

2024年8⽉28⽇,在ACM SIGKDD(国际数据挖掘与知识发现⼤会,KDD)上会议现场,智谱AI重磅推出了新⼀代全⾃研基座⼤模型 GLM-4-Plus、图像/视频理解模型 GLM-4V-Plus 和⽂⽣图模型 CogView3-Plus。这些新模型,已经全部上线了智谱的开发者平台,开发者已经可以直接调用API去进行开发了。智谱开源模型累计下载量已突破 2000 万次,为开源社区的发展做出了重要贡献。
BigModel旗舰模型更新如下:
- 语言基座模型 GLM-4-Plus :在语言理解、指令遵循、长文本处理等方面性能得到全面提升,保持了国际领先水平。
- 文生图模型 CogView-3-Plus :具备与当前最优的 MJ-V6 和 FLUX 等模型接近的性能。
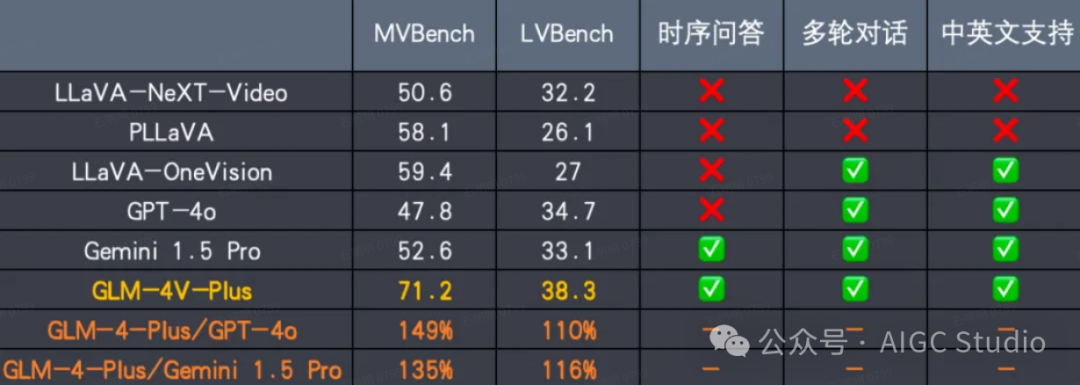
- 图像/视频理解模型 GLM-4V-Plus :具备卓越的图像理解能力,并具备基于时间感知的视频理解能力。该模型将上线开放平台( bigmodel.cn ),并成为国内首个通用视频理解模型 API 。
GLM-4-Plus
在 KDD 国际数据挖掘与知识发现大会上,智谱 GLM 团队发布了新一代基座大模型—GLM-4-Plus。作为智谱全自研 GLM 大模型的最新版本,GLM-4-Plus 标志着智谱AI在通用人工智能领域的持续深耕,推进大模型技术的独立自主创新。
语言能力
GLM-4-Plus 使用了大量模型辅助构造高质量合成数据以提升模型性能,利用PPO有效有效提升模型推理(数学、代码算法题等)表现,更好反映人类偏好。在各项性能指标上,GLM-4-Plus 已达到与 GPT-4o 等第一梯队模型持平的水平。
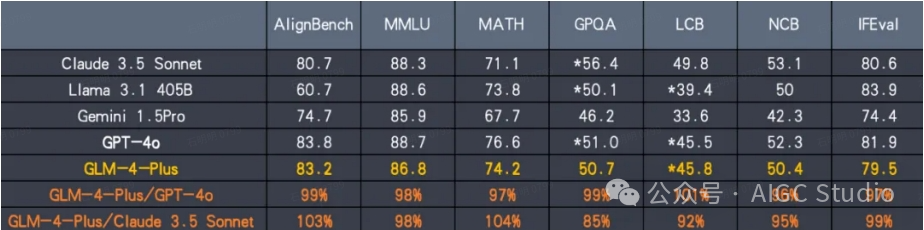
- LCB (LiveCodeBench)
- NCB (NaturalCodeBench)
- *represents reproduced results
长文本能力
GLM-4-Plus 在长文本处理能力上比肩国际先进水平。通过更精准的长短文本数据混合策略,显著增强了长文本的推理效果。
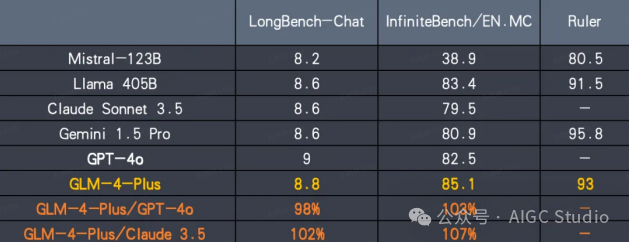
效果展示
下面来测试下GLM-4-Plus在语言理解和指令遵循等方面的表现。比如输入问题:"介绍一下西游记中都有哪些人物,他们使用的武器是什么?”

从上面的回答可以看出GLM-4-Plus精准总结了每一个人物的主要特征、武功技能以及所使用的武器。模型的回答很好的总结了所提问的问题,并没有出现漂移的现象。
在语言文本能力方面,GLM-4-Plus 和 GPT-4o 及 405B 参数量的 Llama3.1 相当。GLM-4-Plus对长文本处理有着非常好的能力,比如输入一段朱自清的短文《背影》让模型描述一下文章的内容并分析文章所表达的情感。
我与父亲不相见已二年余了,我最不能忘记的是他的背影。那年冬天,祖母死了,父亲的差使也交卸了,正是祸不单行的日子。我从北京到徐州,打算跟着父亲奔丧回家。到徐州见着父亲,看见满院狼藉的东西,又想起祖母,不禁簌簌地流下眼泪。父亲说:“事已如此,不必难过,好在天无绝人之路!”回家变卖典质,父亲还了亏空;又借钱办了丧事。这些日子,家中光景很是惨澹,一半为了丧事,一半为了父亲赋闲。丧事完毕,父亲要到南京谋事,我也要回北京念书,我们便同行。到南京时,有朋友约去游逛,勾留了一日;第二日上午便须渡江到浦口,下午上车北去。父亲因为事忙,本已说定不送我,叫旅馆里一个熟识的茶房陪我同去。他再三嘱咐茶房,甚是仔细。但他终于不放心,怕茶房不妥帖;颇踌躇了一会。其实我那年已二十岁,北京已来往过两三次,是没有什么要紧的了。他踌躇了一会,终于决定还是自己送我去。我再三劝他不必去;他只说:“不要紧,他们去不好!”我们过了江,进了车站。我买票,他忙着照看行李。行李太多,得向脚夫行些小费才可过去。他便又忙着和他们讲价钱。我那时真是聪明过分,总觉他说话不大漂亮,非自己插嘴不可,但他终于讲定了价钱;就送我上车。他给我拣定了靠车门的一张椅子;我将他给我做的紫毛大衣铺好座位。他嘱我路上小心,夜里要警醒些,不要受凉。又嘱托茶房好好照应我。我心里暗笑他的迂;他们只认得钱,托他们只是白托!而且我这样大年纪的人,难道还不能料理自己么?我现在想想,我那时真是太聪明了。我说道:“爸爸,你走吧。”他往车外看了看,说:“我买几个橘子去。你就在此地,不要走动。”我看那边月台的栅栏外有几个卖东西的等着顾客。走到那边月台,须穿过铁道,须跳下去又爬上去。父亲是一个胖子,走过去自然要费事些。我本来要去的,他不肯,只好让他去。我看见他戴着黑布小帽,穿着黑布大马褂,深青布棉袍,蹒跚地走到铁道边,慢慢探身下去,尚不大难。可是他穿过铁道,要爬上那边月台,就不容易了。他用两手攀着上面,两脚再向上缩;他肥胖的身子向左微倾,显出努力的样子。这时我看见他的背影,我的泪很快地流下来了。我赶紧拭干了泪。怕他看见,也怕别人看见。我再向外看时,他已抱了朱红的橘子往回走了。过铁道时,他先将橘子散放在地上,自己慢慢爬下,再抱起橘子走。到这边时,我赶紧去搀他。他和我走到车上,将橘子一股脑儿放在我的皮大衣上。于是扑扑衣上的泥土,心里很轻松似的。过一会儿说:“我走了,到那边来信!”我望着他走出去。他走了几步,回过头看见我,说:“进去吧,里边没人。”等他的背影混入来来往往的人里,再找不着了,我便进来坐下,我的眼泪又来了。
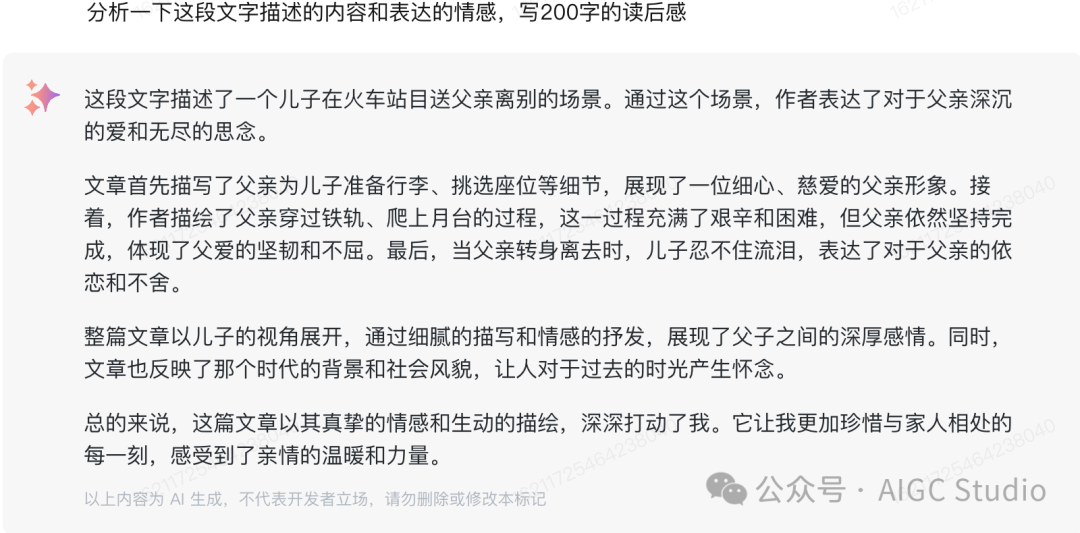
从以上的回答可以看出GLM-4-Plus对于长文本处理以及语言理解的能力非常好。答案不仅精准概括了文章内容,且很好的理解了文章所表达的情感。
调用示例
以下是一个完整的调用示例,可以按此快速上手 GLM-4-Plus 模型。
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4-plus", # 填写需要调用的模型编码
messages=[
{"role": "system", "content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"}
{"role": "user", "content": "农夫需要把狼、羊和白菜都带过河,但每次只能带一样物品,而且狼和羊不能单独相处,羊和白菜也不能单独相处,问农夫该如何过河。"}
],
)
print(response.choices[0].message)
GLM-4V-Plus
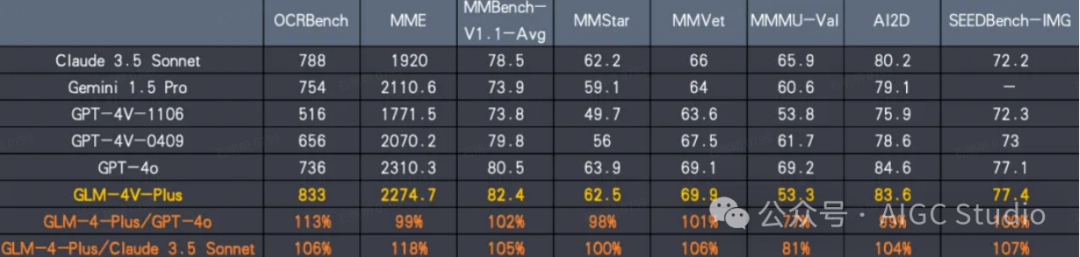
GLM-4V-Plus是基于CogVLM系列模型的研究经验研发的,它集图像理解与视频理解能力于一体的多模态模型。GLM-4V-Plus在图像和视频理解领域均展现出领先水平,稳居行业前列。
视觉能力
视频分析
GLM-4V-Plus 能够理解并分析复杂的视频内容,同时具备时间感知能力。
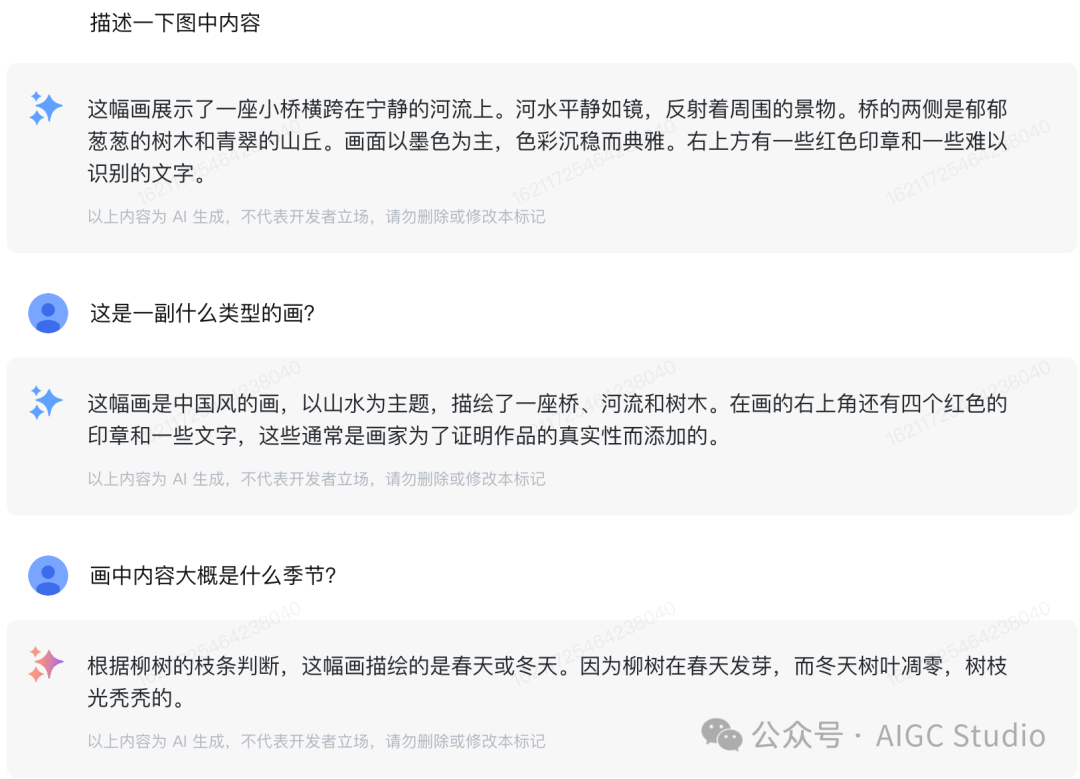
效果展示输入一张古代山水画的图像,可以看到GLM-4V-Plus 能够很好的描述图像内容,还具有连续多轮对话能力,从回答效果看也是很好的联系了输入的图像。

视频理解调用示例
上传视频URL
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="YOUR API KEY") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4v-plus", # 填写需要调用的模型名称
messages=[
{
"role": "user",
"content": [
{
"type": "video_url",
"video_url": {
"url" : "https://sfile.chatglm.cn/testpath/video/b844f8f1-5df9-556c-a515-3d3bfaa736e8_0.mp4"
}
},
{
"type": "text",
"text": "请仔细描述这个视频"
}
]
}
]
)
print(response.choices[0].message)
图片理解示例
上传图片URL
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4v-plus", # 填写需要调用的模型名称
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url" : "https://www.zhipuai.cn/assets/images/aboutus/company.jpeg"
}
},
{
"type": "text",
"text": "图里有什么"
}
]
}
]
)
print(response.choices[0].message)
CogView-3-Plus
CogView-3-Plus使用Transformer架构训练扩散模型,优化了效果并验证了参数量提升的效益。我们还构建了高质量图像微调数据集,使模型生成更符合指令且美学评分更高的图像,效果接近MJ-V6和FLUX等一流模型。
用法
CogView-3-Plus能够根据文本提示生成高质量的图像。支持的图像尺寸包括1024x1024、768x1344、864x1152、1344x768、1152x864、1440x720以及720x1440,默认的图像尺寸为1024x1024。
明确清晰的结构化提示词可以帮助 CogView 创造出更高质量的图像。以下是提示词参考,大家可以点击链接阅读。
图像生成模型 Prompt 工程指南
生成示例
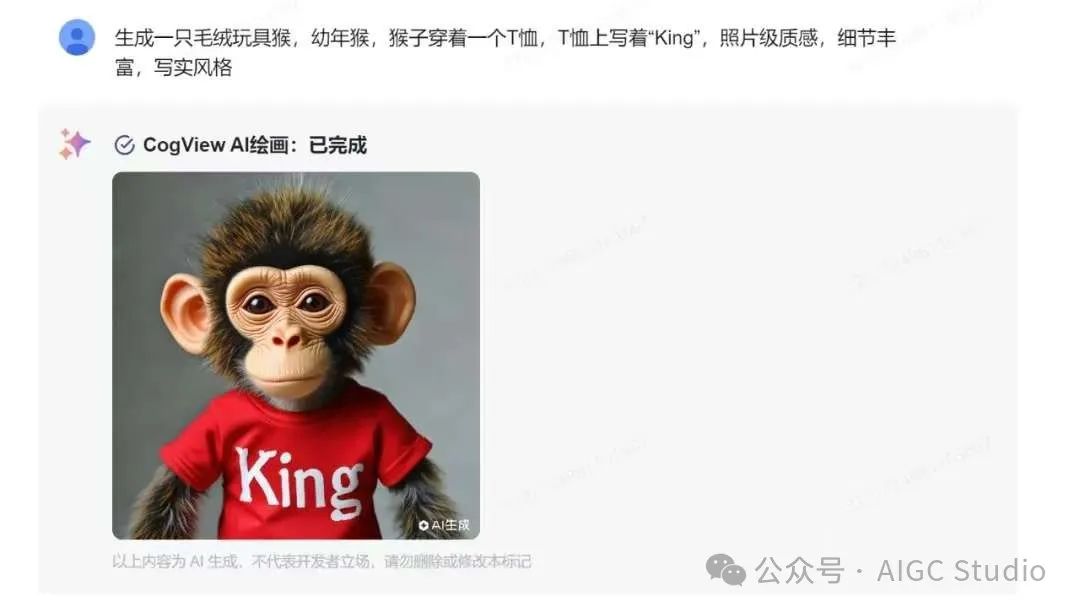
CogView-3-Plus的文生图能力有了显著提升。它可以非常准确地生成单词,这在很多文生图应用中都是高频翻车区。
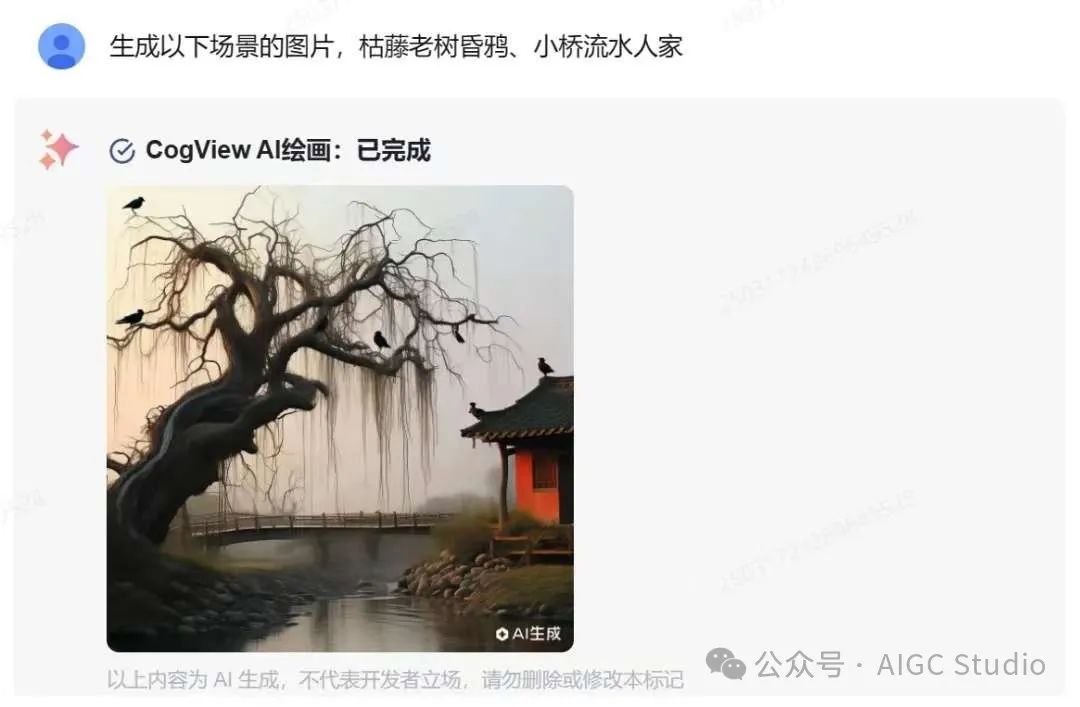
CogView-3-Plus 很好的理解了古诗词含义,不仅画出了所有的元素,还还原了诗词中的意境。
CogView-3-Plus对于人像生成的理解也很到位,生成的内容和提示词高度吻合,同时也不会出现坏脸坏手的情况。
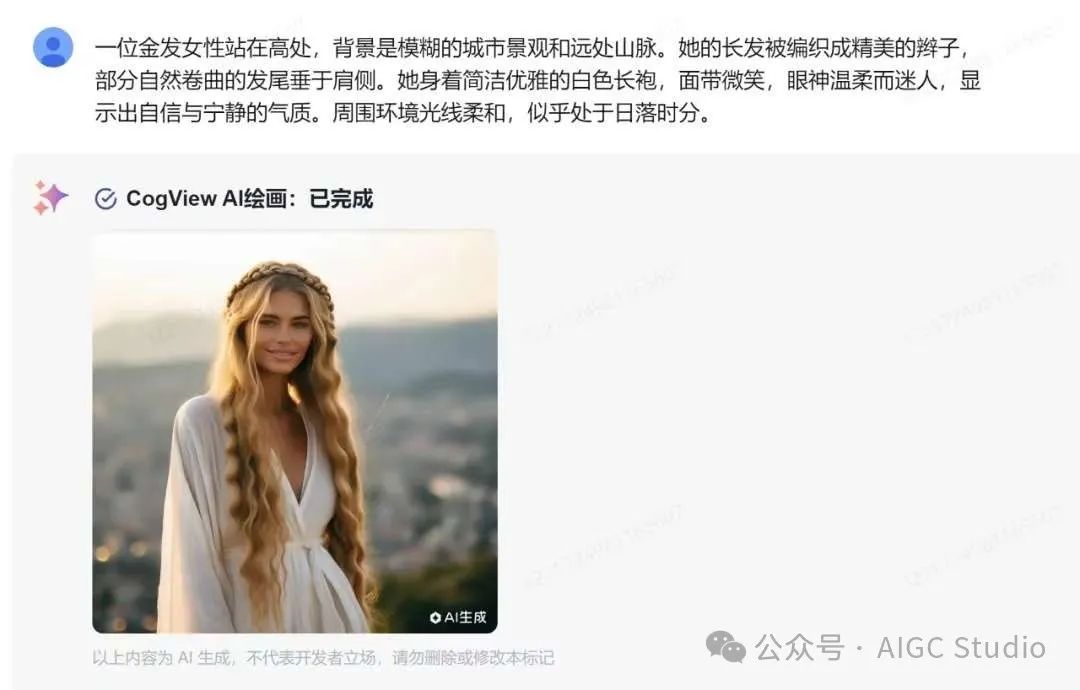
调用示例
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="")
response = client.images.generations(
model="cogView-3-plus", #填写需要调用的模型编码
prompt="在干燥的沙漠环境中,一棵孤独的仙人掌在夕阳的余晖中显得格外醒目。这幅油画捕捉了仙人掌坚韧的生命力和沙漠中的壮丽景色,色彩饱满且表现力强烈。",
size="1440x720"
)
print(response.data[0].url)
总结
智谱AI凭借其卓越的开源模型生态,已在全球范围内取得了显著成就,其模型累计下载量成功跨越2000万次大关,这一里程碑不仅彰显了其在人工智能领域的深厚积累与广泛影响力,也预示着开源合作模式的巨大潜力与活力。
从基础大模型到小模型,从语言到多模态,从技术到产品,智谱在各个方向全面发展,且全方位对标 OpenAI。智谱AI在开源模型方面的工作总结如下:
持续发布并开源创新模型
随着GLM-4-Plus、GLM-4V-Plus以及CogView-3-Plus等一系列创新模型的相继发布,智谱AI展现出了从基础大模型到精细化小模型的全面布局能力,以及从单一语言处理到多模态融合技术的跨越式发展。
推动技术交流与共享
开源平台与工具:智谱AI通过其MaaS大模型开放平台,为开发者提供了便捷的模型访问、微调及部署工具。该平台支持包括GLM-4系列在内的最新开源模型,并推出了一键微调功能及AllTools智能体API,使得开发者能够轻松构建强大的AI助手。
社区建设: 智谱AI积极参与并推动开源社区的建设,鼓励开发者在社区中交流、分享经验并共同优化模型性能。这种开放合作的态度不仅促进了技术的快速迭代与进步,也增强了智谱AI在业界的影响力与号召力。
降低使用门槛与成本
优化硬件需求: 智谱AI在模型设计上注重硬件友好性,如CogVideoX-2B模型在FP-16精度下进行推理时仅需18GB显存,微调则只需40GB显存。这使得开发者即便在有限的硬件资源下也能轻松运行和微调模型。
降低价格: 智谱AI通过技术创新与规模化生产等方式不断降低模型的使用成本。例如,其新一代MaaS平台在价格上进行了大幅优惠,使得更多企业和个人能够承担得起AI技术的使用费用。
在竞争激烈的全球大模型市场中,智谱正通过频繁的技术迭代和开源举措,不断推动行业和生图的发展,赢得了越来越多的关注与认可。
相关链接
本文给大家介绍了智谱AI在大模型领域的创新以及最新的工作如GLM-4-Plus、GLM-4V-Plus以及CogView-3-Plus等,相信小伙伴们已经摩拳擦掌了,大家可以从👇官方网址注册体验,此外也可以加入智谱AI的官方社群。
智谱AI-bigmodel网址
版权归原作者 AIGC Studio 所有, 如有侵权,请联系我们删除。