【爬虫实战】全过程详细讲解如何使用python获取抖音评论,包括二级评论
前两天,TaoTao发布了一篇关于“获取抖音评论”的文章。但是之前的那一篇包涵的代码呢仅仅只能获取一级评论。虽然说抖音的一级评论挺精彩的了,但是其实二级评论更加有意思,同时二级评论的数量是很多。所以二级评论是非常值得我们关注的。因此TaoTao花了一些时间写了一下这块的代码。接下来就让TaoTao带
【AI视野·今日NLP 自然语言处理论文速览 第七十五期】Thu, 11 Jan 2024
AI视野·今日CS.NLP 自然语言处理论文速览Thu, 11 Jan 2024Totally 36 papers👉上期速览✈更多精彩请移步主页Daily Computation and Language PapersLeveraging Print Debugging to Improve C
python中spacy和en_core_web_sm安装
注意:版本对应问题,如:我的spacy是3.6的,我下载的也是3.6.0版本的。3.到github上下载元模型,链接。1.用清华源安装spacy。注意换成自己的版本号。
Flowise+LocalAI部署--Agent应用
Flowise 是一个开源的用户界面可视化工具,它允许用户通过拖放的方式来构建自定义的大型语言模型(LLM)流程。Flowise基于LangChain.js,是一个非常先进的图形用户界面,用于开发基于LLM的应用程序。Flowise还支持Docker和NodeJS,可以在本地或者在容器中运行。如果有
【AI视野·今日NLP 自然语言处理论文速览 第七十一期】Fri, 5 Jan 2024
AI视野·今日CS.NLP 自然语言处理论文速览Fri, 5 Jan 2024Totally 28 papers👉上期速览✈更多精彩请移步主页Daily Computation and Language PapersLLaMA Pro: Progressive LLaMA with Block
智能时代:自然语言生成SQL与知识图谱问答实战
语义解析技术可以提高人机交互的效率和准确性,在自然语言处理、数据分析、智能客服、智能家居等领域都有广泛的应用前景。特别是在大数据时代,语义解析能够帮助企业更快速地从大量的数据中获取有用的信息,从而提高决策效率。
【码银送书第十一期】《自然语言生成SQL与知识图谱问答实战》
语义解析技术可以提高人机交互的效率和准确性,在自然语言处理、数据分析、智能客服、智能家居等领域都有广泛的应用前景。特别是在大数据时代,语义解析能够帮助企业更快速地从大量的数据中获取有用的信息,从而提高决策效率。
【AI视野·今日NLP 自然语言处理论文速览 第六十一期】Tue, 24 Oct 2023
AI视野·今日CS.NLP 自然语言处理论文速览Tue, 24 Oct 2023 (showing first 100 of 207 entries)Totally 100 papers👉上期速览✈更多精彩请移步主页Daily Computation and Language PapersLIN
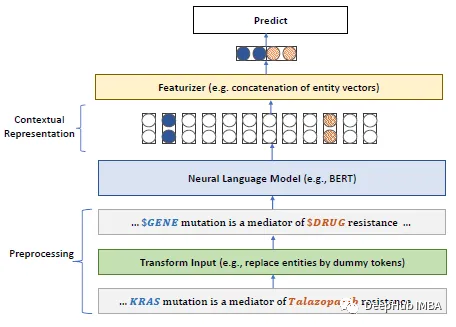
PubMedBERT:生物医学自然语言处理领域的特定预训练模型
语言模型并不一定就是最优的解决方案,“小”模型也有一定的用武之地
国产AI大模型:智谱清言 vs. 文心一言
智谱清言基于智谱AI自主研发的中英双语对话模型ChatGLM2,通过万亿字符的文本与代码预训练,结合有监督微调技术,以通用对话的产品形态成为更懂用户的智能助手,在工作、学习和日常生活中赋能用户,解答用户各类问题,满足用户问询需求。我们从结果观察和分析智谱清言与文心一言的不同之处。
SE-MoE:可拓展分布式MoE训练及推理框架(百度)
百度团队提出了一个新的混合专家(MoE)模型的训练和推理框架:SE-MoE。文章解决了MoE模型在计算、通信和存储方面的挑战和局限性。
【AI视野·今日NLP 自然语言处理论文速览 第三十六期】Tue, 19 Sep 2023
AI视野·今日CS.NLP 自然语言处理论文速览Tue, 19 Sep 2023 (showing first 100 of 106 entries)Totally 106 papers👉上期速览✈更多精彩请移步主页Daily Computation and Language PapersSpe
监督学习、半监督学习、无监督学习、自监督学习、强化学习和对比学习
监督学习、半监督学习、无监督学习、自监督学习、强化学习和对比学习
Text-to-SQL小白入门(三)IRNet:引入中间表示SemQL
本文主要介绍了IRNet论文的基本信息,比如标题、摘要、数据集、结果&结论,以及论文中提出的不匹配问题和词汇问题以及对应的解决方案,重点学习了中间表示SemQL。
【AI实战】训练一个自己的ChatGPT
使用 Alpaca-LoRA 来训练一个自己的 ChatGPT
安装spacy+zh_core_web_sm避坑指南
spacy是Python自然语言处理(NLP)软件包,可以对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化等。
CentOS 安装PaddlePaddle记录
在CentOS安装部署paddlepaddle 百度飞浆平台
大白话聊聊“深度学习”和“大模型”
非人工智能专业也能读得懂的大白话~
使用 T5 模型来做文本分类任务的一些总结
使用 T5 (Text-to-Text Transfer Transformer) 来做文本分类任务的一些总结
eNSP配置防火墙有两大步骤
ensp配置防火墙简单过程



