
深入理解三种PEFT方法:LoRA的低秩更新、QLoRA的4位量化与DoRA的幅度-方向分解
三种方法各有分工,互为补充,你唯一需要考虑的是哪种 PEFT 方案最贴合自己的硬件条件和精度要求。
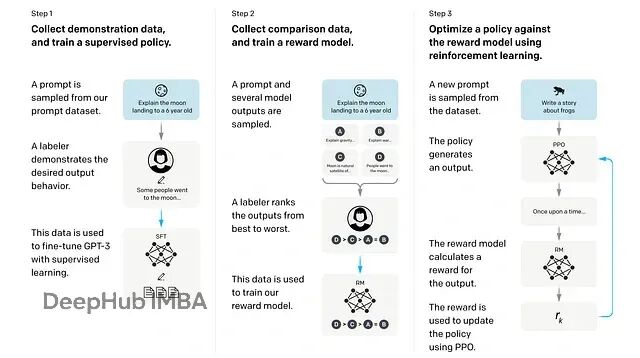
从零开始训练推理模型:GRPO+Unsloth改造Qwen实战指南
这篇文章会先介绍 GRPO的基本概念,然后我们会动手写代码训练一个推理 LLM,在实践中理解整个流程。
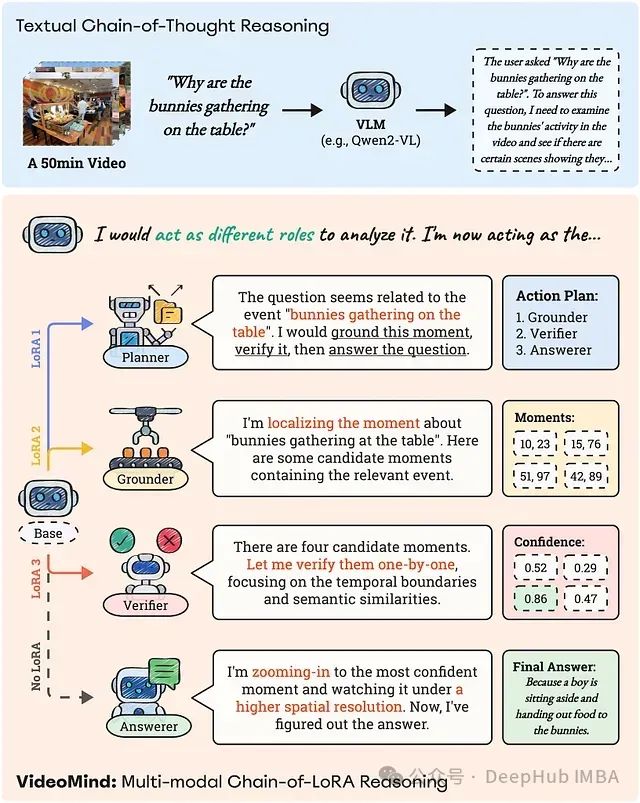
VideoMind:Chain-of-LoRA突破时间盲区让AI真正看懂长视频
**VideoMind** 是一种专为应对长视频中时间定位理解挑战而设计的新型视频语言代理。它不仅“观看”视频,还“分析”视频,采用一种结合了专门角色和名为 **Chain-of-LoRA** 的创新技术的策略。

使用vLLM在一个基座模型上部署多个lora适配器
在本文中,我们将看到如何将vLLM与多个LoRA适配器一起使用。我将解释如何将LoRA适配器与离线推理一起使用,以及如何为用户提供多个适配器以进行在线推理。
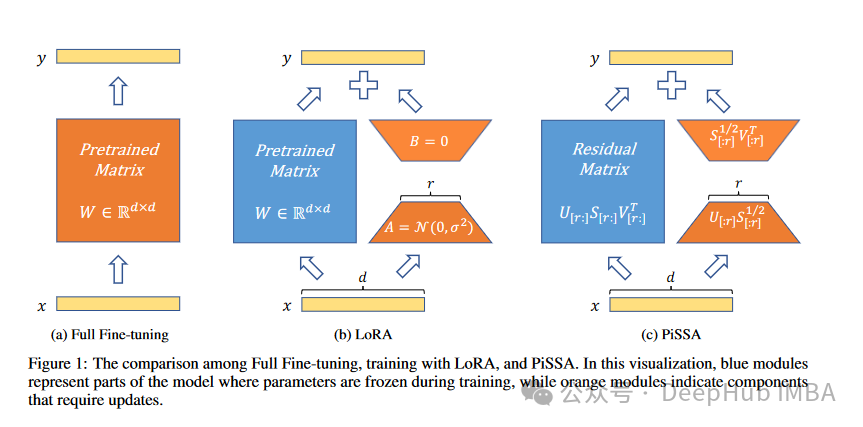
PiSSA :将模型原始权重进行奇异值分解的一种新的微调方法
我们开始看4月的新论文了,这是来自北京大学人工智能研究所、北京大学智能科学与技术学院的研究人员发布的Principal Singular Values and Singular Vectors Adaptation(PiSSA)方法。
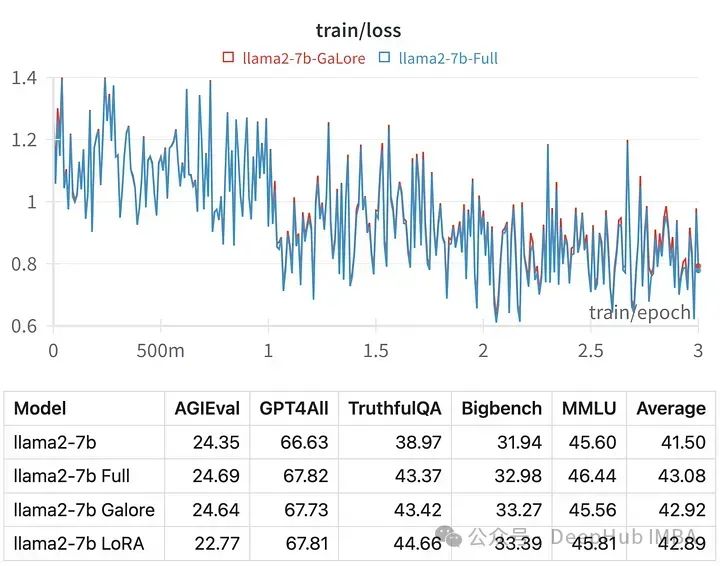
使用GaLore在本地GPU进行高效的LLM调优
,GaLore可以让我们在具有24 GB VRAM的消费级GPU上微调7B模型。结果模型的性能与全参数微调相当,并且似乎优于LoRA。
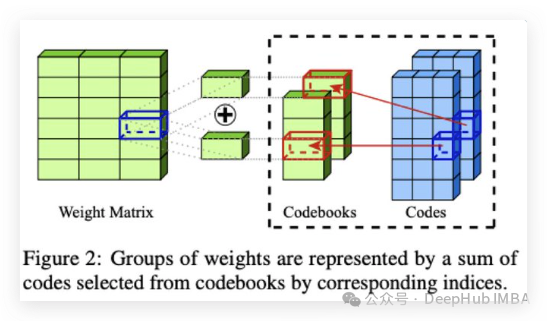
在16G的GPU上微调Mixtral-8x7B
在本文中,我将展示如何仅使用16 GB的GPU RAM对使用AQLM进行量化的Mixtral-8x7B进行微调。
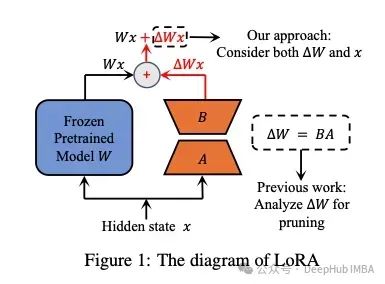
LoRA及其变体概述:LoRA, DoRA, AdaLoRA, Delta-LoRA
在本文中,我们将解释LoRA本身的基本概念,然后介绍一些以不同的方式改进LoRA的功能的变体,包括LoRA+、VeRA、LoRA- fa、LoRA-drop、AdaLoRA、DoRA和Delta-LoRA。
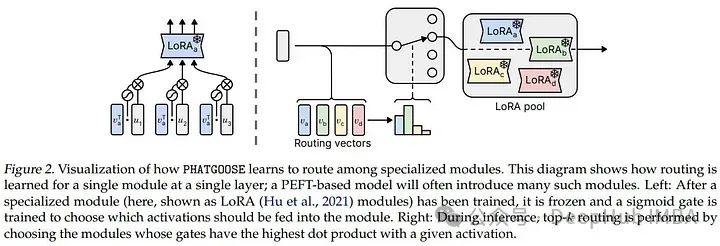
PHATGOOSE:使用LoRA Experts创建低成本混合专家模型实现零样本泛化
这篇2月的新论文介绍了Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE),这是一种通过利用一组专门的PEFT模块(如LoRA)实现零样本泛化的新方法
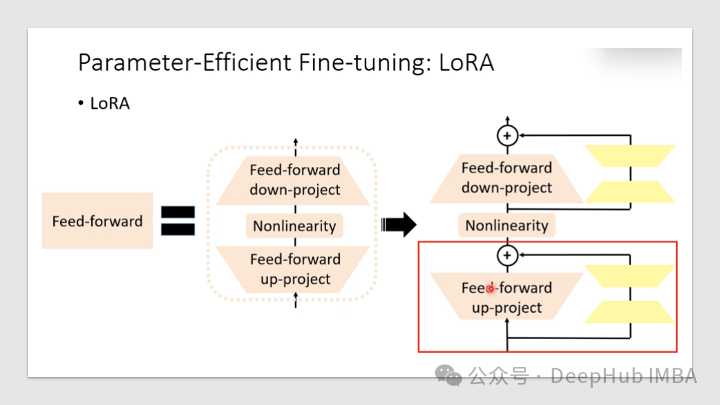
使用LORA微调RoBERTa
LORA可以大大减少了可训练参数的数量,节省了训练时间、存储和计算成本,并且可以与其他模型自适应技术(如前缀调优)一起使用,以进一步增强模型。
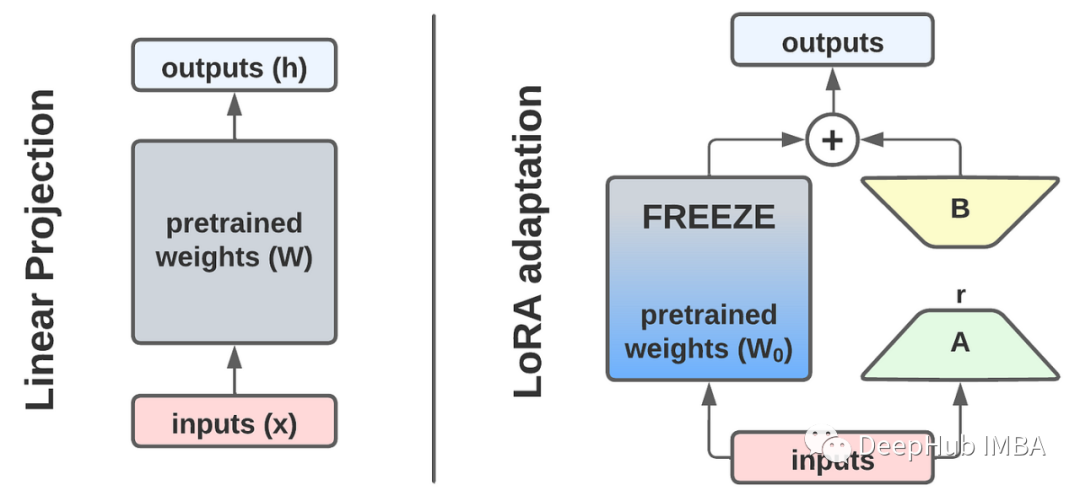
从头开始实现LoRA以及一些实用技巧
本文将首先深入研究LoRA,然后以RoBERTa模型例从头开发一个LoRA,然后使用GLUE和SQuAD基准测试对实现进行基准测试,并讨论一些技巧和改进。
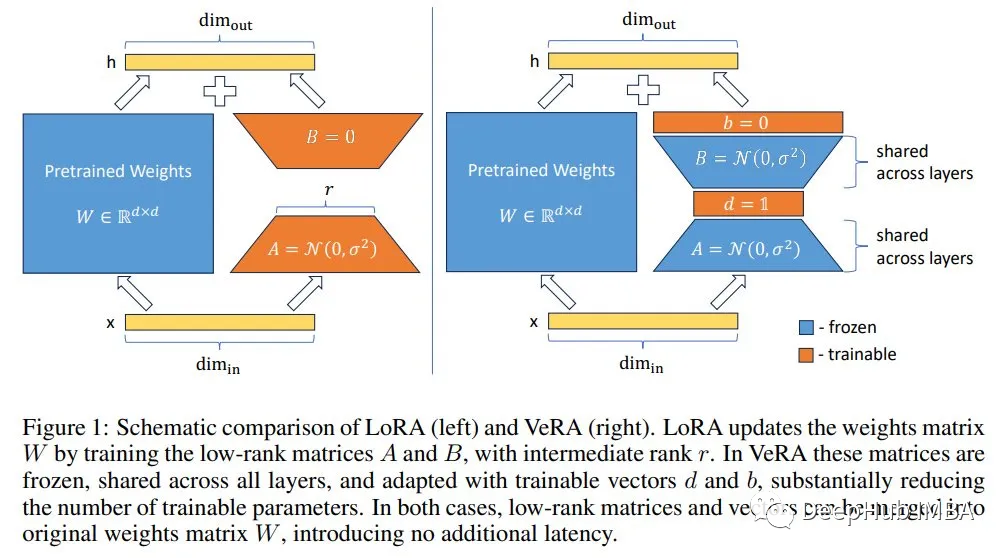
VeRA: 性能相当,但参数却比LoRA少10倍
VeRA在LoRA冻结的低秩张量上添加可训练向量,只训练添加的向量。论文中显示的大多数实验中,VeRA训练的参数比原始LoRA少10倍。
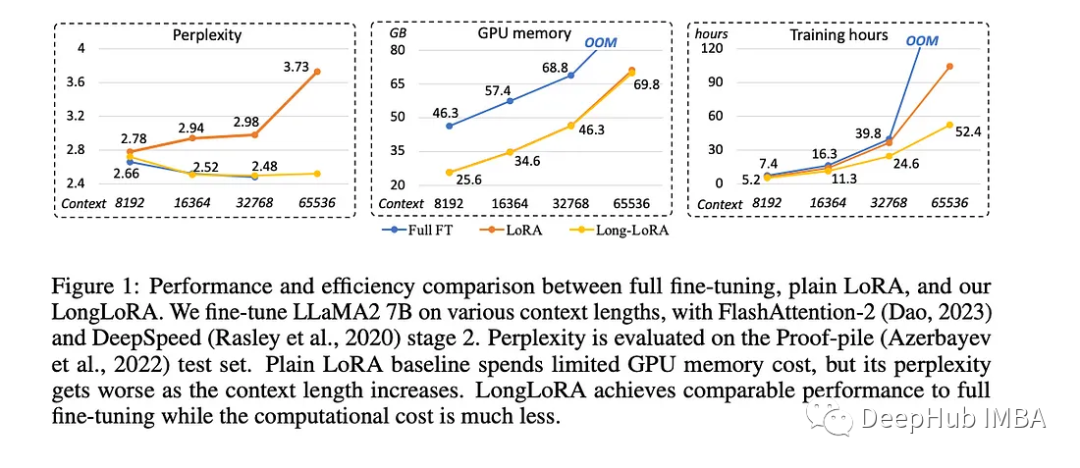
LongLoRA:不需要大量计算资源的情况下增强了预训练语言模型的上下文能力
麻省理工学院和香港中文大学推出了LongLoRA,这是一种革命性的微调方法,可以在不需要大量计算资源的情况下提高大量预训练语言模型的上下文能力。
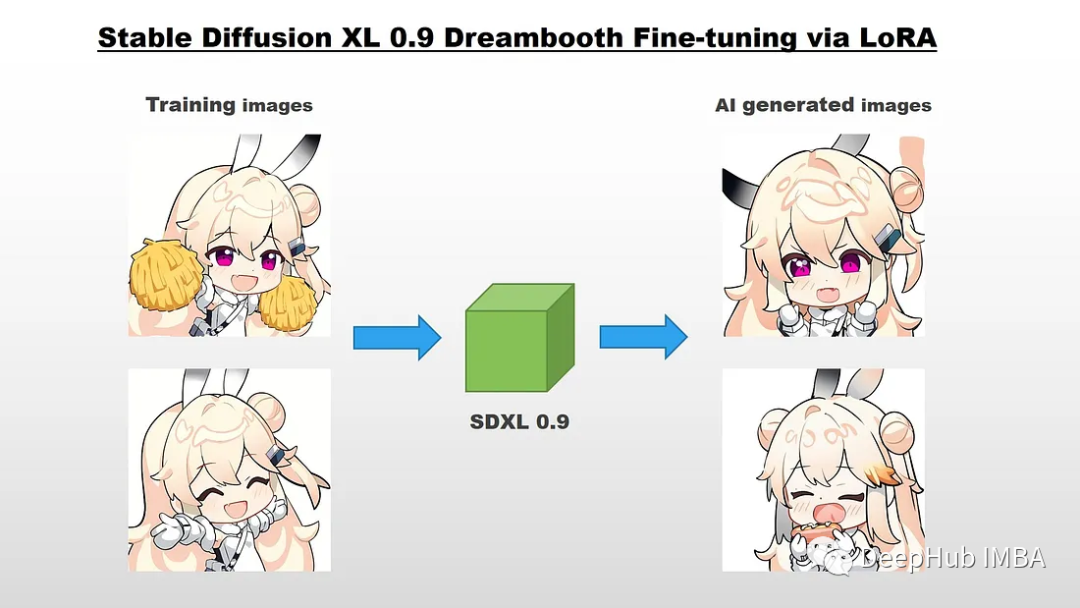
使用Dreambooth LoRA微调SDXL 0.9
本文将介绍如何通过LoRA对Stable Diffusion XL 0.9进行Dreambooth微调。DreamBooth是一种仅使用几张图像(大约3-5张)来个性化文本到图像模型的方法。
使用LoRA对大语言模型LLaMA做Fine-tune
目前有大量对LLM(大语言模型)做Fine-tune的方式,不过需要消耗的资源非常高,例如Stanford Alpaca: 对LLaMA-7B做Fine-tune,需要4颗A100 (80GB) GPUFastChat/Vicuna: 对LLaMA-7B做Fine-tune,需要4颗A100 (40
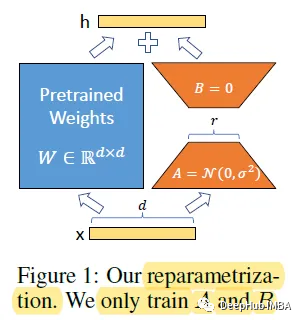
LoRA:大模型的低秩自适应微调模型
对于大型模型来说,重新训练所有模型参数的全微调变得不可行。Microsoft 提出了低秩自适应大大减少了下游任务的可训练参数数量。
分析解决【No module named ‘triton‘】的问题
A matching Triton is not available, some optimizations will not be enabled ???
详解LoRaWAN节点工作方式ClassA/C
在本篇文章中,将为和大家分享节点的三种工作方式中的ClassA和ClassC。本文来自微信公众号“小七说LoRa”,内容已获小七老师授权,小七老师是腾讯云在线课程讲师,点击链接https://mp.weixin.qq.com/s/dZmOD4yD5yKlYdsRCDSqAw可以观看课程视频。节点的工



