
Adam(W)目前为训练LLM的主流优化器,但其内存开销较大,这是因为Adam优化器需要存储一阶动量m和二阶动量v,总内存占用至少是模型大小的两倍,这对现有的高端显卡也是一种负担。论文提出一种新的优化器Adam-mini,在不牺牲性能的情况下减少Adam优化器的内存占用。
Adam-mini
Adam-mini通过减少学习率资源来降低内存占用的具体方法如下:
- 参数分块:Adam-mini首先将模型参数按照Hessian矩阵的结构划分为多个块。Hessian矩阵通常具有近似块对角结构,每个块代表一组参数。论文提出的分块策略基于Hessian结构,将每个块内的参数视为一个整体进行处理。
- 块内平均学习率:对于每个参数块,Adam-mini不再为每个参数单独分配学习率,而是为整个块分配一个平均的学习率。具体方法是计算块内所有参数的梯度平方的平均值,然后基于这个平均值来计算该块的学习率。这一过程显著减少了所需的学习率数量。
- 内存节省:由于Adam-mini使用的学习率数量大大减少,所需的二阶动量(即Adam中的v参数)的存储也相应减少。论文中的实验表明,这种方法可以减少45%到50%的内存占用。
- 具体算法:- 在初始化时,将模型参数分块。- 对于每个参数块,计算块内梯度平方的平均值,并更新块的学习率。- 使用更新后的学习率进行参数更新。
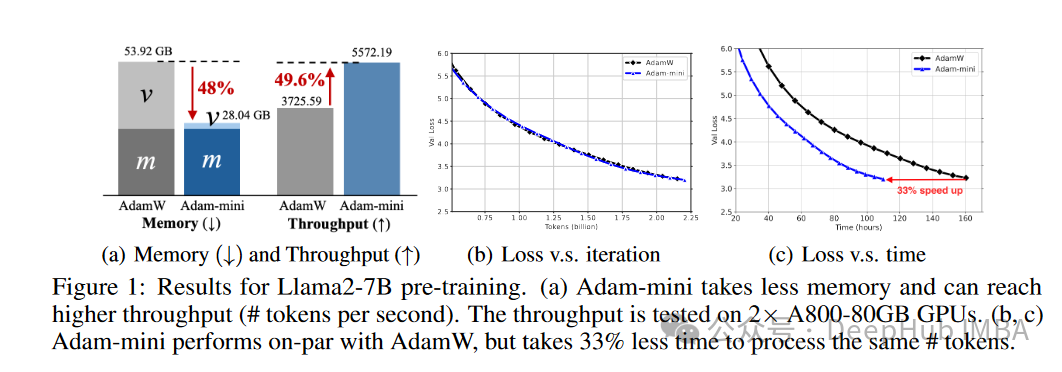
这种方法不仅减少了内存占用,还通过减少GPU和CPU之间的通信开销,提高了训练效率。例如,在Llama2-7B模型的预训练中,Adam-mini在两块A800-80GB GPU上实现了比AdamW高49.6%的吞吐量,并节省了33%的训练时间。

算法示例
# Adam-mini 的伪代码
defadam_mini(params, grads, lr, beta1, beta2, epsilon, weight_decay):
# 初始化动量和二阶动量
m= {}
v= {}
forparaminparams:
m[param] =np.zeros_like(param)
v[param] =np.zeros_like(param)
# 参数分块
param_blocks=partition_parameters(params)
forblockinparam_blocks:
# 获取当前块的梯度
grad_block= [grads[param] forparaminblock]
# 更新动量
m_block= (1-beta1) *grad_block+beta1*m_block
m_block_hat=m_block/ (1-beta1**t)
# 更新二阶动量(平均值)
v_block= (1-beta2) *np.mean([g**2forgingrad_block]) +beta2*v_block
v_block_hat=v_block/ (1-beta2**t)
# 更新参数
forparaminblock:
param_update=lr*m_block_hat/ (np.sqrt(v_block_hat) +epsilon)
params[param] -=param_update+weight_decay*params[param]
returnparams
通过这种方法,Adam-mini成功地减少了学习率资源的使用,从而大幅降低了内存占用,并在多种任务中表现出色。
性能表现
1、内存和吞吐量性能
Adam-mini在预训练Llama2-7B模型时的性能:
- 内存占用:Adam-mini显著降低了内存占用。例如,在Llama2-7B预训练时,Adam-mini减少了45%到50%的内存消耗。
- 吞吐量:由于内存减少,Adam-mini能够支持更大的每GPU批次大小,从而提高了吞吐量。在两块A800-80GB GPU上,Adam-mini实现了比AdamW高49.6%的吞吐量,节省了33%的训练时间。
2、预训练性能
- TinyLlama-1B:图7(a)显示了TinyLlama-1B的验证损失曲线。Adam-mini的表现与AdamW相当,但内存占用更低。
- GPT2系列:图8展示了GPT2不同规模模型的训练曲线,包括GPT2-125M、GPT2-330M、GPT2-770M和GPT2-1.5B。Adam-mini在所有这些模型上的表现均与AdamW相当,而Adafactor、CAME等方法在这些任务中的表现较差。
通过这些实验结果,论文证明了Adam-mini不仅在内存占用和计算效率上优于传统的AdamW,还能在不同任务中保持或提升模型性能。这些结果表明,Adam-mini是一个有效且高效的优化器,适用于大规模模型的训练和微调。
非LLM任务的表现
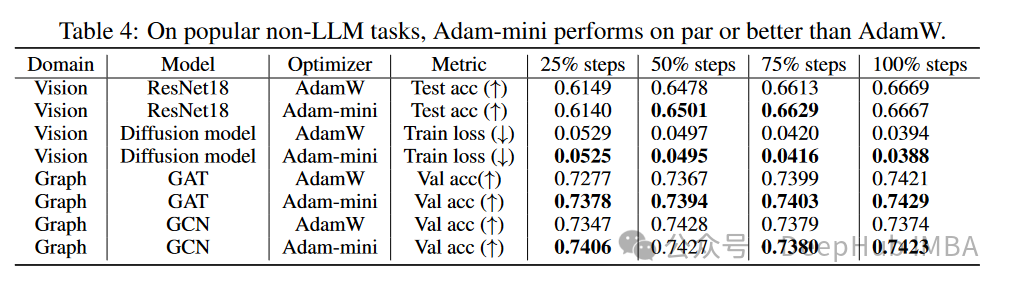
Adam-mini在多种非LLM任务中均表现出色,能够在减少内存占用的同时,保持或提升模型性能。这些结果证明了Adam-mini在图像识别、扩散模型训练和图卷积网络等任务中的广泛适用性和有效性。
图像分类:在ImageNet上训练ResNet18,Adam-mini的测试精度与AdamW相当。
扩散模型训练:在CelebA数据集上训练扩散模型,Adam-mini的训练损失低于AdamW。
图神经网络:在OGB-arxiv数据集上训练Graph Convolution Network (GCN)和Graph Attention Network (GAT),Adam-mini的验证精度优于或相当于AdamW。
总结
Adam-mini基于Hessian矩阵的结构,将模型参数划分为多个块,每个块使用单一的平均学习率,从而大幅减少了需要存储的学习率数量。在非LLM任务中的实验结果进一步验证了Adam-mini的广泛适用性。Adam-mini不仅在内存占用和计算效率方面具有优势,还能在多种任务中保持或提升模型性能,是一个有效且高效的优化器。