
目录
下载kaggle数据集
kaggle猫狗识别数据集共包含25000张JPEG数据集照片,其中猫和狗的照片各占12500张。数据集大小经过压缩打包后占543MB。
数据集可以从kaggle官方网站下载,链接如下:
https://www.kaggle.com/c/dogs-vs-cats/data
如果嫌官网下载麻烦,也可以从博主之前分享的百度网盘链接中直接获取:
网盘分享—博客链接,点击>>>
在下载的kaggle数据集基础上,创建一个新的小数据集,其中包含三个子集。
猫和狗的数据集:各 1000 个样本的训练集、各 500 个样本的验证集、各 500 个样本的测试集。
创建新的小数据集
下面的网络所使用的数据集不是从kaggle网站中直接下载下来的完整数据集,而是基于kaggle完整数据集的部分小数据集。
import os, shutil
# 下载的kaggle数据集路径
original_dataset_dir = '/Users/Downloads/kaggle_original_data'
# 新的小数据集放置路径
base_dir = '/Users/cats_and_dogs_small'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))
以上程序会生成各个文件夹路径,并将对应的训练集、验证集、测试集复制进去生成新的小数据集。
以上程序输出结果如下:
total training cat images: 1000
total training dog images: 1000
total validation cat images: 500
total validation dog images: 500
total test cat images: 500
total test dog images: 500
构建猫狗分类的小型卷积神经网络
猫狗分类的网络架构
# 网络架构
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())
输出的特征图的维度随层变化的情况如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense (Dense) (None, 512) 3211776
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
模型的配置
from tensorflow.keras import optimizers
model.compile(loss=‘binary_crossentropy’,
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=[‘acc’])
图像的预处理
# 图像预处理
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
# 此处改成自己的路径
train_dir='D:\\0 keras shujuji\\kaggle\\modle_date\\train'
validation_dir='D:\\0 keras shujuji\\kaggle\\modle_date\\validation'
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
利用批量生成器拟合模型
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
##保存模型
model.save('cats_and_dogs_small_1.h5')
绘制精度和损失
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果显示
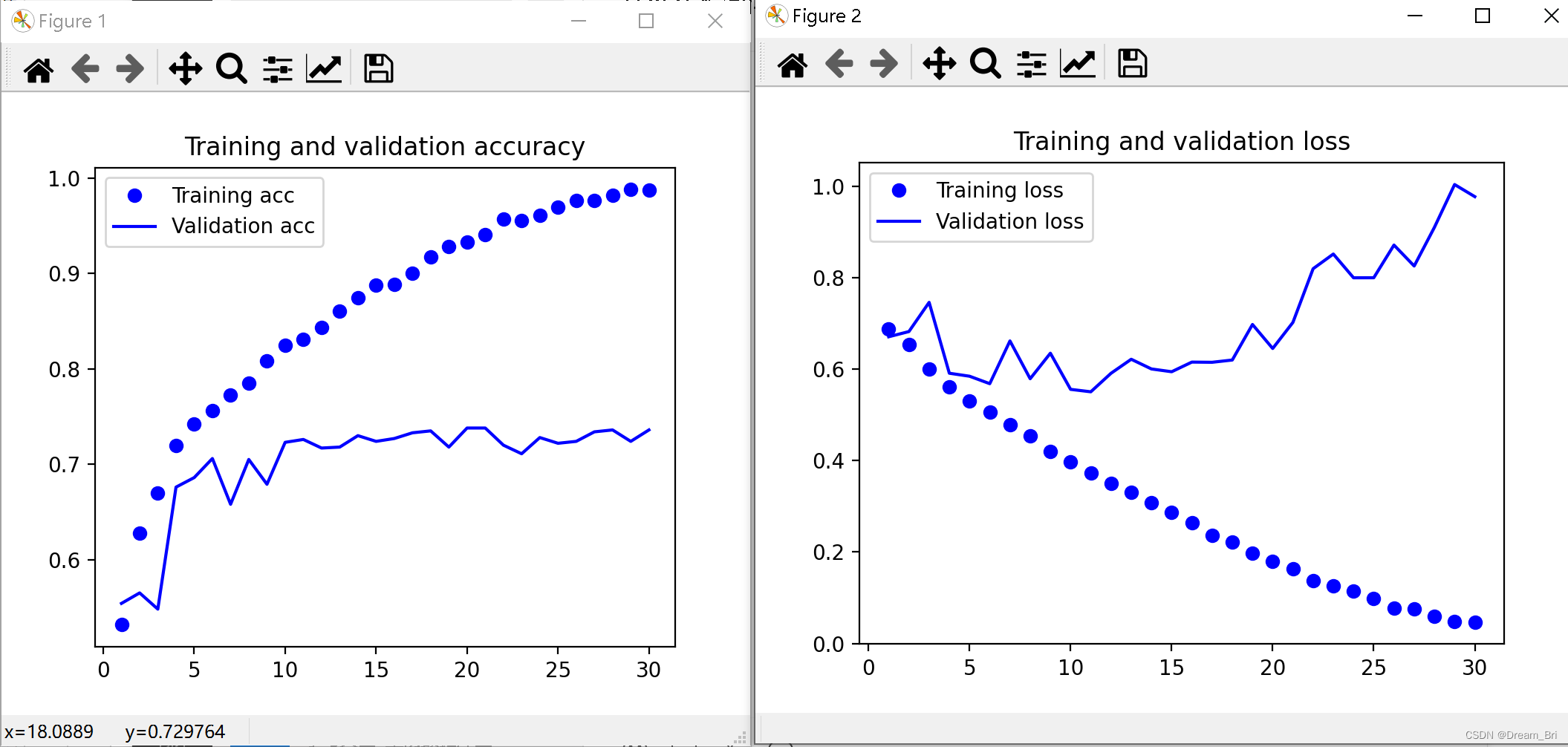
把本节(构建猫狗分类的小型卷积神经网络)各个子程序结合在一起就可以显示结果了,需要修改 模型的预处理 一节中的数据集放置路径
随机增强后的训练图像显示
from keras.preprocessing import image
import os
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 自己的train_cats_dir数据集路径
train_cats_dir='D:\\modle_date\\train\\cats'
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
结果显示
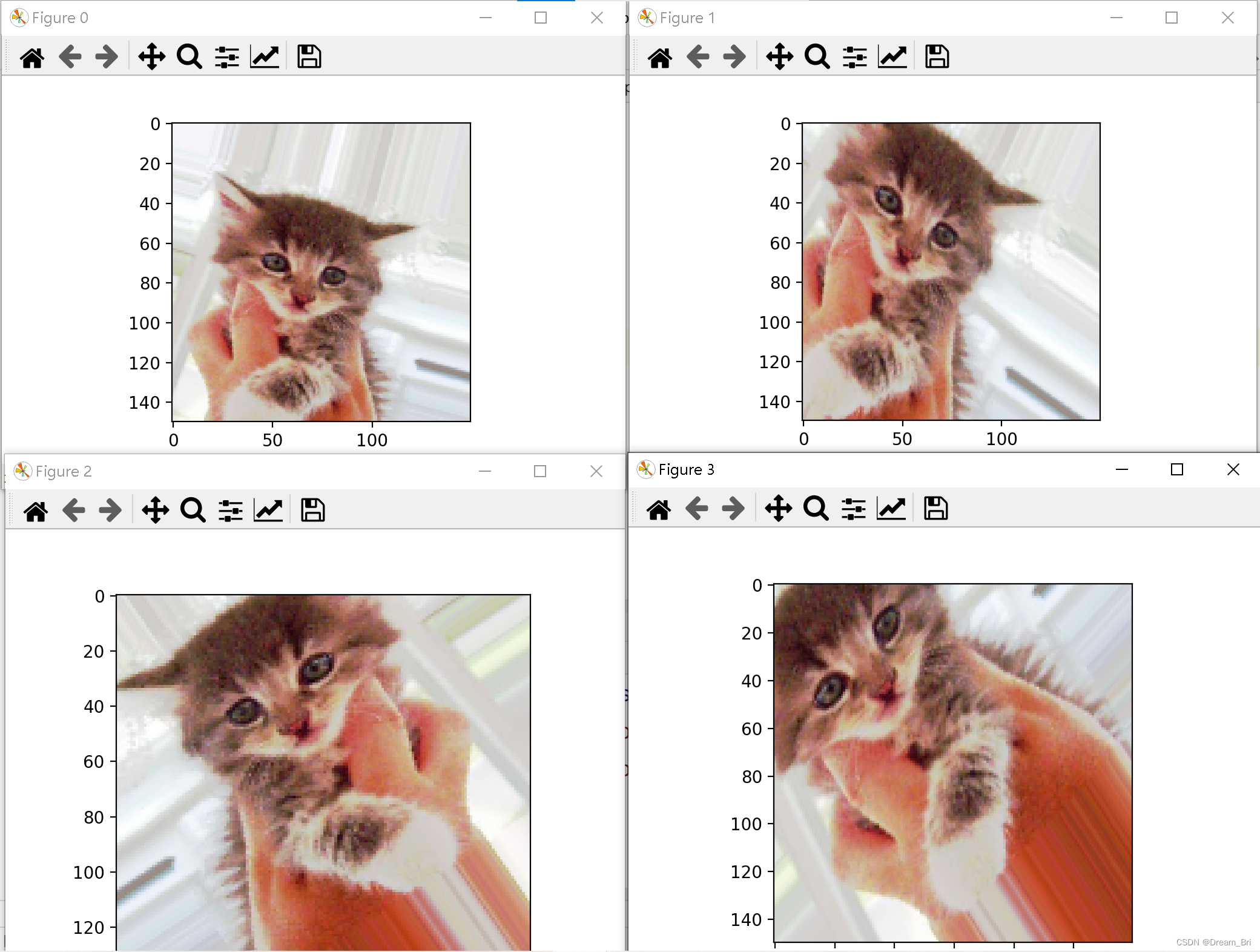
这一节(随机增强后的训练图像显示)的代码也可以单独出结果
使用数据增强的卷积神经网络
网络架构
# 网络架构
from keras import layers
from keras import models
from tensorflow.keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
模型的编译
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
利用数据增强生成器重新训练网络
# 自己的数据集路径
train_dir='D:\\kaggle\\modle_date\\train'
validation_dir='D:\\kaggle\\modle_date\\validation'
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
修改后的拟合函数
拟合函数这里改动了下,原来的steps_per_epoch=100,运行时会出错,原因是数据集量变小,结合运行错误提示,上限可以到63,因此这里改为steps_per_epoch=63;同理, validation_steps也应该随着改变,改为 validation_steps=32,以下代码已做更正。
history = model.fit_generator(train_generator,
# steps_per_epoch=100,
steps_per_epoch=63, # 取上限63
epochs=100,
validation_data=validation_generator,
validation_steps=32) # 改为32
模型的保存
model.save('cats_and_dogs_small_2.h5')
结果输出
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果展示
经过一百个轮次,模型训练完毕
模型的精度和损失图像: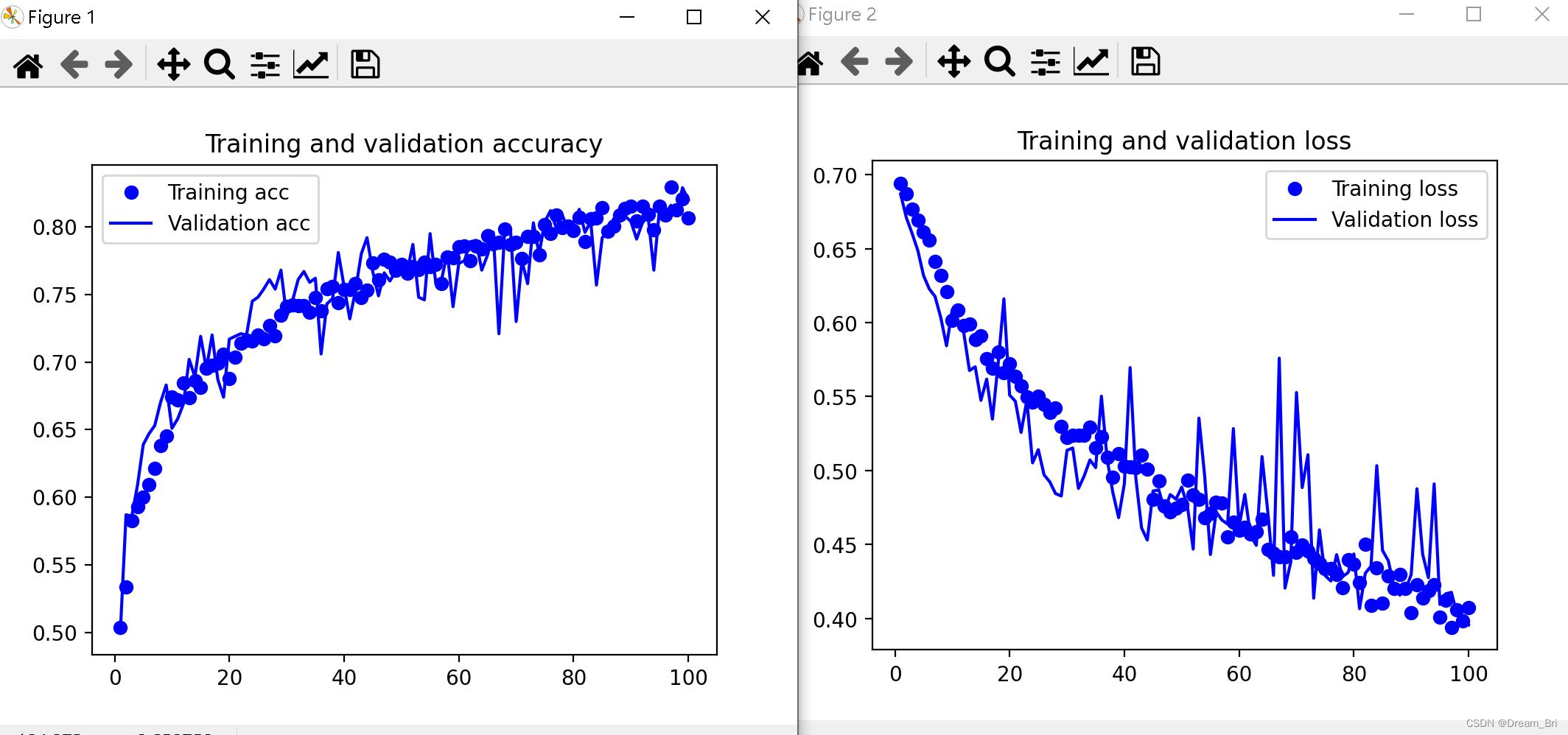
将本节(使用数据增强的卷积神经网络)子代码汇总后就可以编译出以上结果。
代码参考:deep learning with python
版权归原作者 Dream_Bri 所有, 如有侵权,请联系我们删除。