
NVFP4量化技术深度解析:4位精度下实现2.3倍推理加速
本文将从技术角度深入分析NVFP4与主流4位量化方法(AWQ、AutoRound、bitsandbytes)的性能对比,并探讨在Blackwell GPU环境下采用NVFP4方案的实际价值。
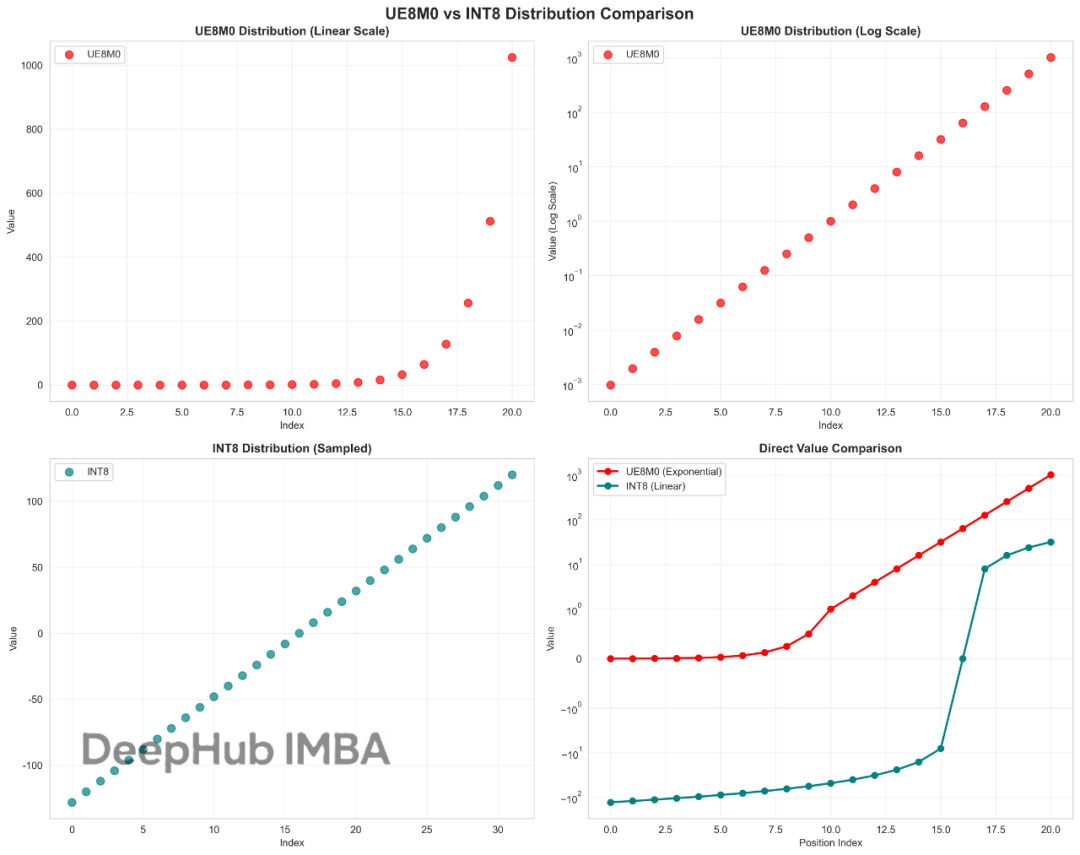
这也许就是DeepSeek V3.1性能提升的关键:UE8M0与INT8量化技术对比与优势分析
UE8M0作为FP8格式家族中的一个特殊变体,我们今天来看看这个UE8M0到底是什么。
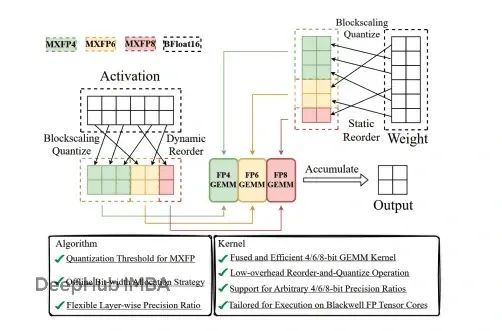
MXFP4量化:如何在80GB GPU上运行1200亿参数的GPT-OSS模型
GPT-OSS通过创新的量化技术实现了突破性进展。该系统能够在单个80GB GPU上运行1200亿参数模型,同时保持竞争性的基准测试性能。
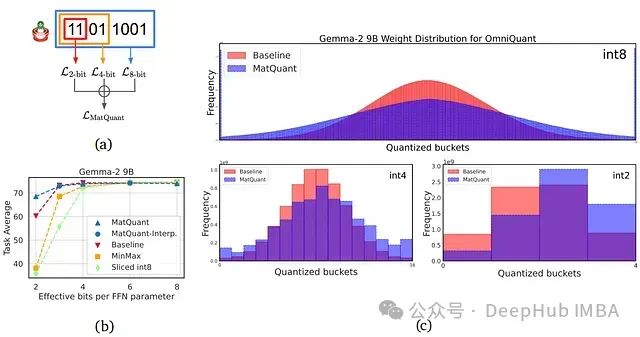
DeepMind发布Matryoshka(套娃)量化:利用嵌套表示实现多精度LLM的低比特深度学习
本文将介绍 Google DeepMind 提出的 Matryoshka 量化技术,该技术通过从单个大型语言模型 (LLM) 实现多精度模型部署,从而革新深度学习。我们将深入研究这项创新技术如何提高 LLM 的效率和准确性。

使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。
大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。
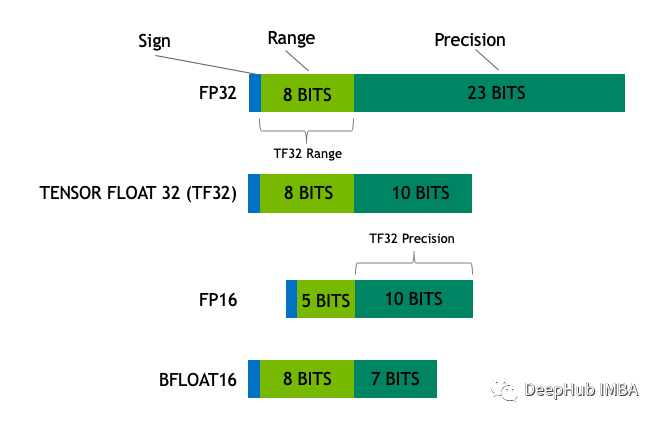
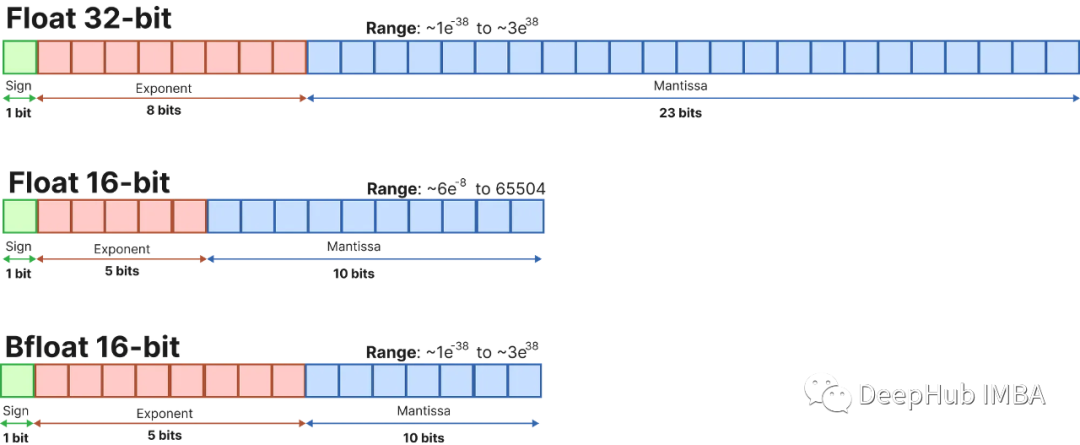
16,8和4位浮点数是如何工作的
在本文中,我们将介绍最流行的浮点格式,创建一个简单的神经网络,并了解它是如何工作的。
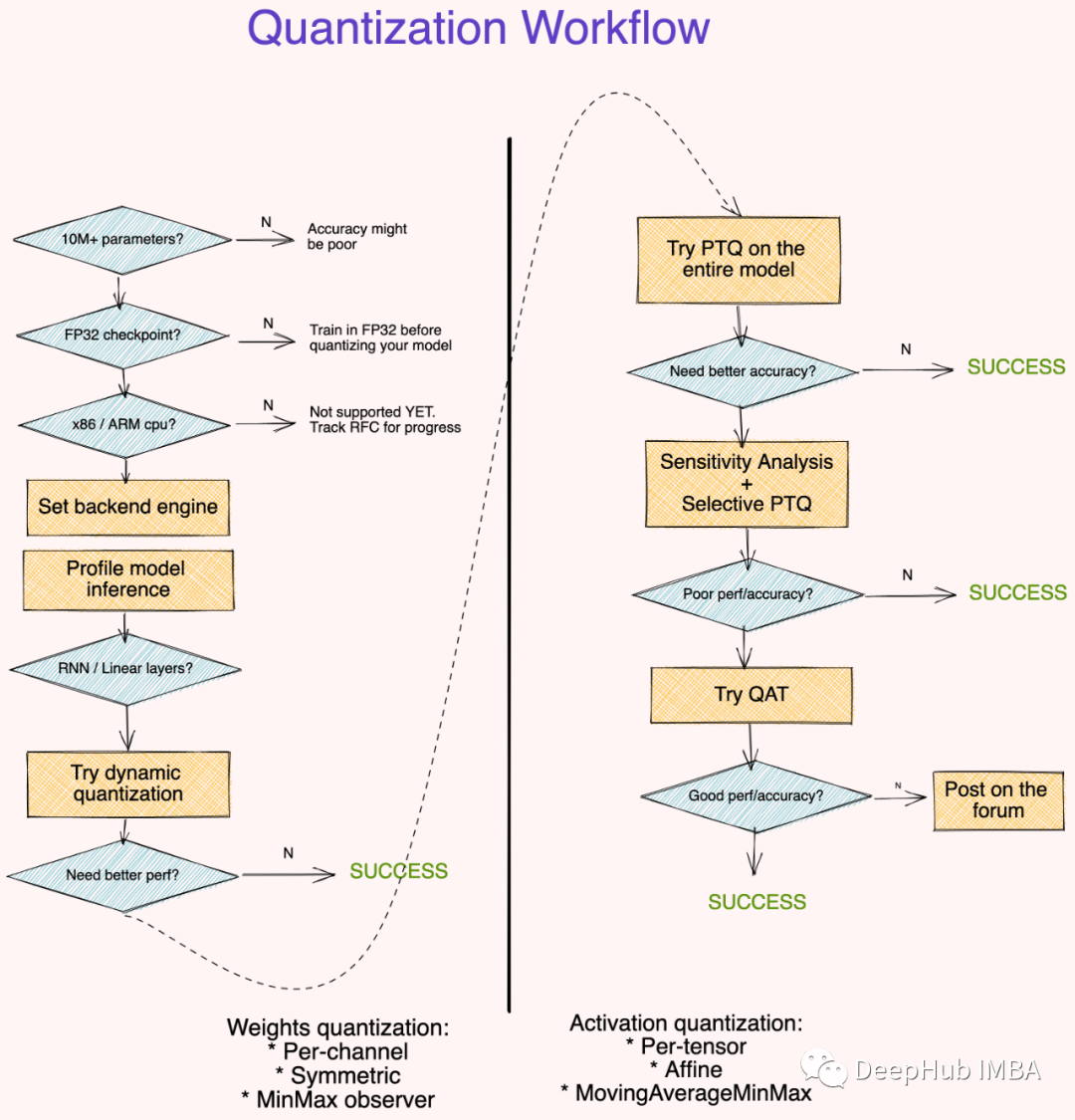
量化自定义PyTorch模型入门教程
基础模型与量化模型具有相似的准确性,但模型尺寸大大减小,这在我们希望将其部署到服务器或低功耗设备上时至关重要。



