
文章目录
0. 前言
大家好,我是anduin。今天为大家带来的是结构体的详细讲解。在C语言中,结构体可谓是很重要的一块内容,特别是在学习数据结构时,结构体更发挥了极大的作用。而本篇博客,我们将对结构体的基础知识和结构体内存对齐等知识作出详细讲解。话不多说,我们这就开始。
1. 结构的基础知识
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
2. 结构的声明
structtag//结构体标签(自定义){
member-list;//成员列表}variable-list;//变量列表(全局变量)
例如描述一个学生:
structStu{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号};
这里和上方结构的声明不太一样,少了变量列表,这个和我们本身创建变量有关,在变量列表中创建变量,就为全局变量,在主函数中创建变量就是局部变量,变量列表是可以省略的。
3 结构体创建变量
structBook{char book_name[20];char author[20];int price;char id[15];}s3,s4;//sb3 sb4也是struct Book类型的结构体变量//是全局变量intmain(){structBook s1;//局部变量structBook s2;//局部变量return0;}
在主函数和结构体末尾创建的结构体变量作用域不同。
4. 特殊的声明
4.1 匿名结构体
在声明结构时,可以不完全的声明,例如:
struct{char name[20];float price;char id[12];}sw;
我们可以看到这个结构体并没有名字,所以称它为
匿名结构体
。但是它如何使用?
匿名结构体只能在变量列表处,也就是结构体结尾的分号前创建变量,且这个变量为全局变量,相当于一次性使用。不能在别处创建变量。
4.2 小细节
当两个成员列表相同的匿名结构体,它们的类型是否相同?
struct{int a;char b;float c;}*p;//结构体指针,指向结构体struct{int a;char b;float c;}ss;//匿名结构体的成员如果一样,在编译器看来也是不同类型的结构体intmain(){
p =&ss;return0;}
两个匿名结构体成员列表相同,那么将匿名结构体创建的ss变量的地址赋给一个结构体指针,是否可行?当我们编译过后发现它们的类型并不一样,以下是编译结果:

分析:
如果以我们平常的想法,它们的结果应该相同。但是编译过后,发现两个匿名结构体变量类型并不相同,依此我们可以得出结论:匿名结构体的成员如果一样,在编译器看来也是不同类型的结构体。
总的来说,当一个结构体只想使用一次时,就可以使用匿名结构体。
5. 结构体的自引用
5.1 错误的自引用方式
例如在结构体中包含一个类型为该结构体本身的成员是否可以?例如一个链表的节点的结构体,如果想要让这个节点能找到下一个节点,于是在里面放置下一个节点的结构体,可行吗?
//代码1structNode{int data;structNode next;};
分析:
这样是不行的,如果在结构体中放置下一个节点,那么
sizeof(struct Node)
的大小为多少?Node里面整形的大小为4个字节,但是剩下一个元素也就是另一个Node是不可知的,这样无限套娃就无法计算大小,所以这样是不可行的。
5.2 正确的自引用方式
要找到下一个节点,那么可以通过地址,也就是通过结构体指针来访问,可以在本次节点中存放下一个节点的地址,这样便可以知道在一个节点中另一个成员的大小:
structNode{int data;structNode* next;//下一个节点的地址};intmain(){structNode n;//创建结构体变量return0;}
但是如果按照这样写,在创建一个节点的结构体变量时,写结构体的类型时十分繁琐,能不能把struct省略呢?我们知道直接省略肯定是错误的,那应该使用什么"工具"?
6. typedef
6.1 如何重命名
typedef
为类型重命名,通过它便可以对复杂的类型进行重命名,比如重命名当前结构体:
typedefstructNode//typdef对struct Node 进行类型重命名{int data;structNode* next;}Node;//重命名后名字为Nodeintmain(){
Node n;//创建结构体变量return0;}
只要在typedef后写上对应的类型,然后再结构体分号前写上命名名称,便可完成重命名!
经过重命名后,这样是不是创建变量更加简单了?但是思考一个问题,我们能否这么写:
typedefstructNode//typdef对struct Node 进行类型重命名{int data;
Node* next;}Node;//重命名后名字为Node
这样写是万万不可的,结构体中使用的是重命名之后的类型,这时Node还未重命名呢。所以不能在重命名之前使用重命名后的名字!!!
编译结果:

6.2 小细节
如果我在类型重命名时这么写呢?
typedefstructNode//typdef对struct Node 进行类型重命名{int data;structNode* next;}Node,hello, world;intmain(){
Node n;
hello h;
world j;return0;}
我一下写了三个重命名的类型名,这样的话我所创建的3个变量的类型是什么?

发现三个类型重命名后都是Node类型,它们的类型是由什么决定的?
分析:
这是一种"变态"的做法,因为在实际使用中,这样做后面的变量类型就混乱了。变量的类型就是
typedef
重定的类型来决定的,它会根据重定义来解析到对应的结构类型。也就是说这三个变量的内存空间分布本质上还是这个结构体的内存分布,但是就上层使用上来说,编译器有可能会认为这三个变量不是同一种类型。
但是很巧的是我当前使用的vs编译器是都解析到Node类型的,但是如果给用户来看,那么肯定是难受的。我们通常类型重命名时就定义一个名字!!!
6.3 匿名结构体的重命名
人说:”匿名结构体很可怜,我们是否也能给它一个名字,让它在主函数中创建局部结构体变量?“
神说:“满足你!”
typedefstruct{int data;structNode* next;}name;intmain(){
name q1;//匿名结构体重命名后创建变量return0;}
匿名结构体很开心,它也有了名字。
一个小插曲,活跃一下气氛但是匿名结构体用typedef重命名是没问题的哈
7. 结构体变量的定义和初始化
7.1 变量的定义
有了结构体类型,就可以定义结构体变量:
structBook{char book_name[20];char author[20];int price;char id[15];}sb3,sb4;//全局变量structBook sb5;//全局变量intmain(){structBook sb1;//局部变量return0;}
注:不要以为全局的结构体变量只能在结构体末尾定义,只要不在{}中定义的变量均为全局变量,所以像
sb5
也是全局变量。
7.2 变量的初始化
7.2.1 结构体有序初始化
一般来说,我们通常按照顺序初始化变量:
structBook{char book_name[20];char author[20];int price;char id[15];}sb3 ={"bc","scw",26,"cw10001"}, sb4;structBook sb5 ={"nsjl","111",34,"ns10001"};intmain(){structBook sb1 ={"clanguage","thq",89,"hq10001"};return0;}
但是这种初始化结构体成员必须全部初始化,否则初始化时数据会混乱。比如:
structS{char c;int a;float f;};intmain(){structS s ={10,3.14f};//c成员未初始化printf("%c %d %f\n", s.c, s.a, s.f);return0;}
运行结果:

7.2.2 结构体无序初始化
但有时我们只想初始化部分成员或乱序初始化时,可以用这种写法:
#include<stdio.h>structS{char c;int a;float f;};intmain(){structS s ={'w',10,3.14f};printf("%c %d %f\n", s.c, s.a, s.f);structS s2 ={.f =3.14f,.c ='w'};printf("%c %d %f\n", s2.c, s2.a, s2.f);return0;}
分析:
当我们使用这种方法初始化时,可以进行乱序初始化,也可以初始化部分值。例如当前我就初始化了
f, c
,未初始化的a会被默认初始化为0。
运行结果:

7.2.3 结构体嵌套初始化
结构体类型如果嵌套定义的话,在初始化时就需要加上
{ }
,并且采用对应的初始化方式,对嵌套的结构体内容进行初始化。
有序:
structPoint{int x;int y;};structS{char c;int a;structPoint p;};intmain(){structS s ={'w',10,{4,6}};printf("%c %d %c %d\n", s.c, s.a, s.p.x, s.p.y);return0;}
运行结果:

无序:
structPoint{int x;int y;};structS{char c;int a;structPoint p;};intmain(){structS s ={'w',10,{4,6}};printf("%c %d %c %d\n", s.c, s.a, s.p.x, s.p.y);return0;}
这里无序初始化只初始化部分内容时,其他的元素也是初始化为0。
运行结果:

8 结构体内存对齐
8.1 问题引入
到这里,结构体的基础知识我们基本了解了。
但是结构体的大小如何计算?这我们就不得而知了,看一个样例:
structS1{char c1;//1int i;//4char c2;//1};structS2{char c1;char c2;int i;};intmain(){structS1 s1;structS2 s2;printf("%d\n",sizeof(s1));//12printf("%d\n",sizeof(s2));//8return0;}
按照我们平时的想法,这两个结构体成员相同,那么就是1+4+1=6了吗?让我们运行一下:

8.2 offsetof
我们发现结果和我们的想法截然不同,这是为什么?
在解答之前我们先了解两部分,先介绍第一部分:
offsetof
:
size_toffsetof( structName, memberName );
- structName:结构体类型的名称
- memberName:结构体成员名
计算结构体成员相对于起始位置的偏移量
让我们先计算一下S1每个成员的偏移量:
#include<stddef.h>//所需头文件structS1{char c1;int i;char c2;};intmain(){printf("%u\n",offsetof(structS1, c1));printf("%u\n",offsetof(structS1, i));printf("%u\n",offsetof(structS1, c2));return0;}
运行结果:

根据这个偏移量,我们假设一个位置为起始位置,画出它的内存分布图:

而其中1~3的内存单位是被浪费的,且根据大小为12。9,10,11三个位置也是被浪费的。这是什么原因?看下一部分↓
8.3 结构体的内存对齐
要说这里的原理,就要讲讲结构体的内存对齐:
- 第一个成员在与结构体变量偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。 VS中默认的值为8
- 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
通过这些规则,我们再重新看一下S1:
分析:
- c1为结构体第一个成员,在结构体变量偏移量为0的地址处,占用1个字节。
- i的大小为4,默认对齐数为8,取其较小值为4。对齐到4的倍数处,也就是偏移为4的位置,占用4个字节,1,2,3三个字节被浪费。
- c2的大小为1,默认对齐数为8,取其较小值对为1。对齐到1的倍数处,也就是偏移为8的位置,占用1个字节。
- 结构体的总大小为最大对其数的整数倍。c1,i,c2的对齐数分别为1,4,1。结构体大小为4的倍数,当前结构体所占空间大小为9字节,要为4的倍数,则大小为1字节2,9,10,11三个字节被浪费。
这样就解释了为什么S1的大小为什么是12!我们接着看S2:
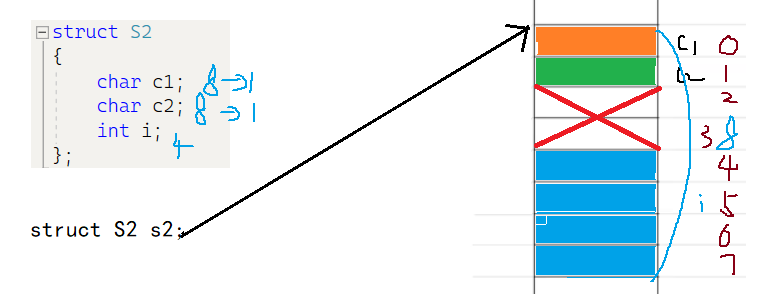
structS1{char c1;char c2;int i;};
分析:
- c1为结构体第一个成员,在结构体变量偏移量为0的地址处,占用一个字节。
- c2的大小为1,默认对齐数为8,取其较小值为1。对齐到1的倍数处,也就是偏移为1的位置,占用1个字节。
- i的大小为4,默认对齐数为8,取其较小值为4。对齐到4的倍数处,也就是偏移为4的位置,占用4个字节。2,3两个字节被浪费。
- 结构体的总大小为最大对其数的整数倍。c1,c2,i的对齐数分别为1,1,4。结构体大小为4的倍数,直接为当前结构体所占空间大小:8字节。
8.4 小试牛刀
自己试着计算两个结构体的大小并描述内存分布和画出内存分布图:
题1:
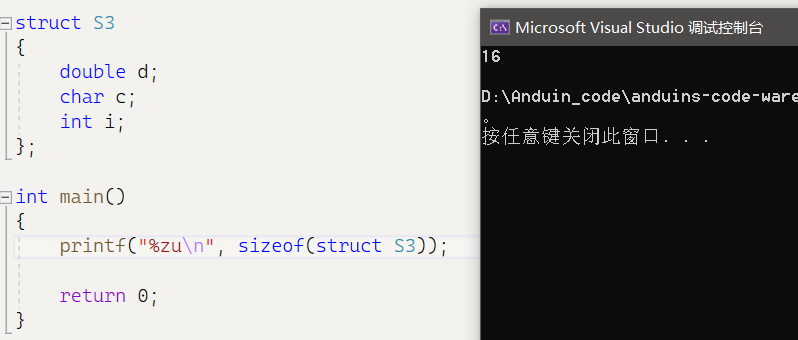
structS3{double d;char c;int i;};
分析:
- d为结构体第一个成员,在结构体变量偏移量为0的地址处,占用8个字节。
- c的大小为1,默认对齐数为8,取其较小值为1。对齐到1的倍数处,也就是偏移为8的位置,占用1个字节。
- i的大小为4,默认对齐数为8,取其较小值为4。对齐到4的倍数处,也就是偏移为12的位置,占用4个字节。9,10,11三个字节被浪费。
- 结构体的总大小为最大对其数的整数倍。d,c,i的对齐数分别为8,1,4。结构体大小为8的倍数,当前结构体当前所占空间大小为16字节,为当前大小。

运行结果:
题2:
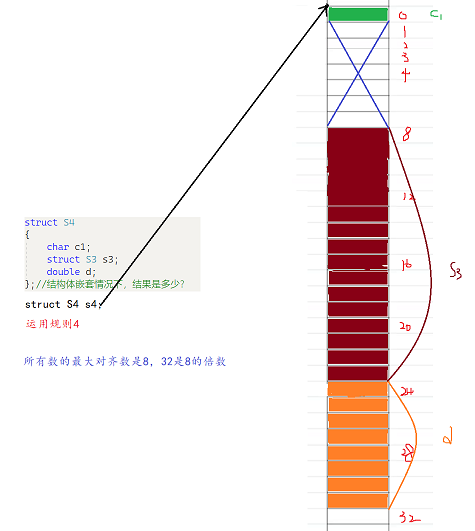
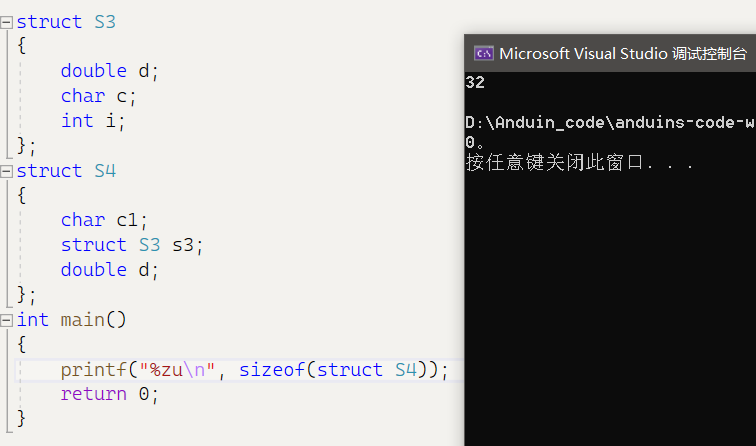
structS4{char c1;structS3 s3;double d;}//结构体嵌套情况下,结果是多少?
分析:
结构体嵌套结构体,这时就要用到我们的第四条规则:
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
- c1为结构体第一个成员,在结构体变量偏移量为0的地址处,占用1个字节。
- s3为结构体第二个成员,为嵌套的结构体,对齐到自己的最大对齐数的整数倍处,s3的最大对齐数我们在上面算过,为8,那么就对齐到8字节处,上面1~7字节被浪费。s3占用16个字节。
- d为结构体第三个成员,默认对齐数为8,自身大小为8,所以对齐到8的倍数处,对齐到24字节处,占用8个字节。
- 结构体总大小为所有最大对其数的整数倍处。c1,s3,d最大对齐数为1,8,8。对齐到8的倍数处,结构体当前所占空间大小为32字节,为8的倍数,所以结构体大小为32字节。
运行结果:
8.5 为什么存在内存对齐?
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
下面对第二条原因做出一定解释:
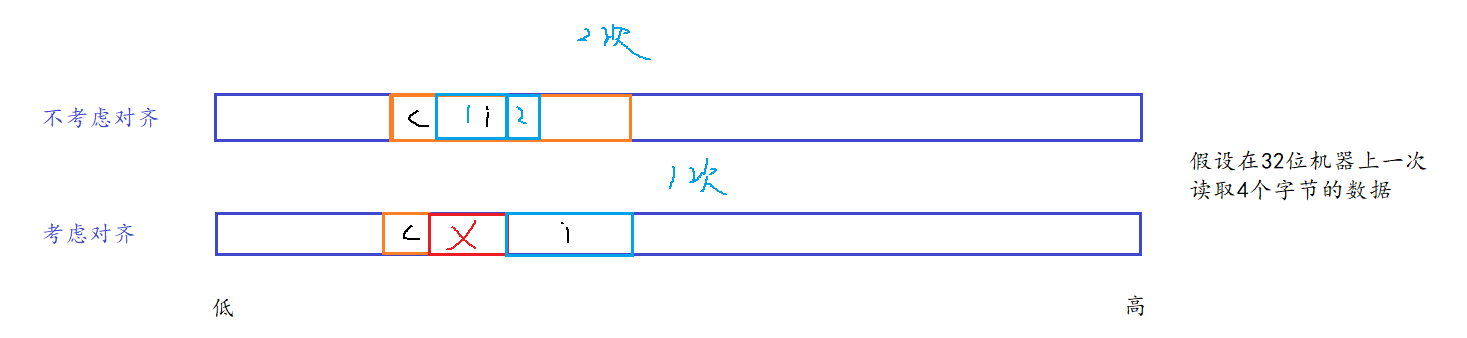
假设一次读取4个字节的数据,要读取到内存中的i。
在不考虑内存对齐的情况下,需要读取两次,从c开始读,第一次读取i的三个字节,第二次读取剩余的一个字节。
而在考虑内存对齐的情况下,需要读取一次,直接从i开始读,读取i的四个字节。
总体来说:
结构体的内存对齐是拿空间换取时间的做法。
8.6 设计结构体的细节
如何在设计结构体时,既满足对齐,又要节省空间?
让占用空间小的成员尽量集中在一起。
这样,浪费的字节也就少了。并且,当成员集中到一定程度时,说不定就正好放置到下一个元素的对齐位置上方,让空间最大程度上得到利用。
例如:
structS1{char c1;int i;char c2;};//更好structS2{char c1;char c2;int i;};
S1和S2类型的成员一模一样,但是S1和S2所占空间的大小有了一些区别,S2大小比S1小。因为S2把占用空间小的成员集中在一起。
8.7 如何修改默认对齐数
之前我们见过了
#pragma
这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。
#pragmapack(4)//设置默认对齐数为4#pragmapack()//恢复默认对齐数
我们不妨设想一下,如果将默认对齐数设置为1,结构体的大小会是多少:
#pragmapack(1)structS1{char c1;//从0开始对齐int i;//4 1 对齐数为1,对齐到1位置处char c2;//1 1 对齐数为1,从5开始对齐//最大对齐数为1,所以结构体大小为1的倍数即可//6,其实也就是没对齐};#pragmapack()intmain(){printf("%d\n",sizeof(structS1));//6return0;}
- c1为结构体第一个成员,在结构体变量偏移量为0的地址处,占用1个字节。
- i的大小为4,默认对齐数为1,取其较小值为1。对齐到1的倍数处,也就是偏移为1的位置,占用4个字节。
- c2的大小为1,默认对齐数为1,取其较小值为1。对齐到1的倍数处,也就是偏移为5的位置,占用1个字节。
- 结构体的总大小为最大对其数的整数倍。c1,i,c2的对齐数分别为1,1,1。结构体大小为1的倍数,所以不需要调整结构体的大小,直接为当前大小,为6个字节。
相当于对齐了个寂寞~
运行结果:

但是需要注意的是:
虽然支持这样修改默认对齐数,但是也不要胡乱修改,一般默认对齐数修改为2^n,机器在读取时,读取的字长为4/8个字节,尽量朝着适合读写的方法来设定。但是当结构体在对齐方式上不合适的时候,我们可以自己更改默认对齐数。
9. 结构体传参
structS{int data[1000];int num;};structS s ={{1,2,3,4},1000};//结构体传参voidprint1(structS s){printf("%d\n", s.data[0]);//结构体变量.结构体成员访问结构体成员}//结构体地址传参voidprint2(structS* ps){printf("%d\n",(*ps).data[0]);//*ps访问到结构体,结构体变量.操作符访问成员printf("%d\n", ps->data[0]);//结构体指针->结构体成员访问成员}intmain(){structS ss ={{1,2,3,4,5},100};print1(ss);//传结构体print2(&ss);//传地址return0;}
运行结果:

两个函数的作用是相同的,但是上面的print1和print2函数哪个好?
在
结构体成员的访问
部分中,我们是通过
print
函数对结构体成员进行访问并打印的,而这两种传参方式截然不同,一个为
结构体变量ss(传值调用)
,一个为
结构体变量的地址&ss(传址调用)
。
那么这两种传参方式哪个更好呢?当然是第二种方式,传址调用的方式。
可能大家可能会觉得print1比较好,原因是print2可能可以通过结构体指针改变结构体的内容,但是这完全可以避免,只需要对*ps加上const修饰,便可避免这种情况。
认为第二种方法更优的原因还因为:
结构体传参时,若实参为结构体变量,那么就要创建变量的一份临时拷贝,需要大量的空间,而实参为结构体指针的话,形参的大小为4/8个字节,大大节省了空间。
而函数传参的时候,参数是需要压栈的。
如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,所以会导致性能的下降。简单来说若结构体空间过大,在压栈时需要使用大量的空间,不仅浪费了空间,更浪费了时间!
结论:结构体传参时,要传结构体的地址。
注:结构体传值时,实参结构体的地址可能和形参结构体的地址相同,编译器可能不会创建临时空间,自己进行了优化,我们使用的空间依然可能是实参的空间,为了避免这些乱七八糟的优化,我们还是选择传址调用~
10. 结语
到这里,本篇博客到此结束。相信通过这篇博客,大家对结构体也有了一定的认识。而在下篇博客中,我将利用结构体的知识,进行简易通讯录的实现,更多精彩内容,敬请期待!
如果觉得anduin写的还不错的话,还请一键三连!如有错误,还请指正!
我是anduin,一名C语言初学者,我们下期见!
版权归原作者 进击的安度因 所有, 如有侵权,请联系我们删除。