
🐥今天我们将对大数据计算管理部分的数据倾斜做一个总结,本文讲述主要是以spark计算引擎主,相信我,这可能是你看见过最详细的数据倾斜解决方案。对往期内容感兴趣的同学可以参考如下内容👇:
- 链接: spark学习之sparksql语法优化.
- 链接: spark学习之资源调度.
- 链接: spark学习之执行计划explain.
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🍃本文主要从解决数据倾斜倾斜问题的角度出发,对各种情况的数据倾斜的解决方式进行总结。
目录
1. 数据倾斜的产生
1.1 数据倾斜的现象
什么情况下会产生数据倾斜呢?一般情况来说,我们在执行一段任务代码时,会出现在一定时间内运行不出结果,于是我就去查看任务运行的ui界面,我们发现,有几个task还在一直在运行,而其他的task已经运行完成了,最后可能就接着报内存溢出的问题。

1.2 数据倾斜的原因
数据倾斜一般是发生在 shuffle 阶段,比如使用了一些shuffle类的算子,如 distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup 等,涉及到数据重分区,如果其中某一个 key 数量特别大,就会发生数据倾斜。
2. 数据倾斜的处理
2.1 单表数据倾斜优化
所谓单表数据倾斜是指我们在处理一张表时产生了数据倾斜,如使用group by后sum、count等聚合函数的时候,会在单表上产生shuffle,则容易产生数据倾斜。
2.1.1 预聚合
预聚合是指:通常 Spark SQL 在 map 端会做一个partial aggregate(通常叫做预聚合或者偏聚合),即在 shuffle 前将同一分区内所属同 key 的记录先进行一个预结算,再将结果进行 shuffle,发送到 reduce 端做一个汇总,类似 MR 的提前 Combiner。(这部分在执行过程中会自动优化不用太操心。)
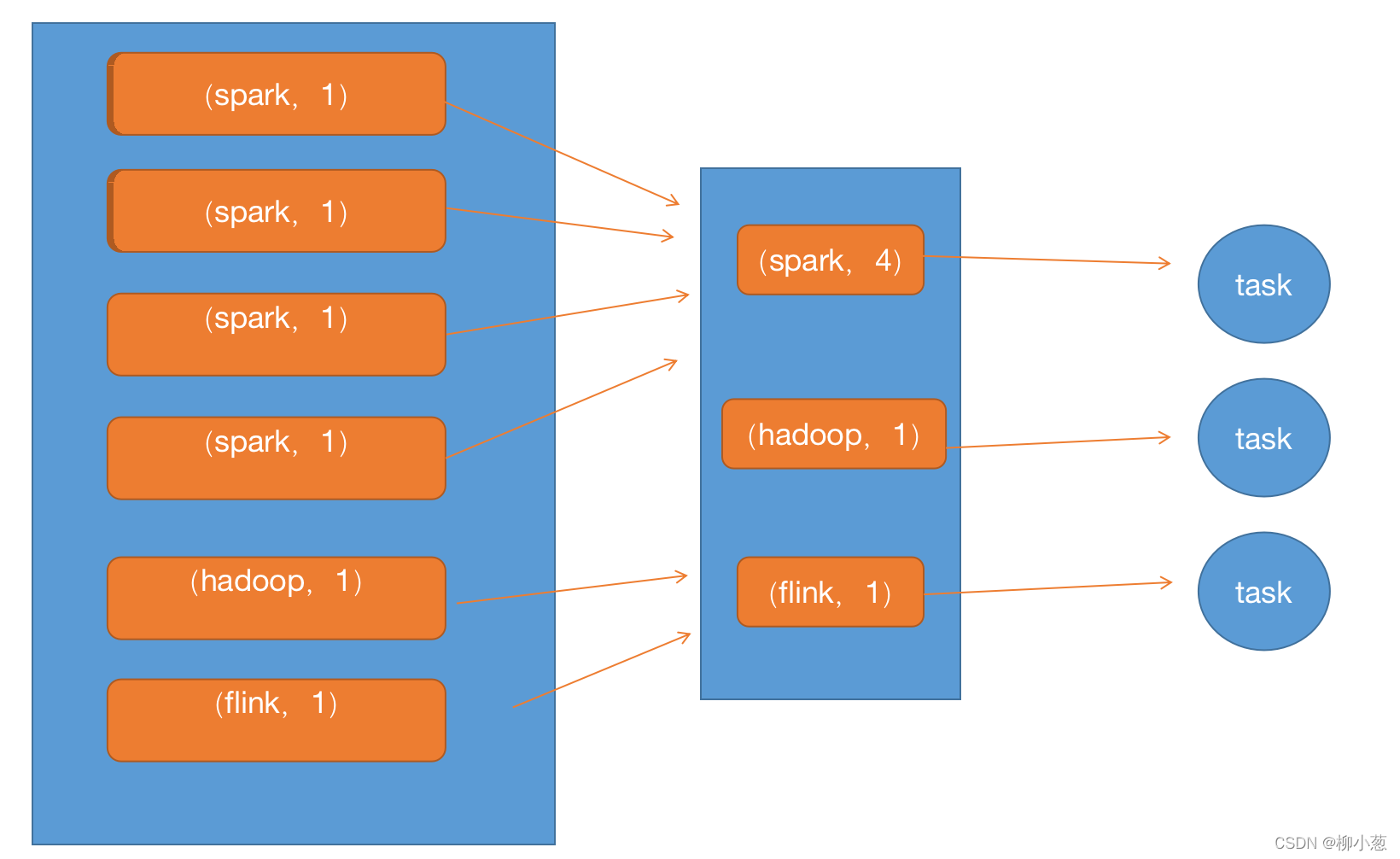
上图:预聚合过程
2.1.1 两阶段聚合(加盐+去盐)
在mapt端的任务较少时,预聚合可以很好的解决问题,但是在分片较多的情况,map端预聚合后也会产生大量的倾斜数据,这时候需要加盐局部聚合然后再去盐全局聚合。如果是空值较多,则选择加盐或者直接过滤。(具体操作方法可以使用嵌套子查询来完成。比如先concat,再split。)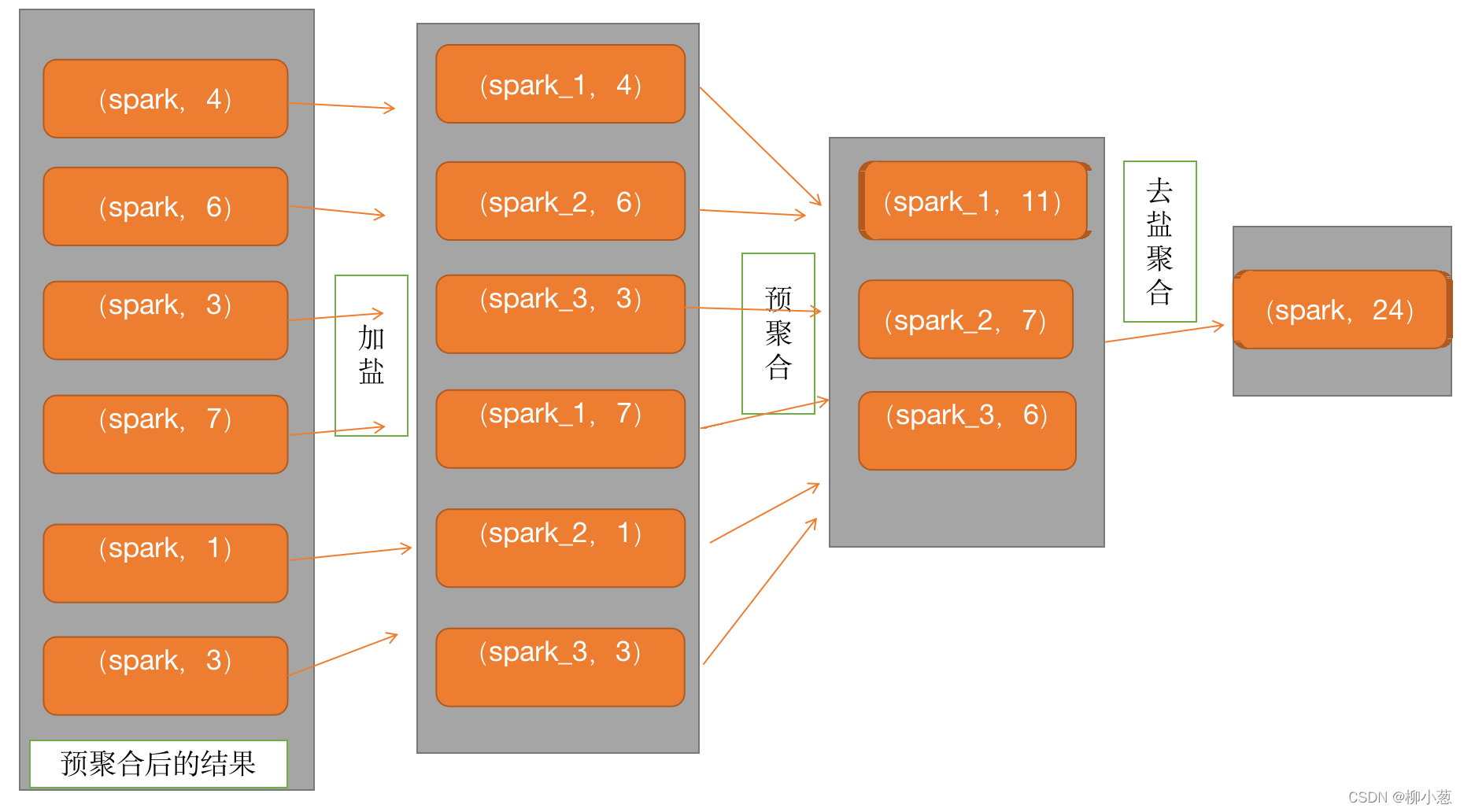
上图:两阶段聚合过程
2.2 Join 数据倾斜优化
在大表join小表阶段,在reduce端进行join时,某个特别多的key被分在一个分区中进行笛卡尔积的操作。这个reduce任务就会出现数据倾斜。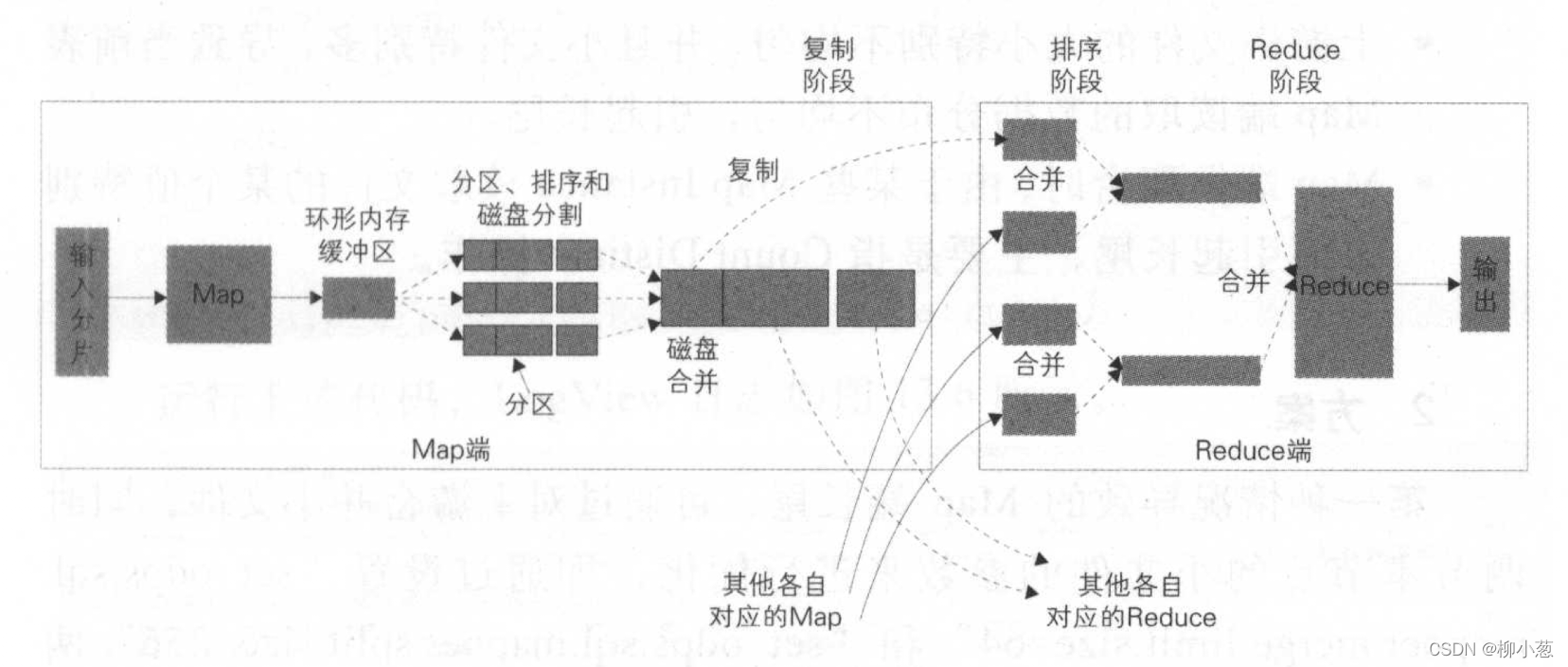
上图:map和reduce的两个过程
2.2.1 map join
适用于小表 join 大表。小表足够小,可被加载进 Driver 并通过 Broadcast 方法广播到各个 Executor 中。在map端完成join后,不会产生shuffle操作,有效避免数据倾斜。
例如:student表是大表,score表是小表。
-- 写法1select/*+ MAPJOIN(s2)*/
s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s leftjoin score s2
on s.s_id=s2.s_id
where s2.s_score>70-- 写法2select/*+ BROADCAST(s2)*/
s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s leftjoin score s2
on s.s_id=s2.s_id
where s2.s_score>70-- 写法3select/*+ BROADCASTJOIN(s2)*/
s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s leftjoin score s2
on s.s_id=s2.s_id
where s2.s_score>70
2.2.2 map join 发生倾斜
在生产环节中,我们可能会遇见map join倾斜的情况,比如像阿里云的maxcomputer,在发生大表join小表时,会自动使用mapjoin,但并不是每次都mapjoin都能很好的解决问题(比如: Count Distinct ),如果mapjoin发生数据倾斜,可以采用如下方式转化为reducejoin:
select
s.s_id,s2.c_id,s2.s_score,s.s_sex
from(select s_id,s_sex
from student
distribute by rand()--选取数据时分区,避免mapjoin)s
leftjoin score s2
on s.s_id=s2.s_id
where s2.s_score>70
通过“ distribute by rand()”会将 Map 端分发后的数据重新按照随 机值再进行一次分发。原先不加随机分发函数时, Map 阶段需要与使用 MapJoin 的小表进行笛卡儿积操作, Map 端完成了大小表的分发和笛卡儿积操作。使用随机分布函数后, Map 端只负责数据的分发,不再有复杂的聚合或者笛卡儿积操作,因此不会导致 Map 端倾斜。
2.2.3 热点值 join(打散大表 扩容小表)
热点值join是指:热点key导致的数据倾斜,并且 Join 的输入比较大无法使用MapJoin,则可以先将热点 key 取出,对于主表数据用热点 key 切分成热点数据和非热点数据两部分分别处理,最后合并。
解决逻辑如下:
- 假设我们存在数据倾斜的表1和正常表2
- 拆分热点数据和非热点数据:将存在倾斜的表,根据抽样结果,拆分为倾斜 key( tmp1)和没有倾斜 key(tmp2)的两个数据集。
- 加盐: 将表1的 key 全部加上随机前缀;对另外一个不存在严重数据倾斜的数据集(表2)整体与随机前缀集作笛卡尔乘积(即将表2数据量扩大 N 倍,得到 rand表)。
- union:将(打散的表1 join 扩容的rand表(join后去盐))union(没有倾斜的tmp2 join 表2)
3. 总结
本文从单表倾斜和join倾斜两个角度说明了数据倾斜的解决方法,具体的细节还需要大家遇见到实际情况,然后做具体的调整。如果还有其他的数据倾斜的现象,还请大家指正。
4. 参考文章
- 《尚硅谷大数据技术之 Spark 调优》
- 《spark权威指南》
- 以及实习期间碰见的问题
版权归原作者 柳小葱 所有, 如有侵权,请联系我们删除。