【目标检测】YOLOV8实战入门(五)模型预测
预测模式可以为各种任务生成预测,在使用流模式时返回结果对象列表或结果对象的内存高效生成器。文件加载,用户可以提供图像或视频来执行推理。模型预测输入图像或视频中对象的类别和位置。的流媒体模式应用于长视频或大型预测源,否则结果将在内存中累积并最终导致内存不足错误。函数在图像对象中绘制结果。它绘制在结果对
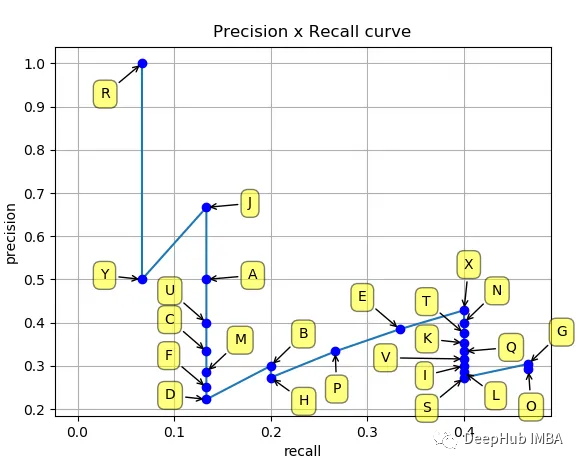
深入了解平均精度(mAP):通过精确率-召回率曲线评估目标检测性能
平均精度(Average Precision,mAP)是一种常用的用于评估目标检测模型性能的指标。
Yolov5目标检测项目的运行以及常见报错
上期我们引入了一个目标检测的模型,并对其所需的环境配置进行了搭建。这期主要针对项目如何运行以及运行过程中的常见报错进行记录以及分享,毕竟报错在深度学习的环境搭建也是很常见的嘛,如何解决报错问题还是很有必要去分析以及学习的。
从YOLOv1到YOLOv8的YOLO系列最新综述【2023年4月】
这是一篇2023.4.4发表的arXiv关于YOLO系列综述
用YOLOv5和MobileViTs骨干网络革新目标检测:高效准确AI视觉的未来
MobileViT是一种结合了ViT和MobileNetV3的深度神经网络,旨在充分利用两种网络结构的优势,并避免它们各自的缺点。ViT是基于注意力机制的视觉转换器,适用于图像分类任务,表现出色。
YOLOv8 Bug及解决方案汇总
m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
YOLOv5改进训练过程中置信度损失上升
按照以上分析原因进行修改之后发现,削减模型复杂度值之后,依然会出现该现象,所以过拟合原因排除;总结分析出三个主要原因:1.模型计算量过大,出现过拟合的现象,需要对网络框架进行削减,降低网络模型复杂度。3.学习率以及optimizer的选择出现问题,需要进行更换。从tensorboard的图像过程中看
【YOLOv5】Backbone、Neck、Head各模块详解
详解Yolov5原理及backbone、neck、head三个模块的作用及结构。
YOLOv5改进:引入DenseNet思想打造密集连接模块,彻底提升目标检测性能
目录一、密集连接模块的介绍1、密集连接的概念2、密集连接与残差连接的对比3、DenseNet的结构二、 YOLOv5中引入密集连接模块的原因1、密集连接模块对于目标检测的优势2、密集连接模块对目标检测性能的影响三、 YOLOv5中密集连接模块的具体实现1、使用DenseNet的基本单元DenseBl
车牌识别算法 基于yolov5的车牌检测+crnn中文车牌识别 支持12种中文车牌识别
最全车牌识别算法,支持12种中文车牌类型了。基于yolov5的车牌检测 crnn车牌识别 关键点定位车牌1.单行蓝牌 2.单行黄牌 3.新能源车牌 4.白色警用车牌 5 教练车牌 6 武警车牌 7 双层黄牌 8 双层武警 9 使馆车牌 10 港澳牌车 11 双层农用车牌12 民航车牌
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
全网最全YOLOv5项目目录结构超详细分析。逐个文件注释,小白上手必备
yolov5+deepsort目标检测与跟踪(毕业设计+代码)
yolov5+deepsort目标检测与跟踪
YOLOV5轻量化改进-MobileNetV3替换骨干网络
YOLOV5轻量化改进-MobileNetV3替换骨干网络
【yolo训练数据集】标注好的垃圾分类数据集共享
超赞的yolo训练所用垃圾分类数据集共享——标注好的3000+图片
行人车辆检测与计数系统(Python+YOLOv5深度学习模型+清新界面)
行人车辆检测与计数系统用于交通路口行人及车辆检测计数,道路人流量、车流量智能监测,方便记录、显示、查看和保存检测结果。本文详细介绍行人车辆检测,在介绍算法原理的同时,给出Python的实现代码、PyQt的UI界面以及训练数据集。在界面中可以选择各种行人车辆图片、视频进行检测识别与计数;可对图像中存在
YOLO 模型的评估指标——IOU、Precision、Recall、F1-score、mAP
YOLO是最先进的目标检测模型之一。目标检测问题相比分类问题要更加复杂,因为目标检测不仅要把类别预测正确,还要预测出这个类别具体在哪个位置。我将目标识别的评估指标总结为两部分,一部分为预测框的预测指标,另一部分为分类预测指标。
YOLOv7如何提高目标检测的速度和精度,基于模型结构提高目标检测速度
目标检测是计算机视觉领域中的一个重要任务,它的主要目标是在图像或视频中准确地定位和识别特定目标。
提速YOLOv7:用MobileNetV3更换骨干网络加速目标检测
本专栏均为全网独家首发,🚀订阅该专栏后,该专栏内所有文章可看,内附代码,可直接使用,改进的方法均是2023年最近的模型、方法和注意力机制。每一篇都做了实验,并附有实验结果分析,模型对比。
YOLOv7升级换代:EfficientNet骨干网络助力更精准目标检测
目标检测是计算机视觉中的重要研究方向,其应用广泛,例如自动驾驶、安防监控等。目前,基于深度学习的目标检测方法已经取得了很大进展,其中YOLO(You Only Look Once)系列模型以其快速且准确的特点备受关注。
【Segment Anything Model】论文+代码实战调用SAM模型预训练权重+相关论文
上一篇已经全局初步介绍了segment anything model和其功能,本篇作为进阶使用。代码实战案例,同时介绍了二创论文。



