
河北工业大学数据挖掘实验一 数据预处理
一、实验目的
(1)熟悉完全数据立方体构建、联机分析处理算法。
(2)浏览拟被处理的的数据,发现各维属性可能的噪声、缺失值、不一致性等,针对存在的问题拟出采用的数据清理、数据变换、数据集成的具体算法。
(3)编写程序,实现数据清理、数据变换、数据集成等功能。
(4)调试整个程序获得清洁的、一致的、集成的数据,选择适于全局优化的参数。
(5)写出实验报告。
二、实验原理
1、数据预处理
现实世界中的数据库极易受噪音数据、遗漏数据和不一致性数据的侵扰,为提高数据质量进而提高挖掘结果的质量,产生了大量数据预处理技术。数据预处理有多种方法:数据清理,数据集成,数据变换,数据归约等。这些数据处理技术在数据挖掘之前使用,大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间。
2、数据清理
数据清理例程通过填写遗漏的值,平滑噪音数据,识别、删除离群点,并解决不一致来“清理”数据。
3、数据集成
数据集成将数据由多个源合并成一致的数据存储,如数据仓库或数据立方体。
4、数据变换
通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。
5、数据归约
使用数据归约可以得到数据集的压缩表示,它小得多,但能产生同样(或几乎同样的)分析结果。常用的数据归约策略有数据聚集、维归约、数据压缩和数字归约等
三、实验内容和步骤
1、实验内容
1)用Python编程工具编写程序,实现数据清理、数据变换、数据集成等功能,并在实验报告中写出主要的预处理过程和采用的方法。
2)产生清洁的、一致的、集成的数据。 。
2、实验步骤
1)仔细研究和审查数据,找出应当包含在你分析中的属性或维,发现数据中的一些错误、不寻常的值、和某些事务记录中的不一致性。
2)进行数据清理,对遗漏值、噪音数据、不一致的数据进行处理。
例如:
1、日期中的缺失值可以根据统一的流水号来确定。
2、购买的数量不能为负值。
3)进行数据集成和数据变换和数据归约,将多个数据源中的数据集成起来,减少或避免结果数据中的数据冗余或不一致性。并将数据转换成适合挖掘的形式。
例如:
1、进行完数据清理后发现购买数量、销售价格、总额是相互关联的项可以去掉总额。
2、三个流水表日期的格式不一样应统一成相同的日期格式。
3、门号和 pos 机号码一样,可以去掉一个。
4、附加:同一购物篮的商品序号应该是顺序递增的。
3、程序框图
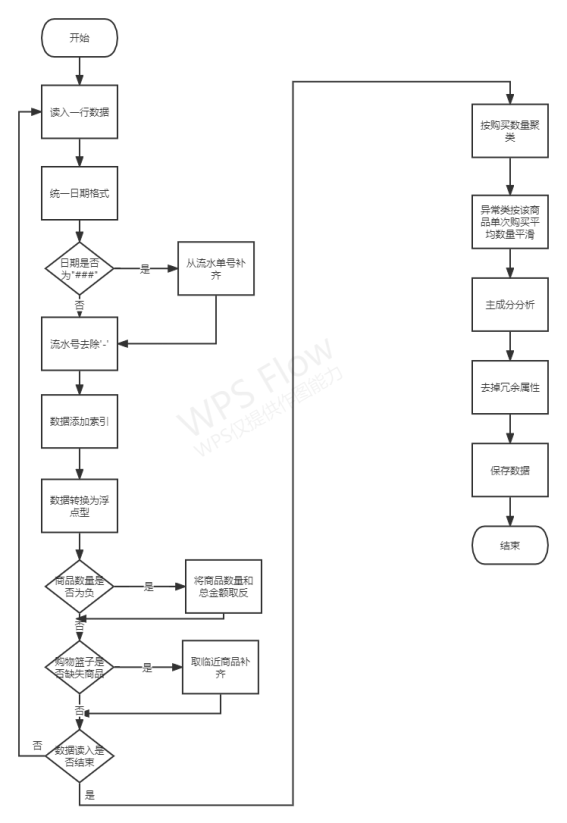
4、实验样本
1019.txt、1020.txt、1021.txt三个数据集
5、实验代码
#!/usr/bin/env python # -*- coding: utf-8 -*-## Copyright (C) 2021 ## @Time : 2022/5/30 21:27# @Author : Yang Haoyuan# @Email : [email protected]# @File : Exp1.py# @Software: PyCharmimport argparse
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler
parser = argparse.ArgumentParser(description='Exp1')
parser.add_argument('-files', nargs='+')
parser.set_defaults(augment=True)
args = parser.parse_args()print(args)# 从txt文件中读取数据,并做初步处理,数据以numpy array的格式返回defload_data():
files = args.files
data =[]
sales =[]
count =0for filename in files:withopen(filename,'r')as file_to_read:whileTrue:
lines = file_to_read.readline()# 整行读取数据ifnot lines:break
new_p_tmp =[]
p_tmp =[str(i)for i in lines.split(sep="\t")]# 将整行数据分割处理# p_tmp 为每一条记录的list,其中数据类型均为str
p_tmp[3]= p_tmp[3].replace('/','',2).replace('年','',1).replace('月','',1).replace('日','',1)# p_tmp[3]为日期,对于日期空缺,根据流水单号将其填补# 变换日期格式,为200304xx格式# 空缺日期从流水号中补齐if p_tmp[3]=="###":
p_tmp[3]= p_tmp[0][:8]else:
p_tmp[3]= p_tmp[3][0:4]+'0'+ p_tmp[3][4:len(p_tmp[3])]# 去除最后的换行符
p_tmp[len(p_tmp)-1]= p_tmp[len(p_tmp)-1].strip("\n")# 去掉'-',是其能够转化为浮点型参与分析运算# 为每一条记录加一个序号,与其索引一致,方便后期运算
p_tmp[0]= p_tmp[0].replace('-','')
p_tmp.insert(0, count)
p_tmp[0]= count
count = count +1# 将所有数据转换为浮点型,以便后期运算for i in p_tmp:
i =float(i)
new_p_tmp.append(i)# 将小于零的购买记录和总价转正if new_p_tmp[7]<0:
new_p_tmp[7]=-new_p_tmp[7]
new_p_tmp[9]=-new_p_tmp[9]# 向sales中添加数据
sales.append([new_p_tmp[0], new_p_tmp[6], new_p_tmp[7]])
data.append(new_p_tmp)# 添加新读取的数据# 首条数据商品序号为1iflen(data)==1:
data[0][5]=1# 流水号与之前的不同的商品序号为1if data[len(data)-1][1]!= data[len(data)-2][1]:
data[len(data)-1][5]=1# 每一个购物篮商品序号从1逐次递增if(data[len(data)-1][5]- data[len(data)-2][5])>1and(
data[len(data)-1][1]== data[len(data)-2][1]):
d = data[len(data)-1][5]
d = d -1
data[len(data)-1][5]= d
print(len(data))return np.array(data), np.array(sales)# 展示聚类后的情况defshow(label_pred, X, count):
x0 =[]
x1 =[]
x2 =[]
x3 =[]for i inrange(len(label_pred)):if label_pred[i]==0:
x0.append(X[i])if label_pred[i]==1:
x1.append(X[i])if label_pred[i]==2:
x2.append(X[i])if label_pred[i]==3:
x3.append(X[i])# print(count[0])
plt.scatter(np.ones((count[0],1)), np.array(x0), color='blue', label='label0')
plt.scatter(np.ones((count[1],1)), np.array(x1), color='red', label='label1')
plt.scatter(np.ones((count[2],1)), np.array(x2), color='yellow', label='label2')
plt.scatter(np.ones((count[3],1)), np.array(x3), color='black', label='label3')
plt.xlim(0,2)
plt.ylim(-100,1200)
plt.legend(loc=2)
plt.savefig("fig_1.png")
plt.clf()# 进行K-Means聚类,发现单次购买数量的异常点defK_Means(sale_data, data_raw, data):
sale_data.reshape(len(sale_data),-1)
estimator = KMeans(n_clusters=4)# 构造聚类器,聚4类
estimator.fit(sale_data)# 聚类
labels = estimator.labels_ # 获取聚类标签
sale_class =[[],[],[],[]]
count =[0,0,0,0]# 统计每一类的个数for i inrange(len(sales)):if labels[i]==0:
sale_class[0].append(sales[i])
count[0]= count[0]+1if labels[i]==1:
sale_class[1].append(sales[i])
count[1]= count[1]+1if labels[i]==2:
sale_class[2].append(sales[i])
count[2]= count[2]+1if labels[i]==3:
sale_class[3].append(sales[i])
count[3]= count[3]+1# 获取数量最少的两个类,视为异常类
count_np = np.array(count)
idx = np.argpartition(count_np,2)
count_index = idx[0]
count_index_2 = idx[1]# 每个异常类的数量变为该商品的平均销售数量for sale in sale_class[count_index]:filter= np.asarray([sale[1]])
_class = data_raw[np.in1d(data_raw[:,6],filter)]
data[int(sale[0])][7]= np.array(_class[:,7]).mean()# 总价相应变化
data[int(sale[0])][9]= data[int(sale[0])][7]* data[int(sale[0])][8]for sale in sale_class[count_index_2]:filter= np.asarray([sale[1]])
_class = data_raw[np.in1d(data_raw[:,6],filter)]
data[int(sale[0])][7]= np.array(_class[:,7]).mean()# 总价相应变化
data[int(sale[0])][9]= data[int(sale[0])][7]* data[int(sale[0])][8]# 展示聚类结果
show(labels, sale_data, count)# 更新的数据返回return data
# 主成分分析defPCA_(X):# 标准化
X_std = StandardScaler().fit(X).transform(X)# 构建协方差矩阵
cov_mat = np.cov(X_std.T)# 特征值和特征向量
eigen_vals, eigen_vecs = np.linalg.eig(cov_mat)# 求出特征值的和
tot =sum(eigen_vals)# 求出每个特征值占的比例
var_exp =[(i / tot)for i in eigen_vals]
cum_var_exp = np.cumsum(var_exp)# 绘图,展示各个属性贡献量
plt.bar(range(len(eigen_vals)), var_exp, width=1.0, bottom=0.0, alpha=0.5, label='individual explained variance')
plt.step(range(len(eigen_vals)), cum_var_exp, where='post', label='cumulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
plt.savefig("fig_2.png")# 返回贡献量最小的属性的索引return np.argmin(var_exp)if __name__ =="__main__":# 装载数据
data_raw, sales = load_data()print(data_raw.shape)# 对商品购买情况进行聚类,并消除异常何人噪声
data = K_Means(data_raw=data_raw, data=data_raw, sale_data=sales[:,2:])# 进行主成分分析
min_col_index = PCA_(data[:,2:])# 根据主成分分析结果去掉多于属性(门店号或者PSNO)# 去掉总价格这一冗余属性
data = np.hstack((data[:,1:min_col_index +1], data[:, min_col_index +2:9]))# 保存在CVS文件中
pd.DataFrame(data, columns=["SerNo","PSNo","Data","GoodNo","GoodID","Num","Price"]).to_csv("data.csv",index=False)
四、实验结果
针对购买数量进聚类分析结果示意图,由聚类结果推断,label1和label3为异常数据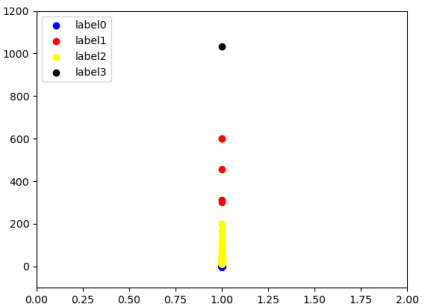
对从门店号开始到总额进行主成分分析结果示意图,由分析结果推断,属性1可能为冗余属性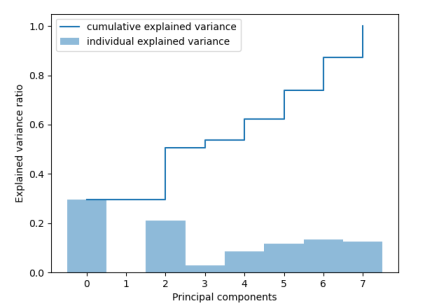
数据预处理后CSV文件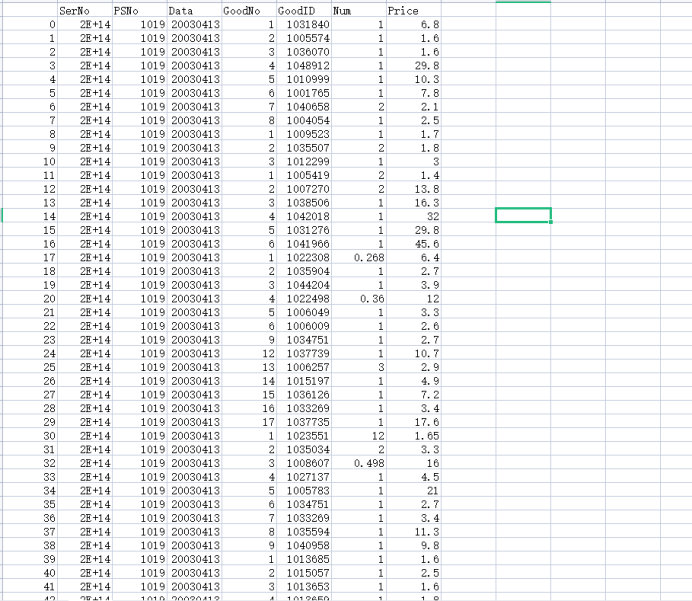
五、实验分析
本次实验主要针对给定的数据进行预处理。
实验遇到的第一问题就是数据类型与格式的不同,这需要解决数据类型与格式的不一致性,我将所有数据统一为数值浮点型,以便于后期进行各种分析运算,但实际上,一些数据转换为浮点型是十分有意义的,例如价格和数量,但有一些比如日期和流水号,作为标称属性,将其转换为数值属性并不合适。
对于数据中缺失的日期,可以从流水号中直接获取补全,但是对于购物篮中确实的记录,比如下图所示的5号商品,我们不能直接其他属性获取信息。
一种较为可信的方法是统计该门店该日期销售最多的商品,然后将此商品作为购买记录填入。但是对于27k条数据来说,计算量显得过于巨大,所以我简单地采用了相邻商品的记录直接进行补充。
数据中有一些很明显的异常和噪声,比如购买量和总价格为负数,在读取数据的时候可以直接进行处理。针对另一些异常值,我采用K-Means聚类方法进行发现。通过对超参的调节,在聚成4类的时候,有两类的数量过少,可以被视为异常类。
对于这些异常的数据,我将其购买数量设定为该种商品的平均购买量进行平滑。
针对数据中的冗余属性,我首先尝试采用主成分分析方法(PCA)进行分析,试图找出那些贡献较小的属性。我在从门店号到总价的维度构架协方差矩阵并且计算各属性的特征值占比。结果显示”PSNO”属性的“贡献量”接近0,为冗余属性,所以可以进行规约。但是另一个冗余属性“总价”,却仍然具有相当的占比。
对此,我的分析是,PCA方法分析的是对于一个数据对象,有哪些属性是主属性,也就是对数据对象的描述贡献最大的属性。在这里,每一条记录中,总价对其仍然具有一定的描述性。
版权归原作者 Ace2NoU 所有, 如有侵权,请联系我们删除。