ai写的论文查重率高吗?分享4款ai论文查重软件
如果AI写作软件所使用的训练数据与已有的文献高度相似,或者用户输入的关键词和句式与已有的文献相同,那么生成的文本内容可能与已有的文献高度重复,从而导致较高的查重率。在实际应用中,AI写作论文的查重率并不是固定的,受到算法、数据、主题、领域和用户操作等多种因素的影响。因此,选择全面且可靠的文献数据库,
顶级期刊TMI论文解读┆PLHN: 用于DCE-MRI影像中乳腺肿瘤分割的原型学习引导混合网络
本研究提出了原型学习引导混合网络(PLHN),通过结合卷积层和Transformer,实现对MRI图像中乳腺肿瘤的高效3D分割。实验结果表明,PLHN在乳腺肿瘤分割任务中性能优越,有助于提高临床诊断效率。
人脸识别-特征算法
Eigenfaces、Fisherfaces和LBPH都是人脸识别中的经典算法,它们各自具有不同的特点和优势。Eigenfaces和Fisherfaces关注全局信息,而LBPH注重局部特征。在实际应用中,可以根据具体需求和场景选择合适的算法进行人脸识别。例如,在需要处理大规模数据集时,可以选择Ei
机器视觉AI场景为什么用Python比C++多?
选择 Python还是 C++ 取决于具体的项目需求和应用场景。如果注重开发效率、快速原型设计和丰富的库支持,Python 是一个不错的选择;如果对性能要求极高或需要进行底层控制,C++ 可能更合适。在实际应用中,也可以结合两者的优势,使用 Python进行快速开发和原型设计,然后用 C++ 实现关
人工智能【AI】:未来的驱动力
人工智能是计算机科学的一个分支,它试图理解智能的实质,并生产出一种新的能以人类智能相似方式做出反应的智能机器。这包括诸如语音识别、图像识别、自然语言处理和机器学习等领域。人工智能可以定义为使计算机系统执行通常需要人类智能的任务的技术,如视觉识别、语言理解、决策和学习。AI的历史可以追溯到20世纪40
植物数据集-全面多种杂草识别的数据集
CWD30数据集,专为作物杂草识别任务设计。CWD30包含219,770张高分辨率图像,涵盖20种杂草和10种作物的不同生长阶段、多角度视角和多种环境条件。数据集从不同地理位置和季节的农田收集,确保了数据的代表性。其分层分类法实现了细粒度分类,有助于开发更精确和强大的深度学习模型。广泛的基线实验表明
【AI前沿】计算机视觉的10个突破性进展:实际应用、挑战与方向
【AI前沿】计算机视觉的10个突破性进展:实际应用、挑战与方向
计算机视觉的应用36-人工智能时代计算机视觉技术在电力系统中的应用
在电力系统这个传统与创新交汇的领域,计算机视觉技术作为人工智能的重要分支,正逐步展现其变革潜力。2023年,几个前沿的计算机视觉模型——SAM(Segment-Anything)、YOLOv8、DINOv2等,凭借其卓越的性能和适应性,成为电力系统智能化升级的关键推手。本部分将深入探讨这些模型在电力
【数据增强】图像与标签同时进行增强(含完整代码)
常用的数据增强方法包括图像旋转(旋转不同角度)、平移(在水平和垂直方向上移动)、缩放(放大或缩小图像)、裁剪(随机选择图像的子区域)、翻转(水平或垂直翻转图像)、颜色变换(调整对比度、亮度、饱和度等)、添加噪声(例如高斯噪声或椒盐噪声)、镜像(左右或上下镜像)以及混合(如Mixup和CutMix,通
简单线性插值去马赛克算法的Python实现
马赛克图像是一种通过在传感器上覆盖彩色滤光片阵列(CFA)生成的单通道图像。最常见的CFA模式是Bayer模式,其中包括红(R)、绿(G)和蓝(B)三种滤光片,以特定模式排列。去马赛克过程就是从这种单通道图像中恢复出三通道(RGB)的彩色图像。本文实现的去马赛克算法是基于简单线性插值的。它利用邻近像
如何在 Windows 系统环境下安装 Tesseract OCR? ( •̀ ω •́ )✧
访问Tesseract的GitHub发布页面或第三方下载站点,下载适合你操作系统的版本(最新版本)。
视频风格化技术原理及现状
在整个调研过程中,相关论文中各方案的对比都是比较欠缺的,反映一个基本事实,客观评估生成效果是困难的,现有的评估方法主要是如Frechet视频距离和Inception Score(IS),主要强调生成的视频和真实视频分布之间的差异,难以准确反映视频生成的综合质量。的提出激发了更多的工作。传统的扩散模型
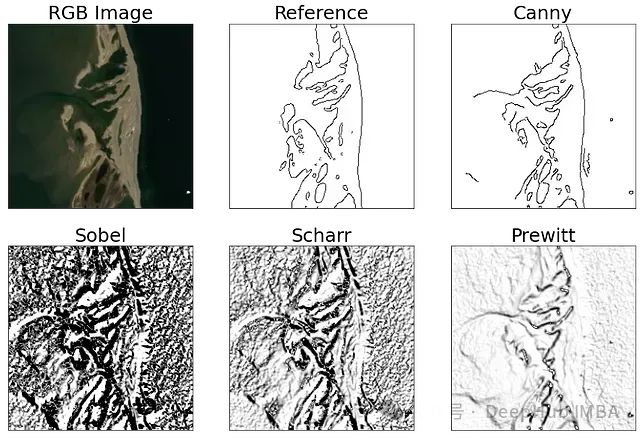
边缘检测评估方法:FOM、RMSE、PSNR和SSIM对比实验和理论研究
本文通过理论分析和实证实验,明确展示了FOM在边缘检测评估中的优越性。相比之下,RMSE、PSNR和SSIM在这一任务中表现出明显的局限性。
三本IEEE会议“一区顶刊”大PK!年发文量>1000+,千万别错过!
物联网服务、应用、标准和测试平台,如流数据管理和挖掘平台、服务中间件、开放服务平台、语义服务管理、安全和隐私保护协议、智能服务和应用设计示例、物联网应用支持等。物联网架构,如以物为中心、以数据为中心、以服务为中心的架构、CPS 和 SCADA 平台、面向物联网的未来互联网设计、基于云的物联网以及系统

图像数据增强库综述:10个强大图像增强工具对比与分析
本文旨在全面介绍当前广泛使用的图像数据增强库,分析其特点和适用场景,以辅助研究人员和开发者选择最适合其需求的工具。
opencv-python实战项目六:全景图像拼接
opencv 图像拼接技术
人工智能时代,程序员如何保持核心竞争力?
人工智能时代,程序员保持核心竞争力的三大杀器
华为 昇腾 310P 系列 AI 处理器支持 140Tops 的 AI 算力。
PCIe Gen4.0 ,兼容 3.0/2.0/1.0 XGE、SATA、USB 等接口。领域,有着极高的性价比,具有超强算力、 超高能效、高性能特征检索、安全启动等优势。基于 模组设计的 AI 智能产品,可根据实际应用需求,可应用于机器人、无人机、无人。支持 I2C、 UART、 CAN-FD、
【人脸识别】数据集宝藏合集,速看!
数据库中的许多图像包含不止一张带注释的人脸(293 张带有 1 张人脸的图像,53 张带有 2 张人脸的图像和 53 张带有 [3, 7] 人脸的图像)。该数据集是视听的,因此对于许多其他应用也很有用,例如 - 视觉语音合成、语音分离、从人脸到语音的跨模态转换(反之亦然)以及从视频中训练人脸识别以补
什么是粒子群算法?(新手入门)附代码
(Particle Swarm Optimization, PSO)是一种基于群体智能的优化算法,由Kennedy和Eberhart在1995年提出。PSO模拟了鸟群、鱼群等生物群体的社会行为,通过个体间的信息共享来找到问题的最优解。



