Vision Transformer中的图像块嵌入详解:线性投影和二维卷积的数学原理与代码实现
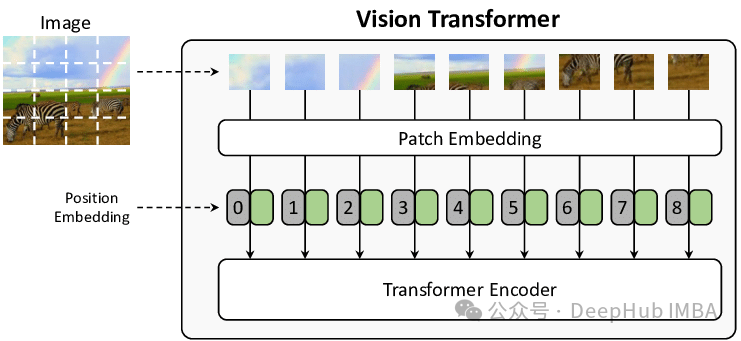
在 Vision Transformer 中,图像首先被分解为正方形图像块,然后将这些图像块展平为单个向量嵌入。这些嵌入可以被视为与文本嵌入(或任何其他嵌入)完全相同,甚至可以与其他数据类型进行连接。
在 Vision Transformer 中,图像首先被分解为正方形图像块,然后将这些图像块展平为单个向量嵌入。这些嵌入可以被视为与文本嵌入(或任何其他嵌入)完全相同,甚至可以与其他数据类型进行连接。



