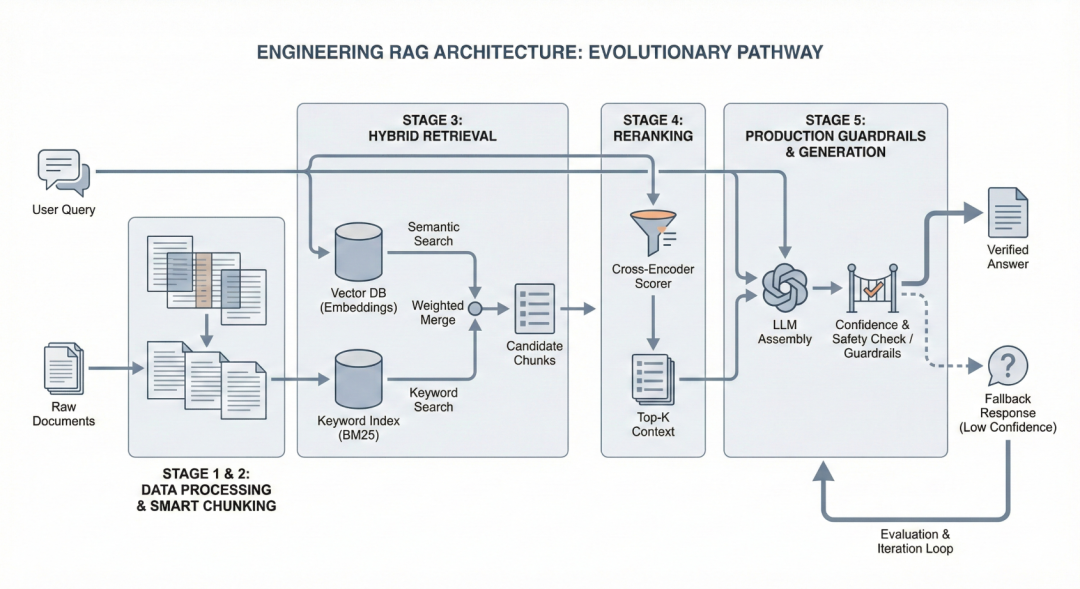
深入RAG架构:分块策略、混合检索与重排序的工程实现
从 Level 1 开始。记录并监控系统在哪翻车,搞清楚原因之后再往上走。 这才是构建一个真正能用的RAG系统的路径。

RAG 文本分块:七种主流策略的原理与适用场景
分块就是在生成 Embedding 之前,把大段文本拆成更小语义单元的过程。检索器真正搜索的对象而不是整篇文档就是这些分块。
知识图谱的可验证性:断言图谱的设计原理
本文会介绍自动化知识图谱生成的核心难题:生成式模型为什么搞不定结构化提取,判别式方案能提供什么样的替代选择,生产级知识图谱的质量标准又是什么。
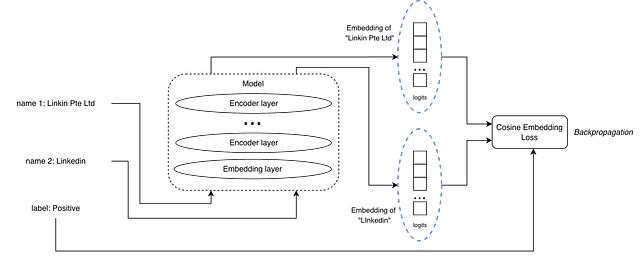
RAG 检索模型如何学习:三种损失函数的机制解析
本文将介绍我实验过的三种方法:Pairwise cosine embedding loss(成对余弦嵌入损失)、Triplet margin loss(三元组边距损失)、InfoNCE loss。
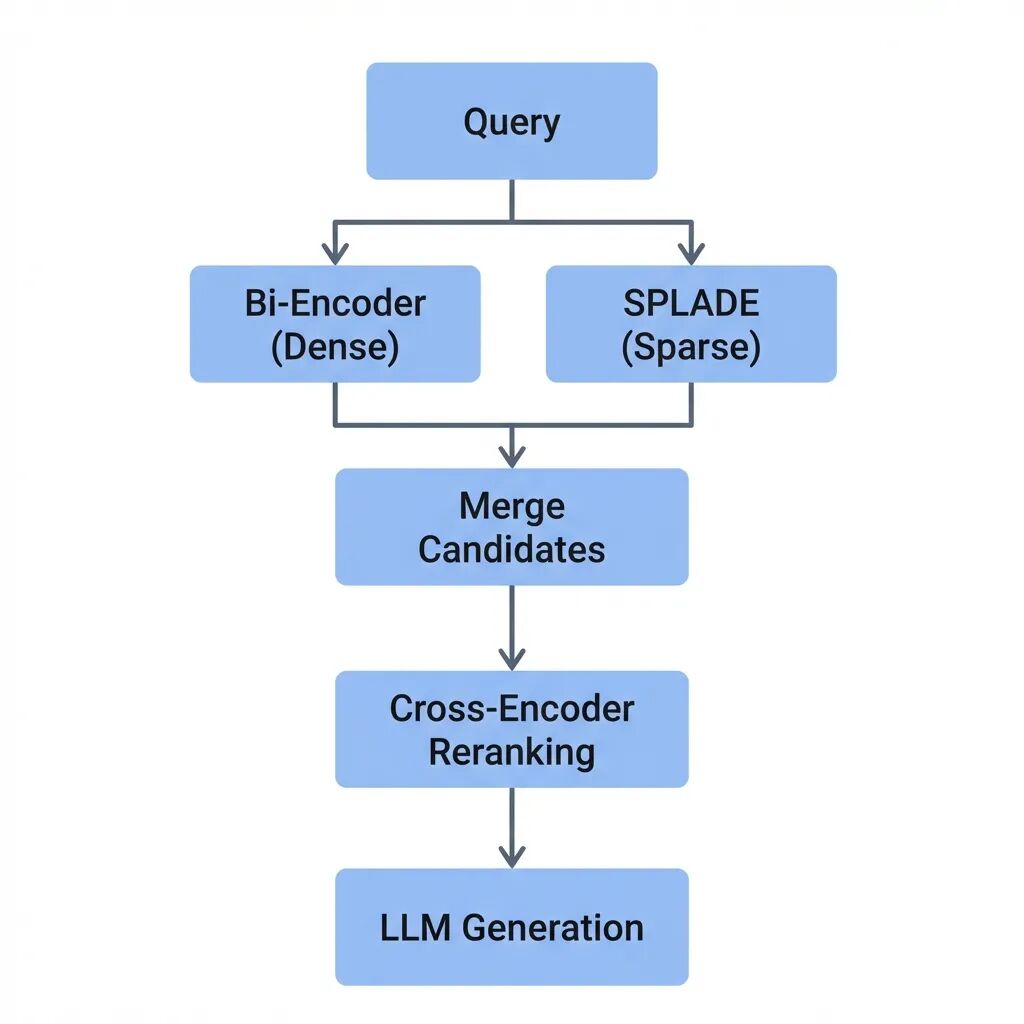
RAG检索模型选型:Bi-Encoder、Cross-Encoder、SPLADE与ColBERT的技术对比
本文将拆解每种模型的工作机制、适用边界,以及如何在实际系统中组合使用。而核心问题是:高召回和高精准之间的平衡该怎么把握。
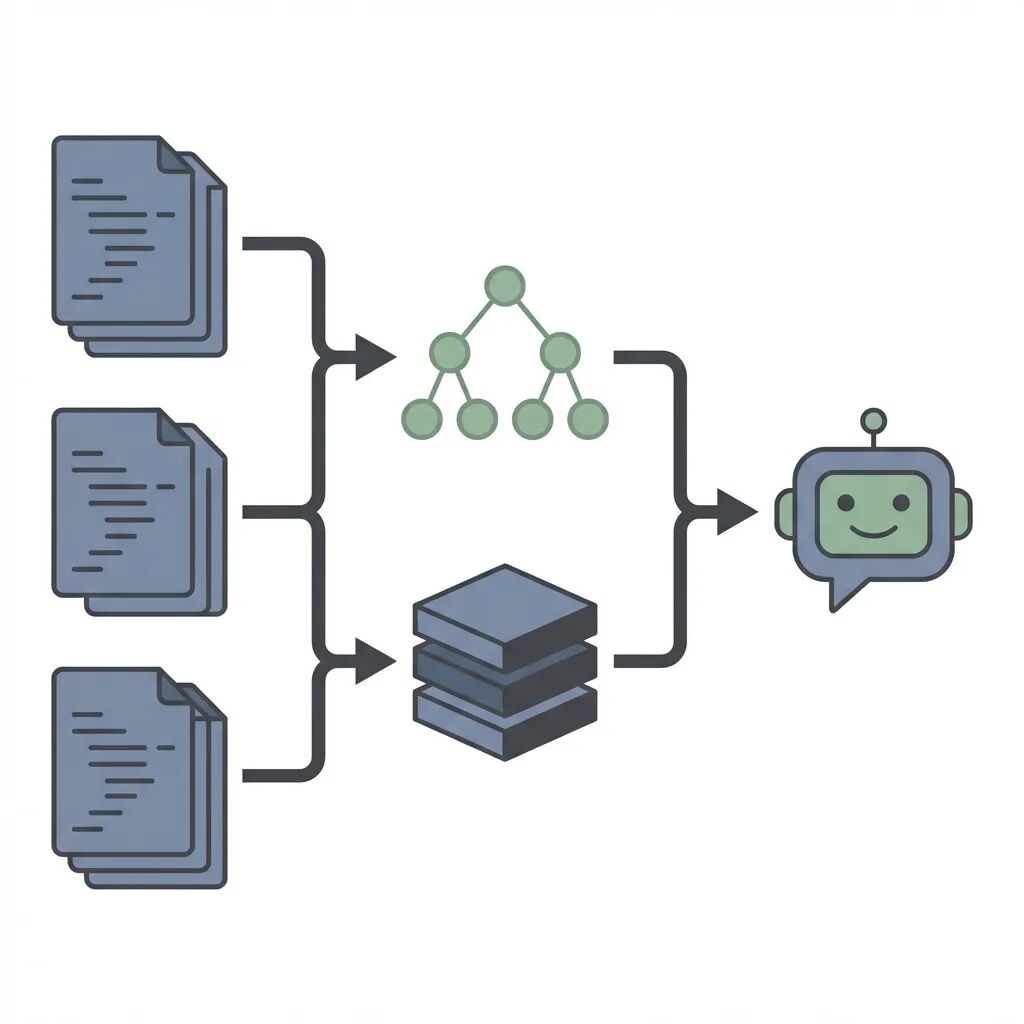
构建自己的AI编程助手:基于RAG的上下文感知实现方案
代码助手需要专门为代码设计的上下文感知的RAG(Retrieval-Augmented Generation)管道,这是因为代码跟普通文本不一样,结构严格,而且不能随便按字符随便进行分割。
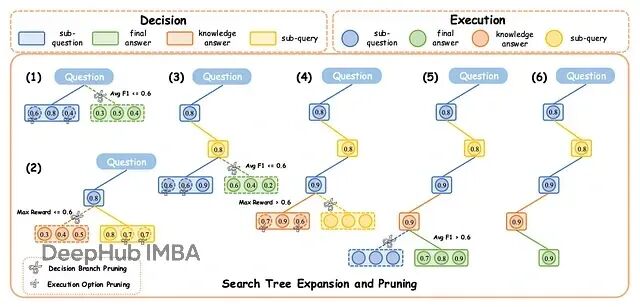
DecEx-RAG:过程监督+智能剪枝,让大模型检索推理快6倍
DecEx-RAG 把 RAG 建模成一个马尔可夫决策过程(MDP),分成决策和执行两个阶段。
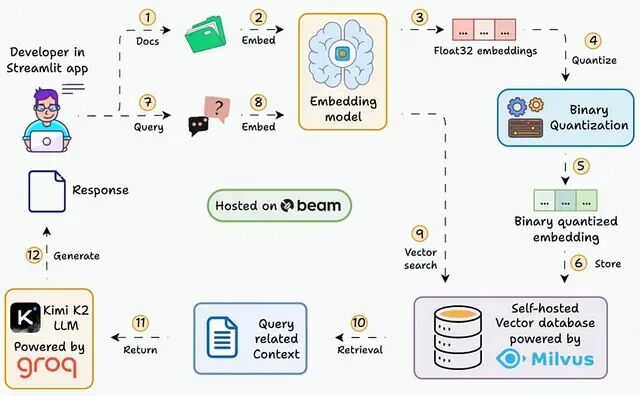
大规模向量检索优化:Binary Quantization 让 RAG 系统内存占用降低 32 倍
本文会逐步展示如何搭建一个能在 30ms 内查询 3600 万+向量的 RAG 系统,用的就是二值化 embedding。
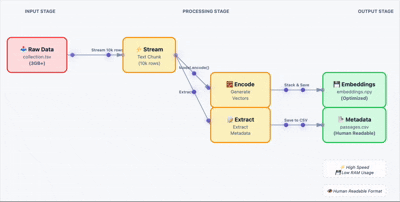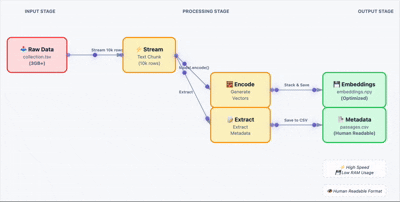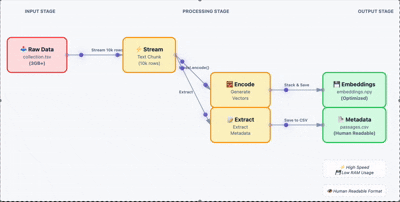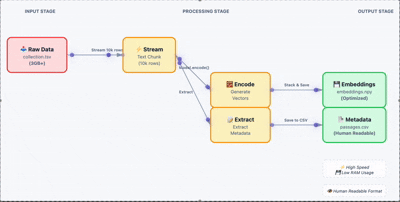
向量搜索升级指南:FAISS 到 Qdrant 迁移方案与代码实现
FAISS 在实验阶段确实好用,速度快、上手容易,notebook 里跑起来很顺手。但把它搬到生产环境还是有很多问题
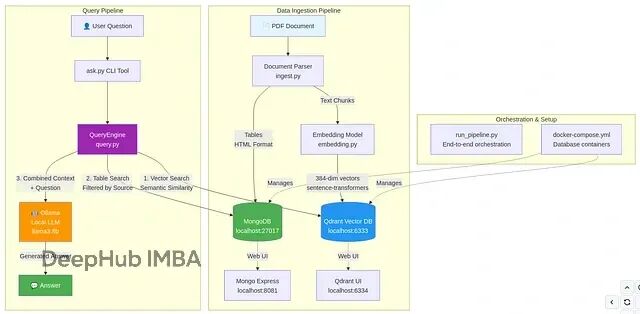
RAG系统的随机失败问题排查:LLM的非确定性与表格处理的工程实践
本文将介绍RAG在真实场景下为什么会崩,底层到底有什么坑,以及最后需要如何修改。
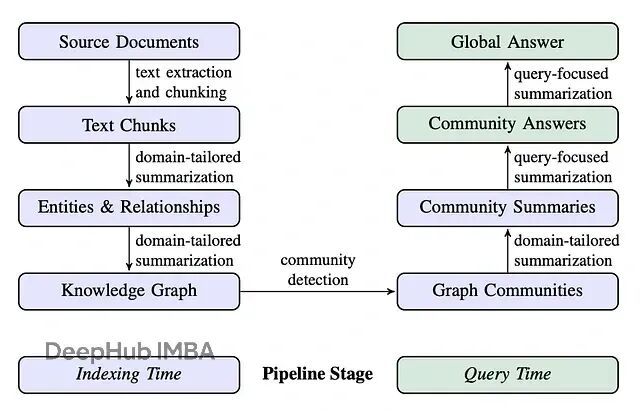
GraphRAG进阶:基于Neo4j与LlamaIndex的DRIFT搜索实现详解
本文的重点是DRIFT搜索:Dynamic Reasoning and Inference with Flexible Traversal,翻译过来就是"动态推理与灵活遍历"。这是一种相对较新的检索策略,兼具全局搜索和局部搜索的特点。
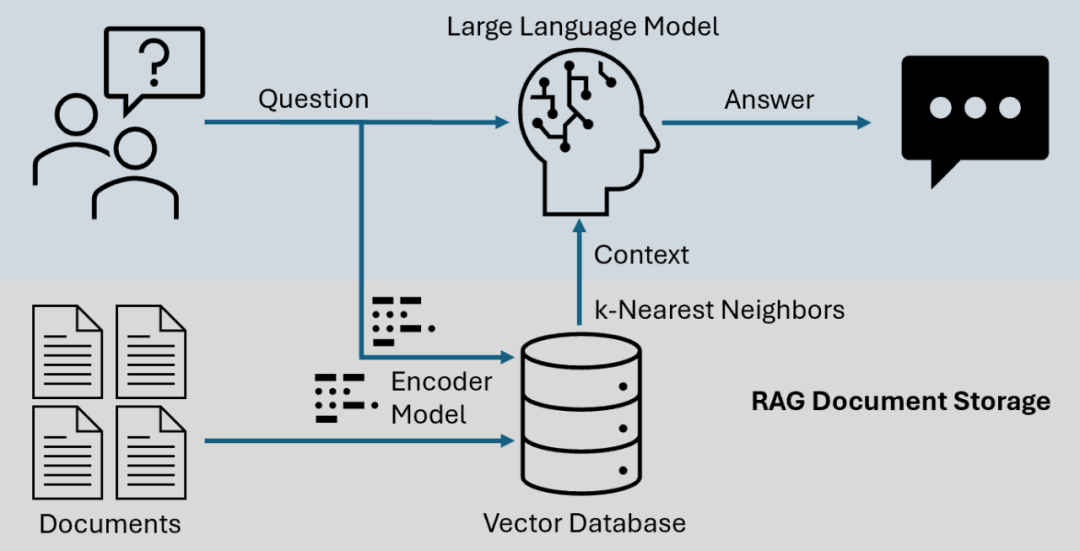
高级检索增强生成系统:LongRAG、Self-RAG 和 GraphRAG 的实现与选择
检索增强生成(RAG)早已不是简单的向量相似度匹配加 LLM 生成这一套路。LongRAG、Self-RAG 和 GraphRAG 代表了当下工程化的技术进展,它们各可以解决不同的实际问题。

LEANN:一个极简的本地向量数据库
LEANN嵌入式、轻量级的向量数据库
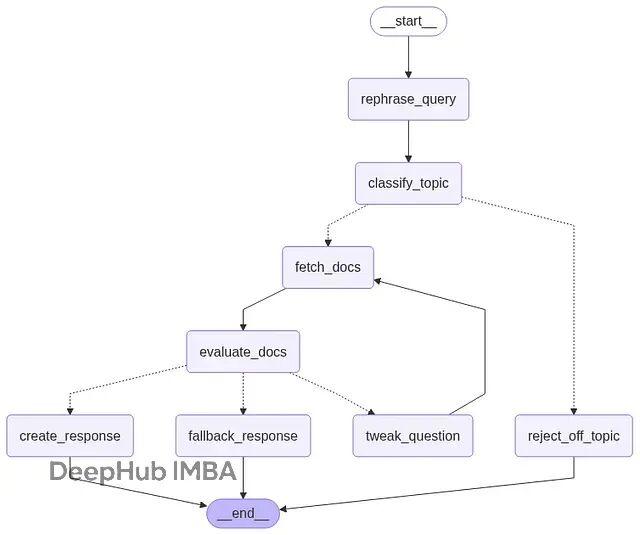
基于 LangGraph 的对话式 RAG 系统实现:多轮检索与自适应查询优化
这篇文章会展示怎么用 LangGraph 构建一个具备实用价值的 RAG 系统,包括能够处理后续追问、过滤无关请求、评估检索结果的质量,同时保持完整的对话记忆。
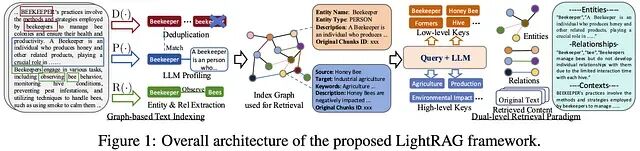
LightRAG 实战: 基于 Ollama 搭建带知识图谱的可控 RAG 系统
LightRAG 是一款开源、模块化的检索增强生成(RAG)框架,支持快速构建基于知识图谱与向量检索的混合搜索系统。它兼容多种LLM与嵌入模型,如Ollama、Gemini等,提供灵活配置和本地部署能力,助力高效、准确的问答系统开发。
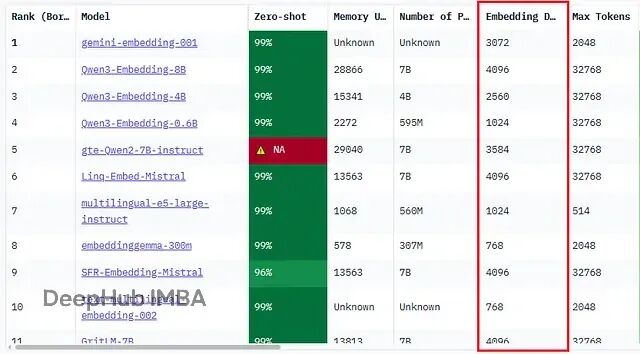
开源嵌入模型对比:让你的RAG检索又快又准
这篇文章会讲清楚嵌入是什么、怎么工作的,还有怎么挑选合适的模型。
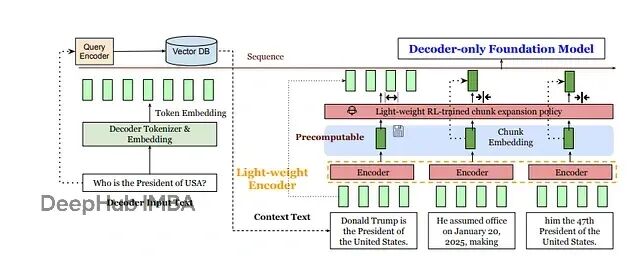
REFRAG技术详解:如何通过压缩让RAG处理速度提升30倍
meta提出了一个新的方案REFRAG:与其让LLM处理成千上万个token,不如先用轻量级编码器(比如RoBERTa)把每个固定大小的文本块压缩成单个向量,再投影到LLM的token嵌入空间。

RAG检索质量差?这5种分块策略帮你解决70%的问题
固定分块、递归分块、语义分块、结构化分块、延迟分块,每种方法在优化上下文理解和检索准确性上都有各自的价值。用对了方法,检索质量能提升一大截,幻觉问题也会少很多。
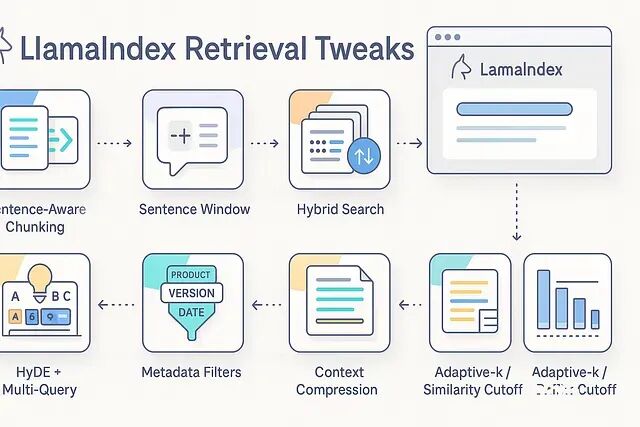
LlamaIndex检索调优实战:分块、HyDE、压缩等8个提效方法快速改善答案质量
分块策略、混合检索、重排序、HyDE、上下文压缩、元数据过滤、自适应k值——八个实用技巧快速改善检索质量
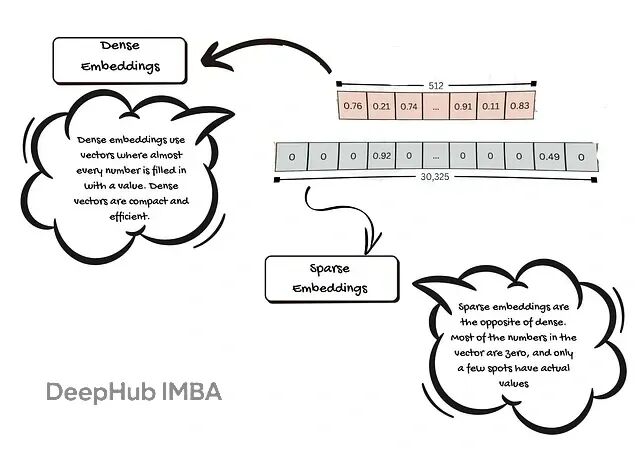
RAG系统嵌入模型怎么选?选型策略和踩坑指南
本文将说明嵌入的基本原理与重要性、列出选型时的关键考量,并对典型模型与适用场景给出实用建议,帮助你为 RAG 系统挑选既高效又稳健的嵌入方案。



