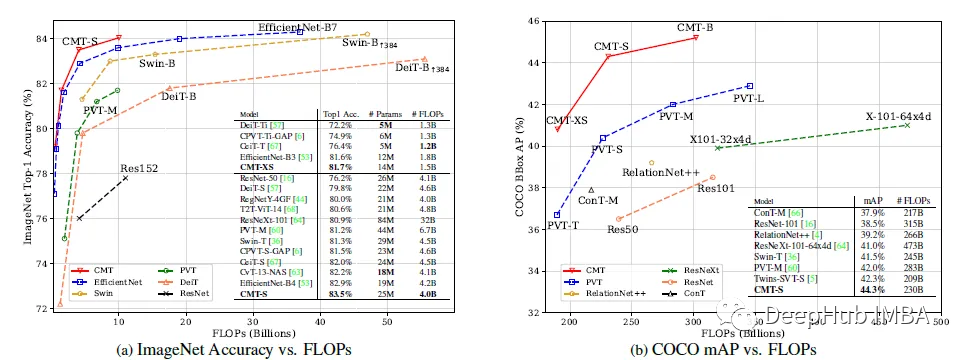
CMT:卷积与Transformers的高效结合
论文提出了一种基于卷积和VIT的混合网络,利用Transformers捕获远程依赖关系,利用cnn提取局部信息。构建了一系列模型cmt,它在准确性和效率方面有更好的权衡。

Transformers回顾 :从BERT到GPT4
在本文中,我们将研究革命性的Transformers架构以及它如何改变NLP,我们还将全面回顾从BERT到Alpaca的Transformers模型,重点介绍每种模型的主要特征及其潜在应用。

论文推荐:谷歌Masked Generative Transformers 以更高的效率实现文本到图像的 SOTA
在23年1月新发布的论文 Muse中:Masked Generative Transformers 生成文本到图像利用掩码图像建模方法来达到了最先进的性能,零样本 COCO 评估的 FID 分数为 7.88,CLIP 分数为 0.32——同时明显快于扩散或传统自回归模型。
Transformers 库的基本使用
本内容主要介绍 Transformers 库 的基本使用。
Transformers 库的基本使用
本内容主要介绍 Transformers 库 的基本使用。
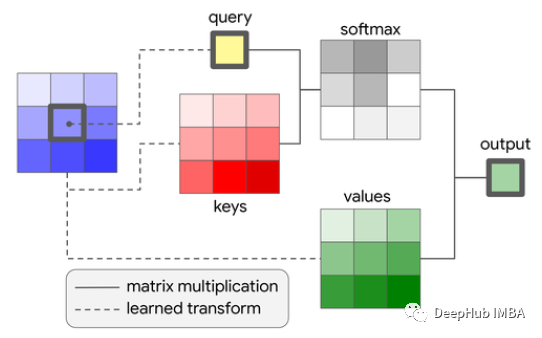
自注意力中的不同的掩码介绍以及他们是如何工作的?
注意力掩码本质上是一种阻止模型看我们不想让它看的信息的方法。这不是一种非常复杂的方法,但是它却非常有效。我希望这篇文章能让你更好地理解掩码在自注意力中的作用

如何估算transformer模型的显存大小
本文将详细介绍如何计算transformer的内存占用



