
Torch Compile(torch.compile)虽然最初随PyTorch 2.0一同推出,但经过多次更新和优化后,才得以可靠地支持大多数大型语言模型(LLMs)。
在推理方面,torch.compile能够真正加快解码速度,同时仅略微增加内存使用量。
在本文中,我们将探讨torch.compile的工作原理,并测量其对LLMs推理性能的影响。要在代码中使用torch.compile,只需添加一行代码即可。在本文中,我使用Llama 3.2进行了测试,并尝试了与bitsandbytes量化结合使用,分别在两种不同的GPU上进行了测试:Google Colab的L4和A100。
Torch Compile:如何让模型更快?
torch.compile提供了一种通过将标准PyTorch代码转换为优化后的机器代码来加速模型的方法。这种称为即时编译(JIT,Just-In-Time)的方法,使代码在特定硬件上运行更加高效,即比普通Python代码更快。对于复杂模型而言,即使是很小的速度提升也能累积成显著的时间节省。
torch.compile背后的核心工具包括PyTorch编译器中的几个重要组件:
- TorchDynamo:该工具在执行期间修改Python代码,以允许PyTorch将操作捕获为图,然后由torch.compile进行优化。
- AOTAutograd:该工具根据捕获的图生成训练所需的梯度。
- PrimTorch:它将复杂操作简化为更小、更易于管理的组件。
- TorchInductor:该组件接受优化后的图,并为GPU、CPU和其他硬件设置生成硬件优化代码。
- torch.compile的一个主要优势是易于使用。它只需将模型用torch.compile包裹起来,即可生成优化版本。它与现有的PyTorch代码无缝集成。
首次运行带有torch.compile的模型时,它会执行初始优化,后续调用将受益于这个更快的版本。torch.compile遵循一个三步过程:
- 它将模型分解为更小、优化的段,保留任何不可优化的代码。
- 调整PyTorch操作以适应特定的硬件后端。
- 编译这些部分,以在你的设备上实现最大效率,主要通过减少内存传输来实现。
其他优化包括将多个操作合并为单个内核调用,并使用CUDA图捕获来提升GPU性能。虽然并非模型的每个部分都能被优化,但torch.compile通常能加速大多数模型,而无需进行结构更改。
但是也存在一些限制。具有不同输入形状的模型可能会触发重复编译,从而减慢速度。一致的输入形状有助于避免此问题,尽管对于LLMs的推理和微调而言,这通常不是问题。
编译后的模型也可能消耗更多内存或运行速度低于预期,因此建议进行基准测试以确认torch.compile是否提高了特定设置下的性能。在分布式设置中,优化可能并不总是均匀应用,因此最好在配置分布式进程之前编译模型。
Torch Compile与Transformers
为了充分利用torch.compile的加速效果,我们可以通过将模型传递给它来轻松启用torch.compile,如下所示:
importtorch
model=torch.compile(model)
Hugging Face发布了一些关于torch.compile对视觉模型影响的有趣基准测试结果。
让我们看看它在LLMs上的表现如何。
Torch Compile在LLMs上的应用
我尝试使用torch.compile与Llama 3.2 3B模型结合。
importtorch
fromtransformersimportAutoTokenizer, AutoModelForCausalLM
checkpoint="meta-llama/Llama-3.2-3B"
tokenizer=AutoTokenizer.from_pretrained(checkpoint)
model=AutoModelForCausalLM.from_pretrained(checkpoint, device_map="cuda")
model=torch.compile(model)
为了对使用torch.compile的推理进行基准测试,我使用了optimum benchmark(Apache 2.0许可),批处理大小为1,序列长度为1024。我们将特别关注预填充(KV缓存创建、编码)和解码(标记生成)阶段的吞吐量(标记/秒),以及模型编译后的内存消耗。
torch.compile在首次使用时需要一些时间来编译模型。为了获得准确的基准测试结果,最好先运行几次预热迭代。这样,推理速度和内存使用等性能指标仅在模型完全编译后进行测量。
我还测试了torch.compile对使用bitsandbytes(BnB)量化到4位的Llama 3.2(3B)模型的影响。
在A100 GPU(Google Colab)上的结果: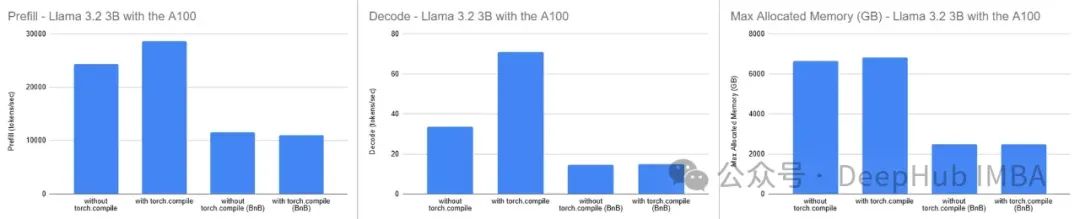
torch.compile显著提高了解码速度,吞吐量几乎翻倍(如中间图表所示)。它还改善了预填充阶段的性能,尽管程度较小。然而,当在A100 GPU上将torch.compile与bitsandbytes量化模型结合使用时,对性能的影响很小,甚至可能略微减慢预填充阶段的速度。
在内存使用方面,如预期那样,编译后的模型消耗了更多内存。增加的内存约为+200 MB(约占模型大小的3%),相对较小且易于管理。
在L4 GPU(Google Colab)上的结果: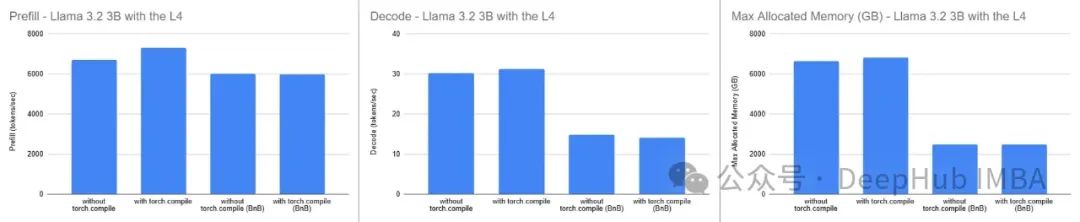
在L4 GPU上,其内存是A100的一半,我们观察到了类似的内存消耗增加,但加速效果很小。这与A100上的结果形成鲜明对比,表明torch.compile的有效性可能因使用的GPU而异。
简而言之,值得在你的特定GPU上对torch.compile进行基准测试,以查看它是否提供了预期的性能提升。
总结
torch.compile可以在标准设置中显著加快推理速度,特别是在不涉及量化的情况下。但是建议在模型开发过程的最后阶段才启用torch.compile,即在你已经配置好所有计划用于生产的特性和技术之后。这种方法至关重要,因为根据你的模型和GPU,torch.compile可能与某些配置的行为不符合预期。
例如可能会遇到FlashAttention和bfloat16的兼容性问题,它们并不总是能与torch.compile顺利配合使用。
如果你正在使用LoRA适配器,请注意加速收益可能较低。LoRA组件具有高度动态性,这使得它们难以有效编译。
但是torch.compile可以是一个强大的加速工具,铜鼓哦仔细测试可以确保它与你的特定设置和要求相符。
作者:Benjamin Marie