从DQN到Double DQN:分离动作选择与价值评估,解决强化学习中的Q值过估计问题
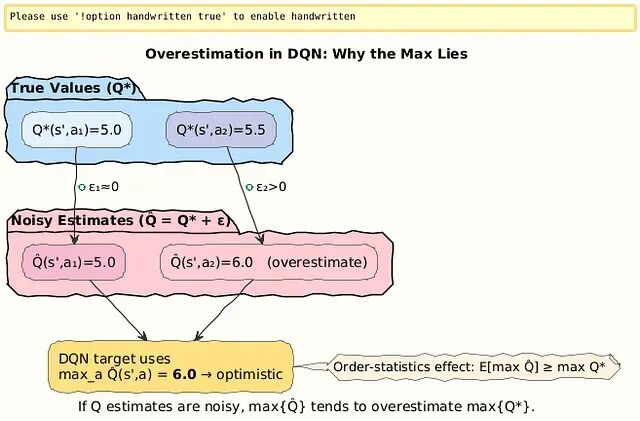
DQN的过估计源于max操作符偏好噪声中的高值。Double DQN把动作选择(在线网络θ)和价值评估(目标网络θ^−)分开处理,
开启深度强化学习之路:Deep Q-Networks简介和代码示例
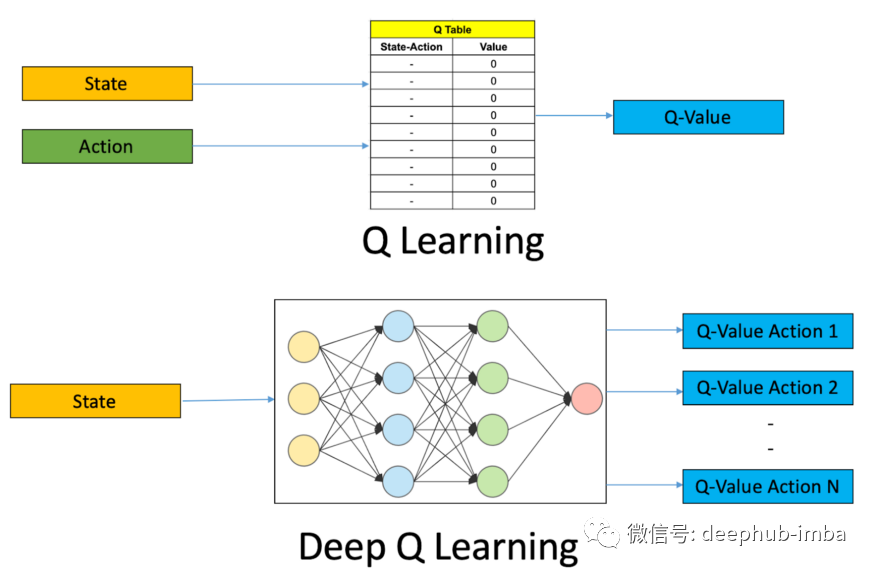
Deep Q-Learning 算法是深度强化学习的核心概念之一。神经网络将输入状态映射到(动作,Q 值)对。在本篇文章中将通过游戏的示例来介绍 Deep Q-Networks 的整个概念



