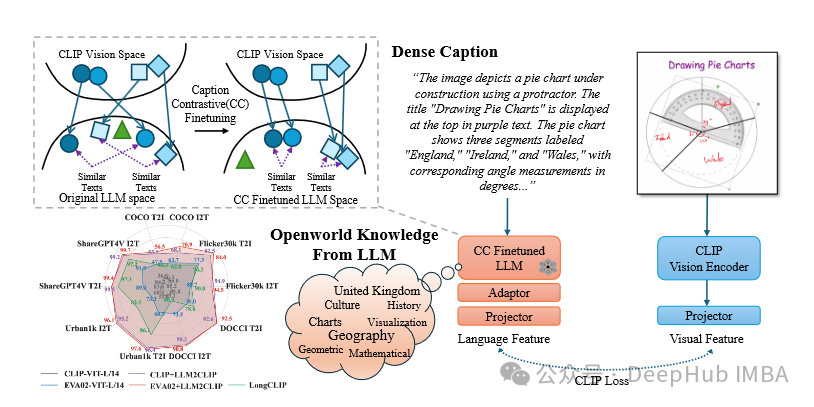
LLM2CLIP:使用大语言模型提升CLIP的文本处理,提高长文本理解和跨语言能力
LLM2CLIP 为多模态学习提供了一种新的范式,通过整合 LLM 的强大功能来增强 CLIP 模型。
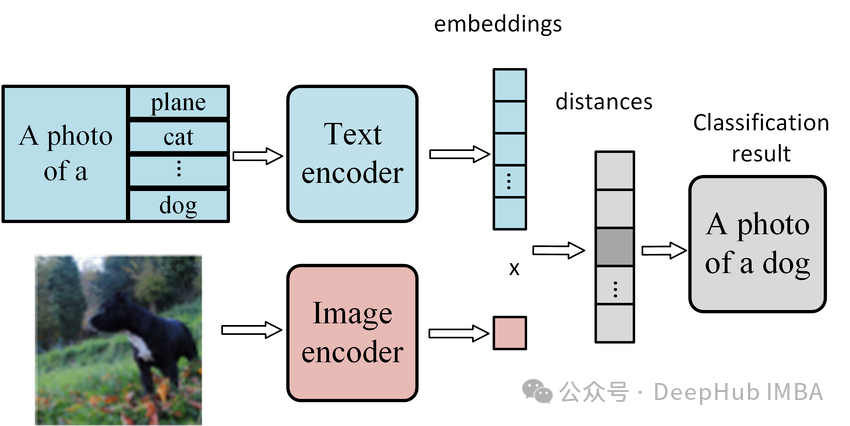
使用CLIP模型进行零样本图像分类的分步指南
我们首先介绍零样本学习的概念及其在现代AI应用中的重要性
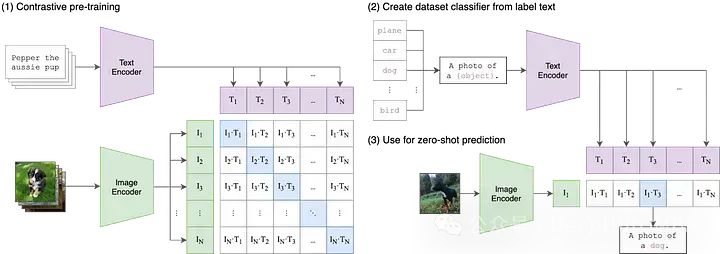
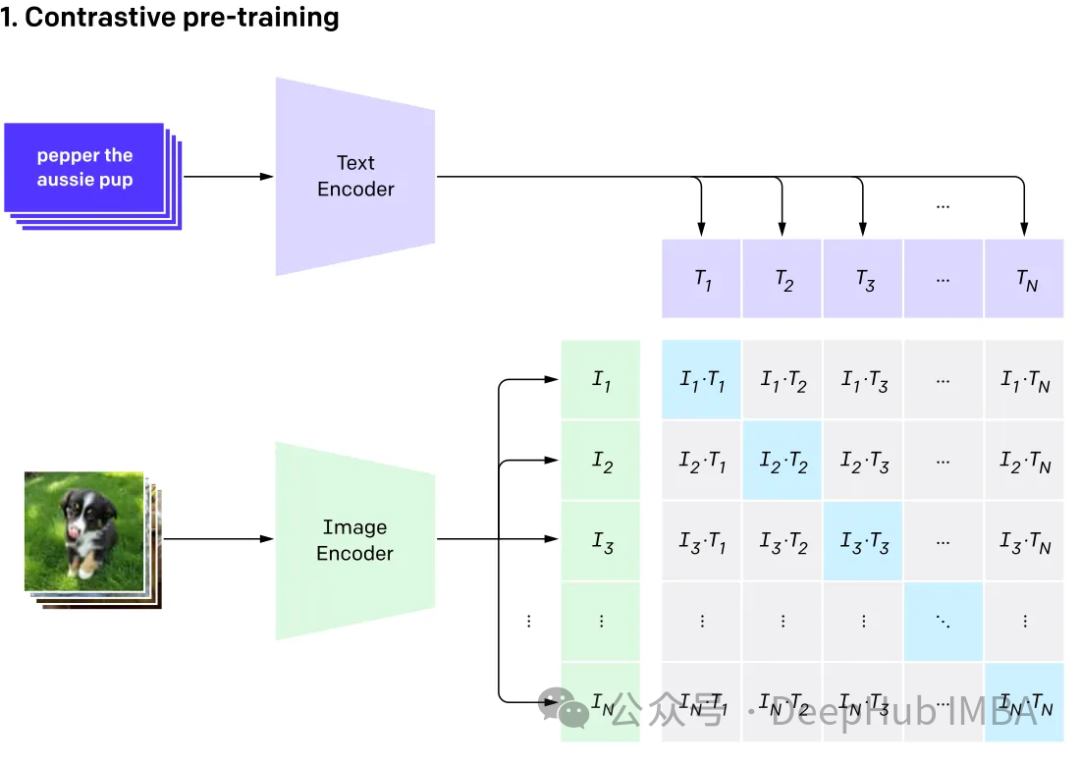
文生图的基石CLIP模型的发展综述
Open AI在2021年1月份发布的DALL-E和CLIP,这两个都属于结合图像和文本的多模态模型,其中DALL-E是基于文本来生成模型的模型,而CLIP是用文本作为监督信号来训练可迁移的视觉模型。
使用CLIP和LLM构建多模态RAG系统
在本文中我们将探讨使用开源大型语言多模态模型(Large Language Multi-Modal)构建检索增强生成(RAG)系统。本文的重点是在不依赖LangChain或LLlama index的情况下实现这一目标,这样可以避免更多的框架依赖。
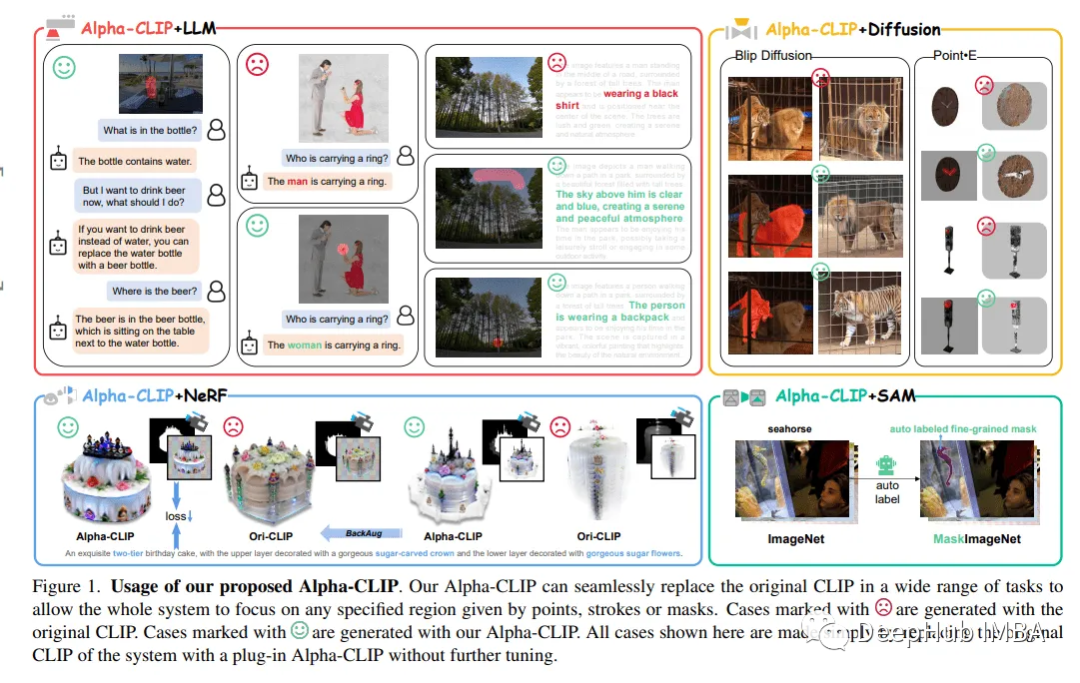
CLIP的升级版Alpha-CLIP:区域感知创新与精细控制
Alpha-CLIP不仅保留了CLIP的视觉识别能力,而且实现了对图像内容强调的精确控制,使其在各种下游任务中表现出色。
在自定义数据集上实现OpenAI CLIP
在本文中,我们将使用PyTorch中从头开始实现CLIP模型,以便我们对CLIP有一个更好的理解
首个大规模图文多模态数据集LAION-400M介绍
openAI的图文多模态模型CLIP证明了图文多模态在多个领域都具有着巨大潜力,随之而来掀起了一股图文对比学习的风潮。就在前几天(2022年12月),连Kaiming都入手这一领域,将MAE的思路与CLIP的思路结合,推出了FLIP,有兴趣可戳(https://arxiv.org/abs/2212.
使用CLIP构建视频搜索引擎
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。那么我们还能有什么改进呢?使用场景的时间戳来确定最佳场景。
文本生成图像工作简述--概念介绍和技术梳理
文本到图像的 AI 模型仅根据简单的文字输入就可以生成图像。用户可以输入他们喜欢的任何文字提示——比如,“一只可爱的柯基犬住在一个用寿司做的房子里”——然后,人工智能就像施了魔法一样,会产生相应的图像。



