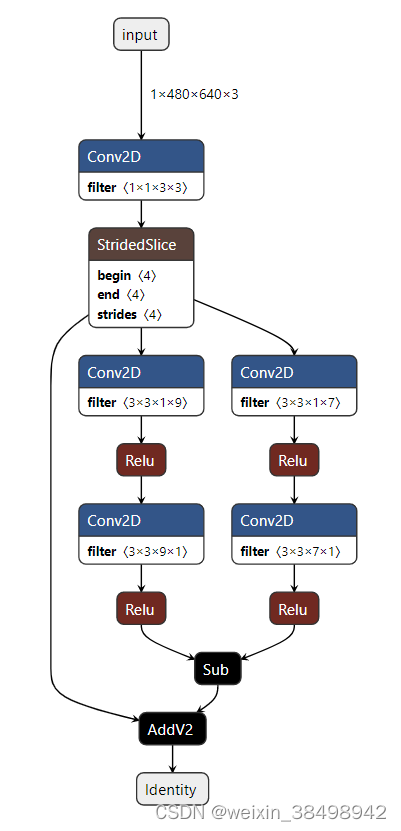
展示模型 1 图表展示了具有两个 每个分支在其结果用于子操作之前执行几次卷积。
展示模型1
该模型的 linting 分析输出如下:
Execute Stats(Average):------------------------
Total Inference Time:---------------------
NetRun:16792 us
Backend(RPC(execute) time):16242 us
Backend(QNN accelerator(execute) time):15190 us
Backend(Num times yield occured):0 count
Backend(Time for initial VTCM acquire):0 us
Backend(Time for HVX + HMX power on and acquire):0 us
Backend(Accelerator(critical path execute)time(cycles)):4327266 cycles
Input OpId_2(cycles):0 cycles
Wait(Scheduler) time:0 cycles
Overlap time:0 cycles
Overlap(wait) time:0 cycles
Resources:OpId_0(cycles):8036 cycles
Wait(Scheduler) time:629 cycles
Overlap time:4770 cycles
Overlap(wait) time:565 cycles
Resources:
model_convStart_Conv2D:OpId_21(cycles):147075 cycles
Wait(Scheduler) time:32 cycles
Overlap time:85292 cycles
model_sub_sub:OpId_57
Output OpId_3
model_add_add:OpId_58
model_tf_op_layer_stride_stride:OpId_24
model_convStart_Conv2D:OpId_21
Overlap(wait) time:32 cycles
model_convStart_Conv2D:OpId_21
Resources: HVX, HMX, DMA
model_tf_op_layer_stride_stride:OpId_24(cycles):146494 cycles
Wait(Scheduler) time:0 cycles
Overlap time:70807 cycles
model_add_add:OpId_58
Output OpId_3
model_convStart_Conv2D:OpId_21
model_tf_op_layer_stride_stride:OpId_24
Overlap(wait) time:0 cycles
Resources: HVX
model_convLeft1_Conv2D:OpId_34(cycles):288249 cycles
Wait(Scheduler) time:425 cycles
Overlap time:195988 cycles
Output OpId_3
model_add_add:OpId_58
model_tf_op_layer_stride_stride:OpId_24
model_convStart_Conv2D:OpId_21
Overlap(wait) time:304 cycles
Output OpId_3
model_add_add:OpId_58
model_convStart_Conv2D:OpId_21
Resources: HMX, DMA
model_convRight1_Conv2D:OpId_41(cycles):220391 cycles
Wait(Scheduler) time:803 cycles
Overlap time:135268 cycles
Output OpId_3
model_add_add:OpId_58
model_tf_op_layer_stride_stride:OpId_24
model_convStart_Conv2D:OpId_21
Overlap(wait) time:557 cycles
Output OpId_3
model_tf_op_layer_stride_stride:OpId_24
model_convStart_Conv2D:OpId_21
Resources: HMX, DMA
model_convRight2_Conv2D:OpId_48(cycles):181016 cycles
Wait(Scheduler) time:1090 cycles
Overlap time:69323 cycles
model_sub_sub:OpId_57
model_convStart_Conv2D:OpId_21
Output OpId_3
model_add_add:OpId_58
Overlap(wait) time:489 cycles
model_sub_sub:OpId_57
model_convStart_Conv2D:OpId_21
Output OpId_3
model_add_add:OpId_58
Resources: HMX, DMA
model_convLeft2_Conv2D:OpId_55(cycles):233736 cycles
Wait(Scheduler) time:1059 cycles
Overlap time:93020 cycles
model_sub_sub:OpId_57
model_convStart_Conv2D:OpId_21
Output OpId_3
model_add_add:OpId_58
model_tf_op_layer_stride_stride:OpId_24
Overlap(wait) time:464 cycles
model_sub_sub:OpId_57
model_convStart_Conv2D:OpId_21
Output OpId_3
model_add_add:OpId_58
Resources: HMX, DMA
model_sub_sub:OpId_57(cycles):2165162 cycles
Wait(Scheduler) time:0 cycles
Overlap time:465046 cycles
model_sub_sub:OpId_57
Output OpId_3
model_add_add:OpId_58
model_convStart_Conv2D:OpId_21
model_tf_op_layer_stride_stride:OpId_24
Overlap(wait) time:0 cycles
Resources: HVX
model_add_add:OpId_58(cycles):525971 cycles
Wait(Scheduler) time:0 cycles
Overlap time:481468 cycles
model_tf_op_layer_stride_stride:OpId_24
model_convStart_Conv2D:OpId_21
Output OpId_3
model_add_add:OpId_58
Overlap(wait) time:0 cycles
Resources: HVX
Output OpId_3(cycles):407091 cycles
Wait(Scheduler) time:0 cycles
Overlap time:115120 cycles
Overlap(wait) time:0 cycles
Resources: HVX
该模型的 linting 分析 chrometrace 输出如下:
展示模型 1 Chrometrace

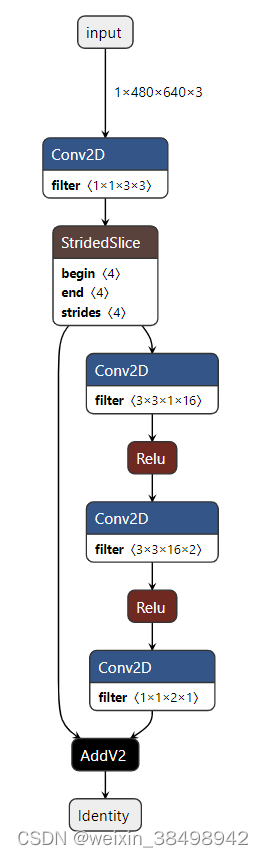
从输出中可以看出,子操作 (OpId_57) 是最重要的贡献者 占总执行时间的 50% 左右。该操作也没有显着的并行操作 执行 - 其重叠时间为 465046 个周期,约占总执行时间的 21.5% - 表明这个操作是一个很好的优化瓶颈。我们可以设计一个等效模型 如展示模型 1 优化 所示 图表合并两个分支并手动用带有权重的卷积替换子操作 设计为使其执行与子操作相同的任务。
展示模型 1 优化
此优化模型的 linting 分析输出如下:
Execute Stats(Average):------------------------
Total Inference Time:---------------------
NetRun:11884 us
Backend(RPC(execute) time):11525 us
Backend(QNN accelerator(execute) time):10481 us
Backend(Num times yield occured):0 count
Backend(Time for initial VTCM acquire):0 us
Backend(Time for HVX + HMX power on and acquire):0 us
Backend(Accelerator(critical path execute)time(cycles)):1374349 cycles
Input OpId_2(cycles):0 cycles
Wait(Scheduler) time:0 cycles
Overlap time:0 cycles
Overlap(wait) time:0 cycles
Resources:OpId_0(cycles):3500 cycles
Wait(Scheduler) time:1284 cycles
Overlap time:3221 cycles
Overlap(wait) time:1268 cycles
Resources:
model_convStart_Conv2D:OpId_21(cycles):487448 cycles
Wait(Scheduler) time:32 cycles
Overlap time:475888 cycles
Output OpId_3
model_add_add:OpId_50
model_tf_op_layer_stride_1_stride_1:OpId_24
model_convStart_Conv2D:OpId_21
Overlap(wait) time:32 cycles
model_convStart_Conv2D:OpId_21
Resources: HVX, HMX, DMA
model_tf_op_layer_stride_1_stride_1:OpId_24(cycles):10422 cycles
Wait(Scheduler) time:0 cycles
Overlap time:10075 cycles
model_convStart_Conv2D:OpId_21
model_tf_op_layer_stride_1_stride_1:OpId_24
Overlap(wait) time:0 cycles
Resources: HVX
model_convCombined1_Conv2D:OpId_34(cycles):337711 cycles
Wait(Scheduler) time:82 cycles
Overlap time:307394 cycles
Output OpId_3
model_tf_op_layer_stride_1_stride_1:OpId_24
model_convStart_Conv2D:OpId_21
Overlap(wait) time:50 cycles
Output OpId_3
model_convStart_Conv2D:OpId_21
Resources: HMX, DMA
model_convCombined2_Conv2D:OpId_41(cycles):295022 cycles
Wait(Scheduler) time:1184 cycles
Overlap time:286062 cycles
model_add_add:OpId_50
Output OpId_3
model_convStart_Conv2D:OpId_21
model_tf_op_layer_stride_1_stride_1:OpId_24
Overlap(wait) time:1140 cycles
model_add_add:OpId_50
Output OpId_3
model_convStart_Conv2D:OpId_21
model_tf_op_layer_stride_1_stride_1:OpId_24
Resources: HMX, DMA
model_subConv_Conv2D:OpId_48(cycles):48720 cycles
Wait(Scheduler) time:1186 cycles
Overlap time:46686 cycles
model_add_add:OpId_50
model_tf_op_layer_stride_1_stride_1:OpId_24
Output OpId_3
model_convStart_Conv2D:OpId_21
Overlap(wait) time:1142 cycles
model_add_add:OpId_50
Output OpId_3
model_convStart_Conv2D:OpId_21
Resources: HMX, DMA
model_add_add:OpId_50(cycles):110698 cycles
Wait(Scheduler) time:0 cycles
Overlap time:108524 cycles
model_add_add:OpId_50
Output OpId_3
model_convStart_Conv2D:OpId_21
model_tf_op_layer_stride_1_stride_1:OpId_24
Overlap(wait) time:0 cycles
Resources: HVX
Output OpId_3(cycles):77054 cycles
Wait(Scheduler) time:0 cycles
Overlap time:75438 cycles
Overlap(wait) time:0 cycles
Resources: HVX
版权归原作者 weixin_38498942 所有, 如有侵权,请联系我们删除。