

前言
通过前几篇文章,相信大家已经学会训练自己的数据集了。本篇是YOLOv5入门实践系列的最后一篇,也是一篇总结,我们再来一起按着配置环境-->标注数据集-->划分数据集-->训练模型-->测试模型-->推理模型的步骤,从零开始,一起实现自己的目标检测模型吧!

前期回顾:
YOLOv5入门实践(1)——手把手带你环境配置搭建
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
YOLOv5入门实践(3)——手把手教你划分自己的数据集
YOLOv5入门实践(4)——手把手教你训练自己的数据集
 🍀本人YOLOv5源码详解系列:
🍀本人YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py

🌟一、 配置环境
传送门:YOLOv5入门实践(1)——手把手带你环境配置搭建
1.1 安装CUDA 和cuDNN
官方教程:
CUDA:cuda-installation-guide-microsoft-windows 12.1 documentation
cuDNN:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
CUDA下载地址→ 官方驱动 | NVIDIA
**cuDNN下载地址→ **cuDNN Download | NVIDIA Developer 
1.2 配置YOLOv5环境
1.yolov5的源码下载
下载地址:mirrors / ultralytics / yolov5 · GitCode
安装压缩包
2.预训练模型下载
将安装好的预训练模型放在YOLO文件下。

**3.安装yolov5的依赖项 **
可以在终端输入 pip3 install -r requirements.txt 来安装这个记事本里的全部需要的库,不过不建议windows系统下这么做。
因为在windows系统里有pycocotools这个库。而我们没有办法通过pip直接安装这个库。
两个解决办法
- 1、直接运行pip3 install pycocotools-windows,这个方法有个小缺陷,就是在某些情况下系统依旧会显示警告信息:找不到pycocotools库,但是程序可以正常运行,
- 2、自行下载pycocotools库,安装包点击这里提取码:i5d7 。下载之后解压,解压下来的文件, conda环境放到 \Lib\site-packages之中,python环境放到 site-packages中。
配置环境是个很繁琐的过程,因为电脑设备不同,大家可能会遇到各种各样的问题,warning级别错误直接无视,报红色的错复制下来在网上也有对应的解决办法,这里就不一 一说了。
🌟二、 标注数据集
2.1 利用labelimg标注数据集
这个之前介绍过,大家可以看这篇回顾一下
传送门:YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
2.2 利用make sense标注数据集
Labelimg和Labelme每次打开比较麻烦,后来看大佬文章被安利了这个在线标注数据集的工具**
Make Sense:
**Make Sense。我们来介绍一下它的使用:
第1步:打开这个网站之后,点击Get Started开始使用

第2步:点击Drop images,然后Ctrl+A选中整个数据集里面的图片

第3步:点击Object Detection 进入目标检测标注模式

第4步:点击**Create Labels **创建标签,这里有两种方法:
- 法1:导入文件自动生成标签(Load labels from file )一行一个
- 法2:手动创建标签,点击左边栏的“+”符号
因为我这里只检测火焰一类,所以只添加一个标签 fire。

** 第5步:创建成功后点击Start project**开始标注。

标注界面支持矩形(Rect)、点(Point)、线(Line)、多边形(Polyygon)多种标注模式,点选相应的模式就可以直接标注了。
(水了一上午的课,终于标注完了。。。)
第6步:点击Action,然后点击**Export Annotation **就可以导出yolo格式的标签文件


导出之后的标签文件就是酱婶儿的
🌟三、 划分数据集
直通车:YOLOv5入门实践(3)——手把手教你划分自己的数据集
**第1步:创建split.py **
在YOLOv5项目目录下创建split.py项目。
**第2步:运行split.py **
import os
import shutil
import random
# 设置随机种子
random.seed(0)
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
'''====1.将数据集打乱===='''
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
# 将两个文件通过zip()函数绑定。
data=list(zip(each_class_image,each_class_label))
# 计算总长度
total = len(each_class_image)
# random.shuffle()函数打乱顺序
random.shuffle(data)
# 再将两个列表解绑
each_class_image,each_class_label=zip(*data)
'''====2.分别获取train、val、test这三个文件夹对应的图片和标签===='''
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
'''====3.设置相应的路径保存格式,将图片和标签对应保存下来===='''
# train
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
# val
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
# test
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = "D:\yolov5-6.1\datasets\image"
xml_path = "D:\yolov5-6.1\datasets\Annotation"
new_file_path = "D:\yolov5-6.1\datasets\ImageSets"
# 设置划分比例
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)
至此,我们的数据集就划分好了。
来运行一下看看效果吧:

🌟四、训练模型
直通车:YOLOv5入门实践(4)——手把手教你训练自己的数据集
4.1 配置文件
(1)修改数据集配置文件
首先在data的目录下新建一个yaml文件,自定义命名(嫌麻烦的话你可以直接复制voc.yaml文件,重命名然后在文件内直接修改。)

然后修改文件内的路径和参数。
train和val就是上一步通过split划分好的数据集文件(最好要填绝对路径,有时候由目录结构的问题会莫名奇妙的报错)
下面是两个参数,根据自己数据集的检测目标个数和名字来设定:
- **nc: ** 存放检测目标类别个数
- name: 存放检测目标类别的名字(个数和nc对应)
这里我做的是火焰检测,所以目标类别只有一个。

(2)修改模型配置文件
我们本次使用的是yolov5s.pt这个预训练权重,同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名,这里我将其重命名为yolov5s_fire.yaml。

同样,这里改一下nc就行哒

4.2 训练模型
训练模型是通过train.py文件,在训练前我们先介绍一下文件内的参数
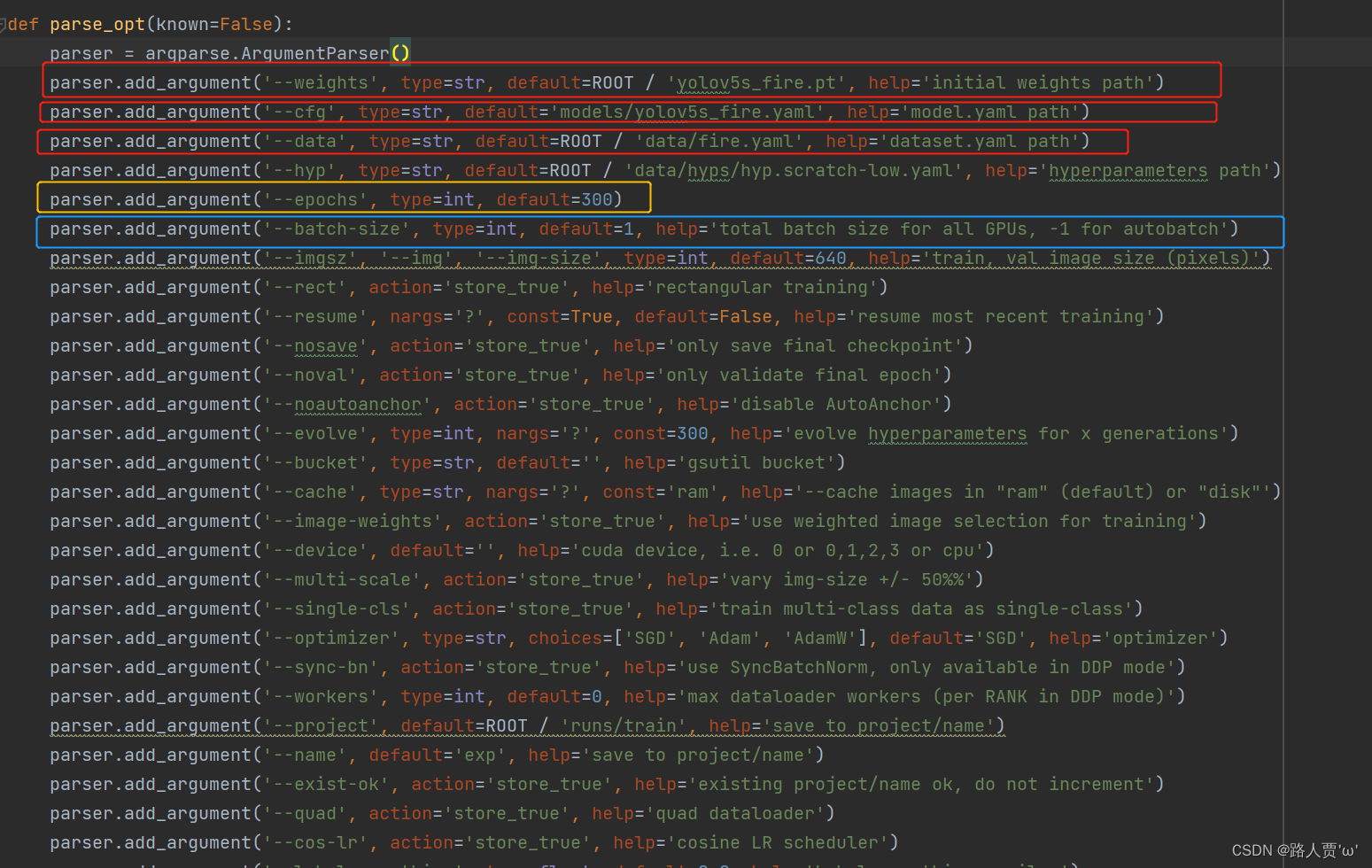
**opt参数解析: **
- **cfg: ** 模型配置文件,网络结构
- **data: ** 数据集配置文件,数据集路径,类名等
- hyp: 超参数文件
- epochs: 训练总轮次
- **batch-size: ** 批次大小
- **img-size: ** 输入图片分辨率大小
- **rect: ** 是否采用矩形训练,默认False
- resume: 接着打断训练上次的结果接着训练
- **nosave: ** 不保存模型,默认False
- **notest: ** 不进行test,默认False
- **noautoanchor: ** 不自动调整anchor,默认False
- **evolve: ** 是否进行超参数进化,默认False
- **bucket: ** 谷歌云盘bucket,一般不会用到
- **cache-images: ** 是否提前缓存图片到内存,以加快训练速度,默认False
- **weights: ** 加载的权重文件
- **name: ** 数据集名字,如果设置:results.txt to results_name.txt,默认无
- **device: ** 训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
- **multi-scale: ** 是否进行多尺度训练,默认False
- single-cls: 数据集是否只有一个类别,默认False
- **adam: ** 是否使用adam优化器
- **sync-bn: ** 是否使用跨卡同步BN,在DDP模式使用
- local_rank: gpu编号
- **logdir: ** 存放日志的目录
- **workers: ** dataloader的最大worker数量
(关于train.py更多学习请看:YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py)
然后做以下修改:
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s_fire.pt', help='initial weights path')
** --weight :**先选用官方的yolov5s.pt权重,当自己的训练完成后可更换为自己的权重。
parser.add_argument('--cfg', type=str, default='models/yolov5s_fire.yaml', help='model.yaml path')
--cfg:选用上一步model目录下我们刚才改好的模型配置文件。
parser.add_argument('--data', type=str, default=ROOT / 'data/fire.yaml', help='dataset.yaml path')
** --data:**选用上一步data目录下我们刚才改好的数据集配置文件。
parser.add_argument('--epochs', type=int, default=300)
** --epoch:**指的就是训练过程中整个数据集将被迭代多少轮,默认是300,显卡不行就调小点
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
--batch-size:一次看完多少张图片才进行权重更新,默认是16,显卡不行就调小点
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
** --workers:** dataloader的最大worker数量,一般用来处理多线程问题,默认是8,显卡不行就调小点
以上都设置好了就可以开始训练啦~
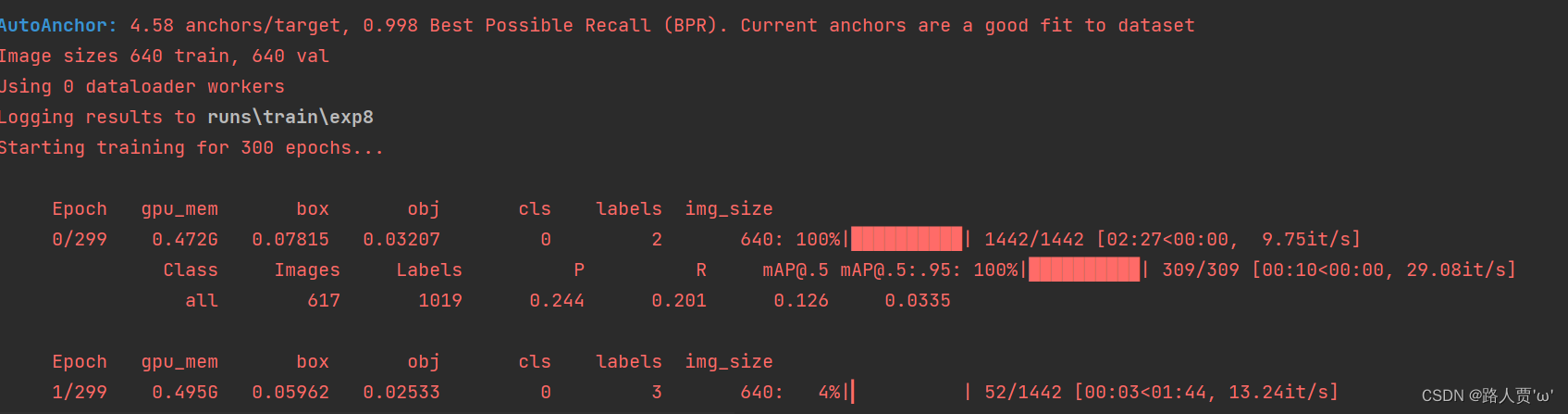
若干个hours之后~
训练结果会保存在runs的train文件里。
至此,我们的模型训练就全部完成了~
🌟五、测试模型
评估模型好坏就是在有标注的测试集或者验证集上进行模型效果的评估,在目标检测中最常使用的评估指标为mAP。在val.py文件中指定数据集配置文件和训练最优结果模型。
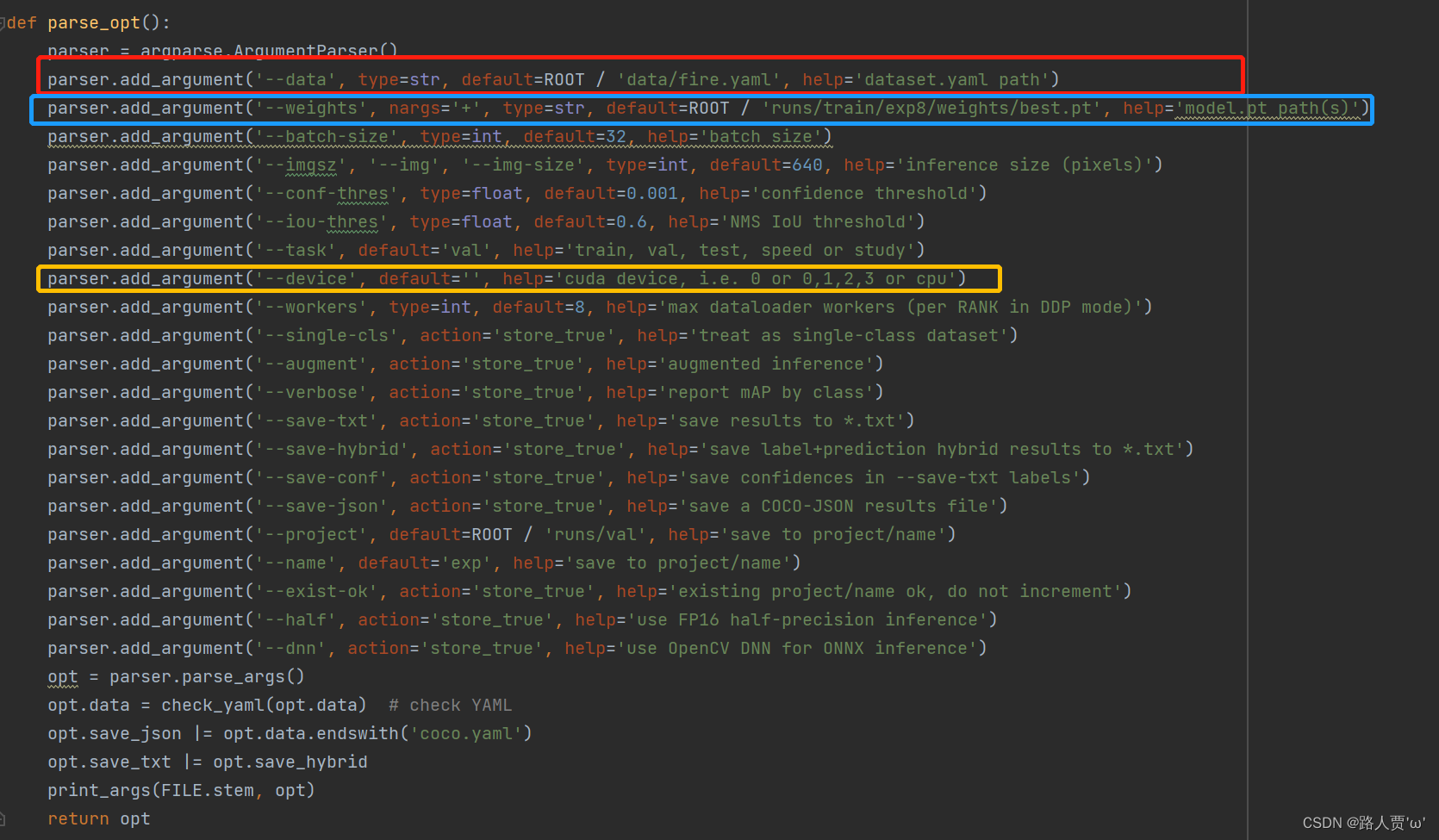
**opt参数解析: **
- data: 数据集文件的路径,默认为COCO128数据集的配置文件路径
- weights: 模型权重文件的路径,默认为YOLOv5s的权重文件路径
- **batch_size: ** 前向传播的批次大小,运行val.py传入默认32 。运行train.py则传入batch_size // WORLD_SIZE * 2
- imgsz: 输入图像的大小,默认为640x640
- conf_thres: 置信度阈值,默认为0.001
- iou_thres: 非极大值抑制的iou阈值,默认为0.6
- **task: ** 设置测试的类型 有train, val, test, speed or study几种,默认val
- device: 使用的设备类型,默认为空,表示自动选择最合适的设备
- **single_cls: ** 数据集是否只用一个类别,运行val.py传入默认False 运行train.py则传入single_cls
- augment: 是否使用数据增强的方式进行检测,默认为False
- verbose: 是否打印出每个类别的mAP,运行val.py传入默认Fasle。运行train.py则传入nc < 50 and final_epoch
- save_txt: 是否将检测结果保存为文本文件,默认为False
- save_hybrid: 是否保存 label+prediction hybrid results to *.txt 默认False
- save_conf: 是否在保存的文本文件中包含置信度信息,默认为False
- save_json: 是否按照coco的json格式保存预测框,并且使用cocoapi做评估(需要同样coco的json格式的标签)运行test.py传入默认Fasle。运行train.py则传入is_coco and final_epoch(一般也是False)
- project: 结果保存的项目文件夹路径,默认为“runs/val”
- name: 结果保存的文件名,默认为“exp”
- exist_ok: 如果结果保存的文件夹已存在,是否覆盖,默认为False,即不覆盖
- **half: **是否使用FP16的半精度推理模式,默认为False
- dnn: 是否使用OpenCV DNN作为ONNX推理的后端,默认为False
(关于val.py更多学习请看:YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py)
然后做以下修改:
parser.add_argument('--data', type=str, default=ROOT / 'data/fire_data.yaml', help='dataset.yaml path')
--data:选用上一步data目录下我们刚才改好的数据集配置文件
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp8/weights/best.pt', help='model.pt path(s)')
** --weight :**换成我们训练完成后最好的权重
同样的,我们验证完后依然可以得到一个文件夹:
哒哒~让我们来看一下检测效果:

注意,在这个过程中可能会遇到报错:Exception: Dataset not found.

这是数据集路径问题,这是就要检查一下你的数据集和YOLOv5项目是否在同一级目录哦。
🌟六、推理模型
最后,在没有标注的数据集上进行推理,在YOLOv5目录下的detect.py文件下修改参数即可:
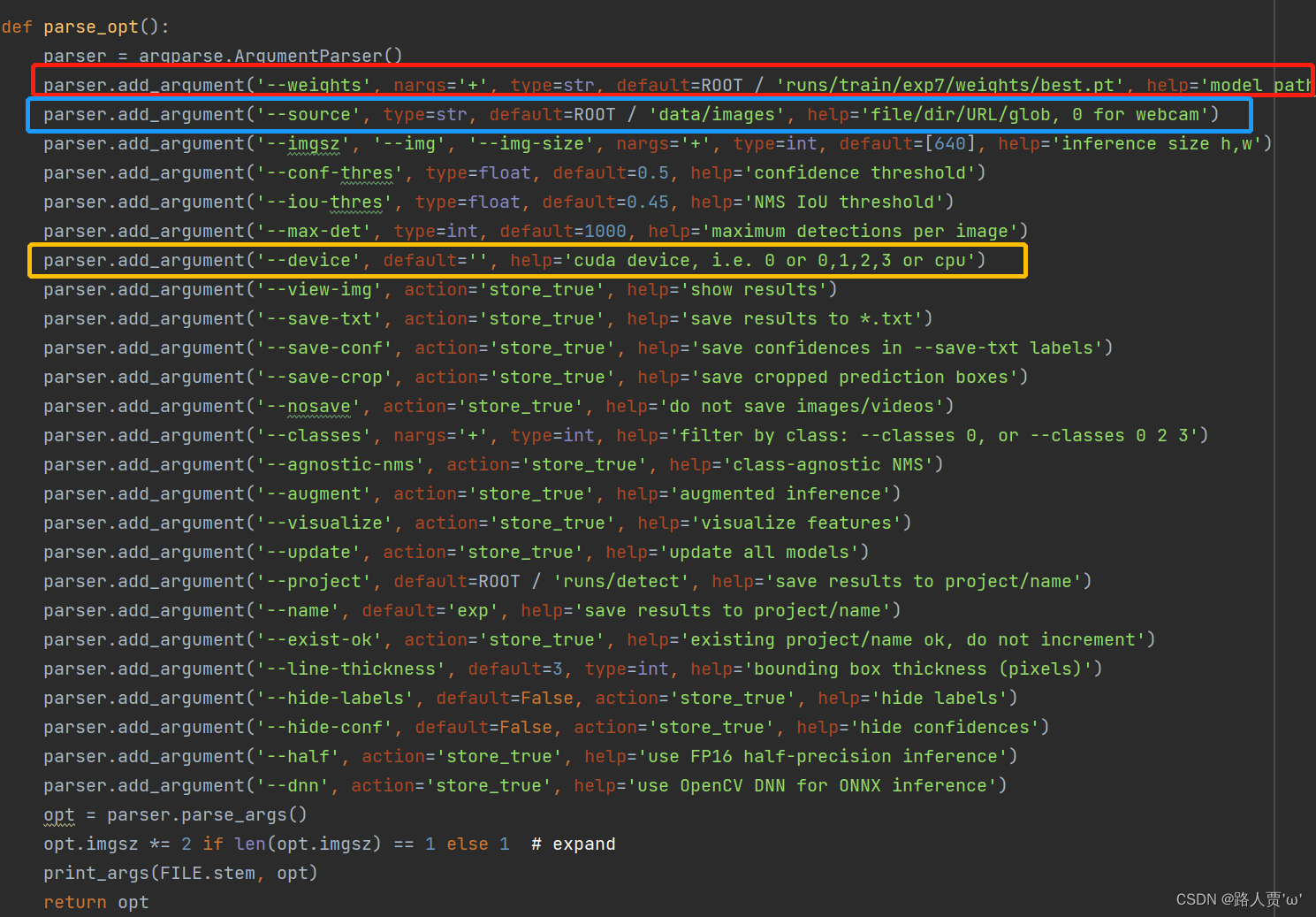
**opt参数解析: **
- weights: 训练的权重路径,可以使用自己训练的权重,也可以使用官网提供的权重。默认官网的权重yolov5s.pt(yolov5n.pt/yolov5s.pt/yolov5m.pt/yolov5l.pt/yolov5x.pt/区别在于网络的宽度和深度以此增加)
- source: 测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流, 默认data/images
- data: 配置数据文件路径,包括image/label/classes等信息,训练自己的文件,需要作相应更改,可以不用管
- imgsz: 预测时网络输入图片的尺寸,默认值为 [640]
- conf-thres: 置信度阈值,默认为 0.50
- iou-thres: 非极大抑制时的 IoU 阈值,默认为 0.45
- **max-det: **保留的最大检测框数量,每张图片中检测目标的个数最多为1000类
- device: 使用的设备,可以是 cuda 设备的 ID(例如 0、0,1,2,3)或者是 'cpu',默认为 '0'
- view-img: 是否展示预测之后的图片/视频,默认False
- save-txt: 是否将预测的框坐标以txt文件形式保存,默认False,使用--save-txt 在路径runs/detect/exp*/labels/*.txt下生成每张图片预测的txt文件
- save-conf: 是否保存检测结果的置信度到 txt文件,默认为 False
- save-crop: 是否保存裁剪预测框图片,默认为False,使用--save-crop 在runs/detect/exp*/crop/剪切类别文件夹/ 路径下会保存每个接下来的目标
- nosave: 不保存图片、视频,要保存图片,不设置--nosave 在runs/detect/exp*/会出现预测的结果
- classes: 仅检测指定类别,默认为 None
- agnostic-nms: 是否使用类别不敏感的非极大抑制(即不考虑类别信息),默认为 False
- augment: 是否使用数据增强进行推理,默认为 False
- visualize: 是否可视化特征图,默认为 False
- **update: ** 如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
- project: 结果保存的项目目录路径,默认为 'ROOT/runs/detect'
- **name: ** 结果保存的子目录名称,默认为 'exp'
- exist-ok: 是否覆盖已有结果,默认为 False
- line-thickness: 画 bounding box 时的线条宽度,默认为 3
- hide-labels: 是否隐藏标签信息,默认为 False
- hide-conf: 是否隐藏置信度信息,默认为 False
- half: 是否使用 FP16 半精度进行推理,默认为 False
- dnn: 是否使用 OpenCV DNN 进行 ONNX 推理,默认为 False
(关于detect.py更多学习请看:YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py)
然后做以下修改:
parser.add_argument('--data', type=str, default=ROOT / 'data/fire_data.yaml', help='dataset.yaml path')
--data:选用上一步data目录下我们刚才改好的数据集配置文件
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp8/weights/best.pt', help='model.pt path(s)')
** --weight :**换成我们训练完成后最好的权重
同样的,我们推理完后依然可以得到一个文件夹:
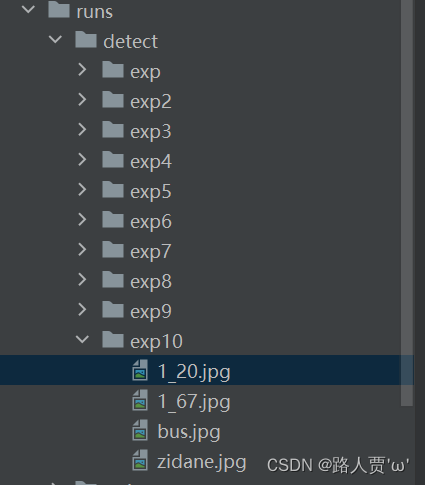
Come On!让我们来看一下检测效果:

注意,在这个过程中可能会遇到报错:AssertionError: Image Not Found D:\fire项目\yolov5-fire\data\images\1_20.jpg 
这个问题很简单,错误原因就是测试图片中包含中文路径,把文件夹中文全部修改成英文即可(太低级的错误了。。。)
🌟七、PYQT可视化界面显示
7.1 配置环境
第1步:先安装pyqt5
pip install PyQt5
pip install PyQt5-tools
安装成功后,可以在pycharm的解释器的安装包列表中查看到pyqt5对应的库名称
第2步:配置pycharm工具
pycharm工具配置后可以快速便捷的打开工具以及使用,避免复杂的文件拷贝与打开应用程序地址等操作。

(1)QtDesigner
QtDesigner是一个图形化的界面设计工具,可以直观的进行界面设计。
pycharm的External Tools添加可以按照以下步骤进行:
*1.在pycharm中依次选择:***File-settings-->**Tools-->External Tools-->左上角‘+’号
步骤如下图所示:
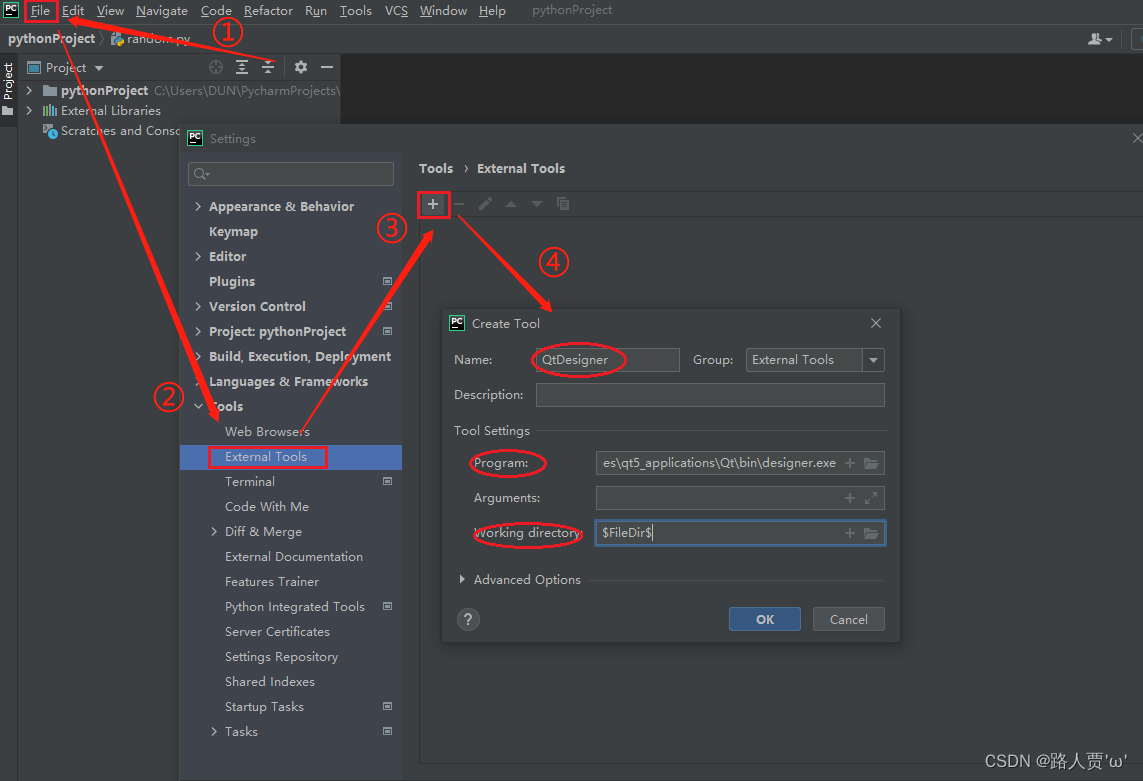
2.在弹出的窗口中填写tool的配置内容:
- **Name: **QtDesigner(用于在Tools-External中显示的名称,可自行填写)
- **Program: **可以通过点击右侧文件夹标识选择QtDesigner的安装位置;也可直接粘贴designer.exe的绝对物理地址
- Working directory: 可点击右侧‘+’号选择FileDir --> File directory,见下图;或者也可直接输入**$FileDir$**(用于设置默认的文件保存位置)
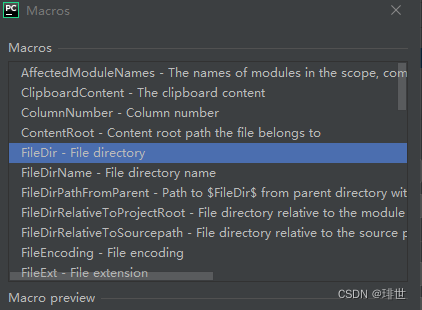
3.配置完成后点击OK即可。
(2)PyUIC
PyUIC是一个代码转换工具,可以将QtDesigner输出的.ui文件转换为py文件。
pycharm的External Tools按照同样的步骤进行:
1.在pycharm中依次选择:File-settings-->Tools-->External Tools-->左上角‘+’号
步骤如下图所示:

2.在弹出的窗口中填写tool的配置内容:
- Name:PyUIC(用于在Tools-External中显示的名称,可自行填写)
- Program:可以通过右侧文件夹标识选择PyUIC的安装位置,也可直接粘贴pyuic5.exe的绝对物理地址
- Arguments:直接填写**$FileName$ -o $FileNameWithoutExtension$.py**(用于设置生成的py文件的名称,此语句的含义为 原有的文件名称+.py)
- Working directory:可点击右侧‘+’号选择FileDir --> File directory;也可直接输入 **$FileDir$**(用于设置默认的文件保存位置)
3.配置完成后点击OK即可。
(3)PyRcc
PyRcc是一个代码转换工具,用于将界面设计时的图像编辑文件qrc转换为py文件。
如果不涉及界面的图片添加等内容时,可以暂不考虑此工具的添加。
1.在pycharm中依次选择:File-settings-->Tools-->External Tools-->左上角‘+’号
步骤如下图所示:

2.在弹出的窗口中填写tool的配置内容:
- Name:PyRcc(用于在Tools-External中显示的名称,可自行填写)
- Program:可以通过右侧文件夹标识选择PyRcc的安装位置,也可直接粘贴pyrcc5.exe的绝对物理地址
- Arguments:直接填写**$FileName$ -o $FileNameWithoutExtension$.py**(用于设置生成的py文件的名称,此语句的含义为原有的文件名称+.py)
- Working directory:可点击右侧‘+’号选择FileDir - File directory;也可直接输入 **$FileDir$**(用于设置默认的文件保存位置)
3.配置完成后点击OK即可。
(4)pycharm中查看工具
配置完以上三个工具之后,可以在pycharm的Tools-External Tools中查看到以下三个工具:

至此,PYQT的环境配置就完成啦~
7.2 界面显示
(1)图片/视频检测

(2)摄像头检测
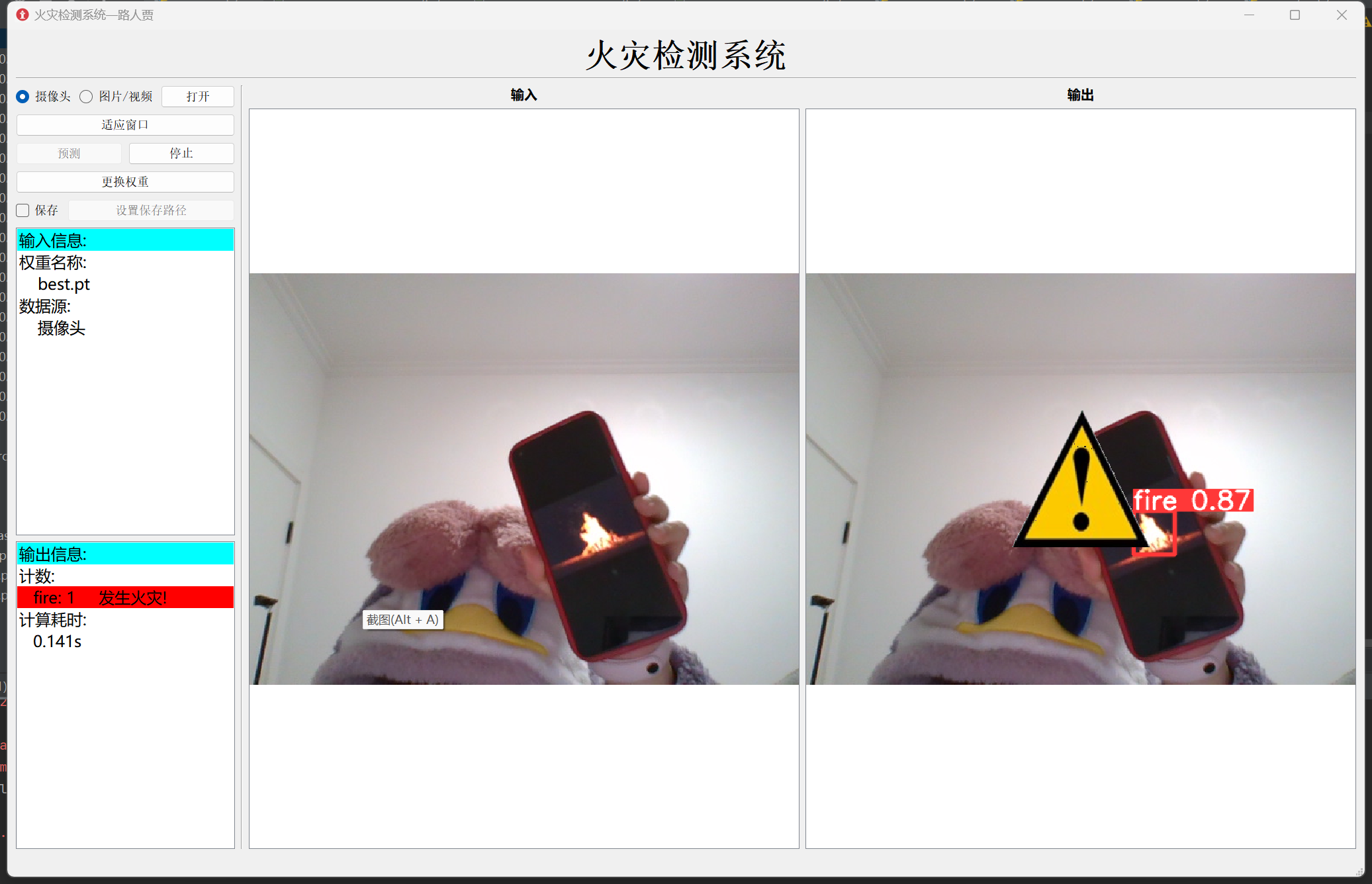
(PYQT的页面制作教程以后有空会单独出的)
最后一些碎碎念:
好啦至此我们YOLOv5的入门实践系列就结束了
其实火灾系统检测这个项目是寒假开始做的,那时候我还不知道啥是YOLO,直接从网上扒来开源项目就开始跑了,甚至数据集都是人家现成划分好的。
后来从二月中旬开始从头读YOLO论文,了解了个大概算法过程,三月份开始做源码详解,自认为把每个文件都熟悉了,当时啥都懂了但很快又忘了,知识也只是短暂又浅显地划过大脑,我很清楚实际上我还是啥也不会。
这周开启了入门实践项目,从配置环境开始,自己标注数据集,划分数据集,训练模型,检测和验证模型等等。真的是从零开始一步一步地进行,终于自己独立完成了这个过程,也解决了很多当时并没理解的问题,有了新的认识,前期的知识也串在了一起,所以亲手实践真的很重要!(呜呜,我真的太棒了!)
哈哈,我的YOLO学习也算入门了,接下来要进行更深入的研究了!一起加油吧!

版权归原作者 路人贾'ω' 所有, 如有侵权,请联系我们删除。