
目录
Pandas简介
pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
pandas 是第三方库,需要单独安装才能使用。如果你要在本地环境运行的话,可以通过以下命令安装:
pip install pandas -i https://pypi.doubanio.com/simple/
这句话后面 -i https://pypi.doubanio.com/simple/ 表示使用豆瓣的源,这样安装会更快
一般情况下,我们会像下面这样引入 pandas 模块:
import pandas as pd
将 pandas 简写成 pd 几乎成了一种不成文的规定。因此,只要你看到 pd 就应该联想到这是 pandas。
Pandas中的两个主要数据结构
要使用 pandas,你首先得熟悉它的两个主要数据结构:
- Series(一维数据)
- DataFrame(二维数据)
这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例
Series
创建
Series 是一种类似于 Numpy 中一维数组的对象,它由一组任意类型的数据以及一组与之相关的数据标签(即索引)组成。举个最简单的例子:
import pandas as pd
print(pd.Series([2,4,6,8]))
结果:
0 2
1 4
2 6
3 8
dtype: int64
左边的是数据的标签,默认从 0 开始依次递增。右边是对应的数据,最后一行表明了数据类型。
我们也可以像下面这样使用 index 参数自定义数据标签:
import pandas as pd
print(pd.Series([2,4,6,8], index=['a','b','c','d']))
结果:
a 2
b 4
c 6
d 8
dtype: int64
我们还可以直接使用字典同时创建带有自定义数据标签的数据,pandas 会自动把字典的键作为数据标签,字典的值作为相对应的数据。
import pandas as pd
print(pd.Series({'a':2,'b':4,'c':6,'d':8}))
结果:
a 2
b 4
c 6
d 8
dtype: int64
综上在pd.Series()中传入序列即可创建Series
访问
访问 Series 里的数据的方式,和 Python 里访问列表和字典元素的方式类似,也是使用中括号加数据标签的方式来获取里面的数据。
例如:
import pandas as pd
s1 = pd.Series([2,4,6,8])
s2 = pd.Series({'a':2,'b':4,'c':6,'d':8})print(s1[0])# 输出:2print(s2['b'])# 输出:4
有了带标签的数据有什么用呢?为什么不直接使用 Python 自带的列表或字典呢?是因为 pandas 有着强大的数据对齐功能。
举个例子:
假设你开了个小卖部,每天统计了一些零食的销量,你想看一下前两天的总销量如何。使用 pandas 的话,你可以这样写:
import pandas as pd
s1 = pd.Series({'辣条':14,'面包':7,'可乐':8,'烤肠':10})
s2 = pd.Series({'辣条':20,'面包':3,'可乐':13,'烤肠':6})print(s1 + s2)
上面直接将两个 Series 相加的结果如下:
辣条 34
面包 10
可乐 21
烤肠 16
dtype: int64
pandas 自动帮我们将相同数据标签的数据进行了计算,这就是数据对齐。
而如果不用 Series,只用列表或字典,我们还要使用循环来进行计算。而用了 pandas 的 Series,只需要简单的相加即可。
你可能会有疑问,如果两天卖出的零食不一样怎么办,pandas 还能进行数据对齐吗?
import pandas as pd
s1 = pd.Series({'辣条':14,'面包':7,'可乐':8,'烤肠':10})
s2 = pd.Series({'辣条':20,'面包':3,'雪碧':13,'泡面':6})print(s1 + s2)
上面的数据中,只有辣条和面包这两个数据标签是相同的,剩下的数据标签各不相同。上述代码的运行结果如下:
可乐 NaN
泡面 NaN
烤肠 NaN
辣条 34.0
雪碧 NaN
面包 10.0
dtype: float64
可以看到,对于数据标签不相同的数据,运算后结果是 NaN。NaN 是 Not a Number(不是一个数字)的缩写,因为其中一个 Series 中没有对应数据标签的数据,无法进行计算,因此返回了 NaN。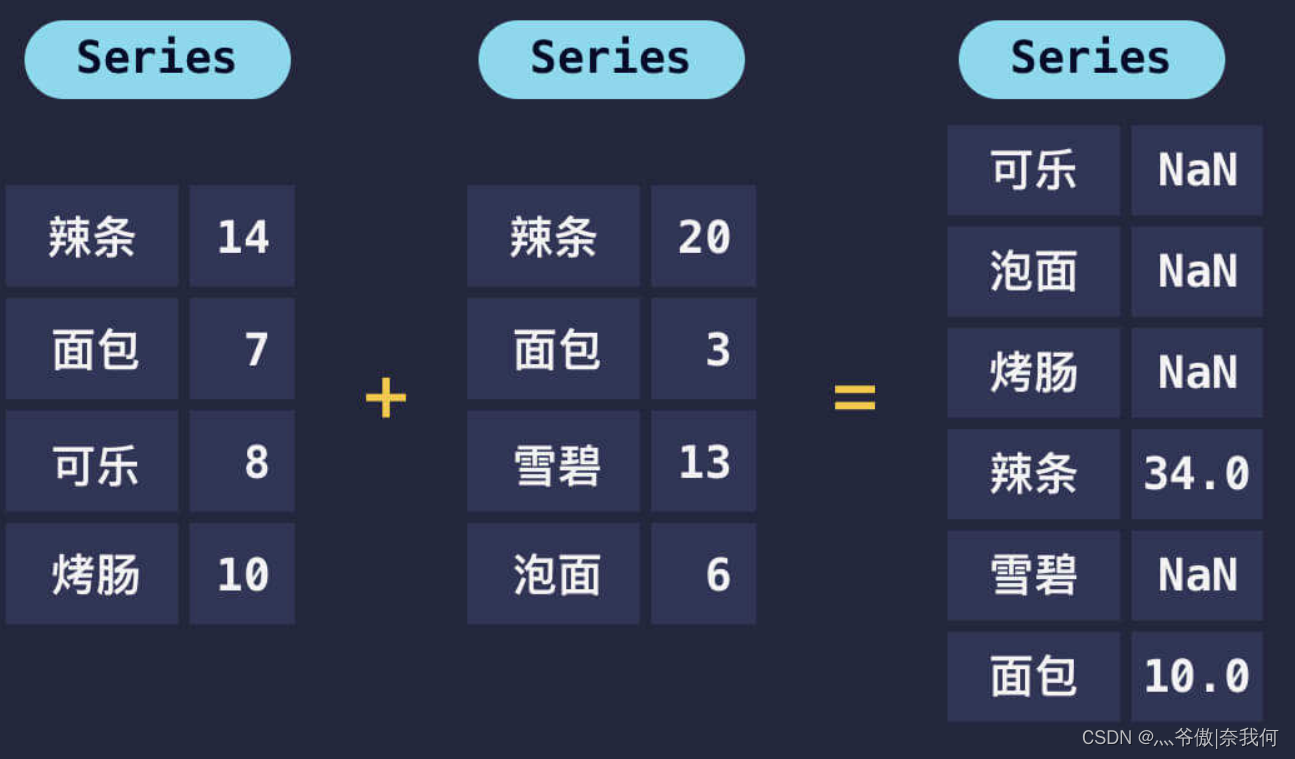
其实对于这种情况我们可以让没有的数据默认为 0,然后再进行计算。
调用 Series 的 add() 方法,并设置好默认值即可。
代码实现:
import pandas as pd
s1 = pd.Series({'辣条':14,'面包':7,'可乐':8,'烤肠':10})
s2 = pd.Series({'辣条':20,'面包':3,'雪碧':13,'泡面':6})print(s1.add(s2, fill_value=0))# fill_value 为数据缺失时的默认值
结果:
可乐 8.0
泡面 6.0
烤肠 10.0
辣条 34.0
雪碧 13.0
面包 10.0
dtype: float64
add() 方法对应的是加法,数学中的四则运算在 pandas 中都有一一对应的方法,它们的用法都是类似的。具体对应关系如下图所示:
DataFrame
Series 是一维数据,而 DataFrame 是二维数据。你可以把 DataFrame 想象成一个表格,表格有行和列这两个维度,所以是二维数据。
或者按列分,每一列数据加上左边的数据标签也是一个 Series。
现在我们用DataFrame实现上面的表格:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
df = pd.DataFrame({'辣条':[14,20],'面包':[7,3],'可乐':[8,13],'烤肠':[10,6]})print(df)
上面代码的运行结果如下:
辣条 面包 可乐 烤肠
0 14 7 8 10
1 20 3 13 6
因为我们的表格中有中文,中文占用的字符和英文、数字占用的字符不一样,因此需要调用 pd.set_option() 使表格对齐显示。如果你是使用 Jupyter 来运行代码的,Jupyter 会自动渲染出一个表格,则无需这个设置。
创建
构建 DataFrame 的办法有很多,最常用的一种是传入一个由等长列表组成的字典。即字典里每个值都是列表,且它们的长度必需相等。这样我们就得到了一个表格,字典的键会作为表格的列名。最左边的是索引,也是默认从 0 开始依次增加。当然,我们也可以在构建 DataFrame 的时候传入 index 参数来自定义索引。
例如:
import pandas as pd
data ={'辣条':[14,20],'面包':[7,3],'可乐':[8,13],'烤肠':[10,6]}
df = pd.DataFrame(data, index=['2020-01-01','2020-01-02'])print(df)
结果:
辣条 面包 可乐 烤肠
2020-01-01 14 7 8 10
2020-01-02 20 3 13 6
列的查改增删
查看列
为了减少重复代码的出现,接下来的内容都基于下面的代码。
import pandas as pd
df = pd.DataFrame({'辣条':[14,20],'面包':[7,3],'可乐':[8,13],'烤肠':[10,6]})# 结果
辣条 面包 可乐 烤肠
01478101203136
如果我们只想查看有关可乐的销量数据,我们可以这样写:
print(df['可乐'])
写法和字典取值类似,用中括号加列名的方式获取对应列的数据。运行结果是表格中可乐一列的数据,它是一个 Series,结果如下所示:
0 8
1 13
Name: 可乐, dtype: int64

我们还能同时选择多列进行查看,只要把多个列名放到列表当中即可。
print(df[['可乐','辣条']])
并且 pandas 会按照列表中列名的顺序重新排列,结果如下:
可乐 辣条
0 8 14
1 13 20

修改列
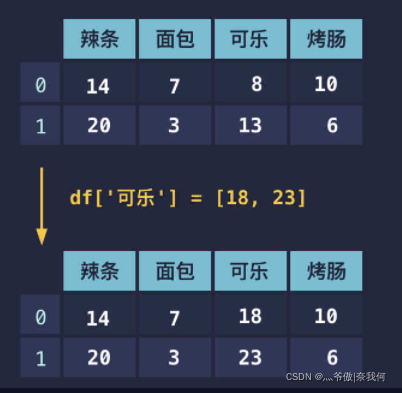
如果我们发现表格中的数据有错误,想要修改,这其实非常的简单。和字典修改值的方式也类似,直接对已有列重新赋值即可。
df['可乐']=[18,23]print(df)
结果:
辣条 面包 可乐 烤肠
0 14 7 18 10
1 20 3 23 6
新增列
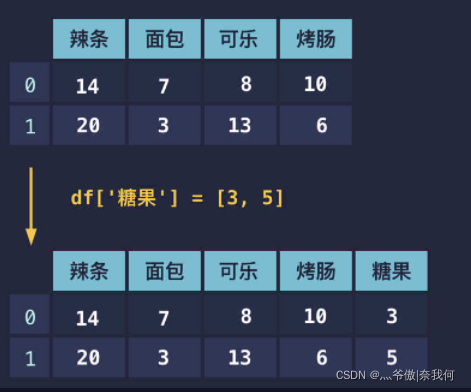
如果想要新增一列同样也非常的简单,对表格中不存在的列直接赋值就能添加新的列了(还是跟字典一样)。
df['糖果']=[3,5]print(df)
结果:
辣条 面包 可乐 烤肠 糖果
0 14 7 8 10 3
1 20 3 13 6 5
删除列
删除列和字典删除元素不一样,需要用到 drop() 方法。
df.drop('面包', axis=1, inplace=True)print(df)# 或者 print(df.drop('面包', axis=1))
drop()
方法的参数:
- 第一个参数是要删除的列名或索引
- axis 表示针对行或列进行删除,axis = 0 表示删除对应的行,axis = 1 表示删除对应的列,axis 默认为 0。
- 最后的 inplace = True 表示直接修改原数据,否则 drop() 方法只是返回删除后的表格,对原表格没有影响。

导入/导出 表格文件以及常规操作
假设我们的电脑上有下面这样的一个表格文件,文件名为 2019年销售数据.csv。
首先我们来将其导入到 pandas 中,代码如下:
import pandas as pd
df = pd.read_csv('2019年销售数据.csv')print(type(df))# 输出:<class 'pandas.core.frame.DataFrame'>
可以看到,读取的内容是 DataFrame 类型的。我们可以根据 DataFrame 的知识对其进行一系列的操作。
用 pandas 导出表格数据也很简单,只需一行代码:
df.to_csv('2019年销售数据.csv', index=False)
上面代码中保存的表格名和原来的表格名一样,会覆盖原来的表格。如果你想保存到新的表格文件中,只要换个不同的表格名即可。传入 index=False 是因为不希望将最左侧的索引保存到文件中。
①除了 csv 文件,Excel 文件也是常见的表格文件。导入导出 Excel 文件的代码是类似的,只是方法是 read_excel() 和 to_excel().
②如果你的 Excel 文件中有多个工作表的话,还可以通过 sheet_name 参数指定对应的工作表,默认情况下会读取第一张工作表。
head()方法
读取到表格数据后,可能表格数据很多,我们想大致确认一下表格内容,不需要打印出完整的表格。这时我们可以使用 head() 方法来查看前 5 条数据。
import pandas as pd
df = pd.read_csv('2019年销售数据.csv')print(df.head())
结果:
销售员 团队 第一季度 第二季度 第三季度 第四季度
0 刘一 A 6324 5621 6069 6005
1 陈二 B 4508 3391 5933 5002
2 张三 C 3426 3549 5872 5759
3 李四 D 2104 3939 3285 3461
4 王五 A 4830 5763 2923 4033
head() 方法还支持传入参数来控制显示前多少条数据,比如前 2 条数据:
import pandas as pd
df = pd.read_csv('2019年销售数据.csv')print(df.head(2))
结果:
销售员 团队 第一季度 第二季度 第三季度 第四季度
0 刘一 A 6324 5621 6069 6005
1 陈二 B 4508 3391 5933 5002
tail()方法
除了查看开头的一些数据,还可以使用 tail() 方法查看末尾的数据。用法和 head() 一致,默认显示 5 条,可以传入参数来改变显示的条数。
例如:
import pandas as pd
df = pd.read_csv('2019年销售数据.csv')print(df.tail())
结果:
销售员 团队 第一季度 第二季度 第三季度 第四季度
15 许十六 D 5369 3420 5169 5790
16 钱十七 A 6924 5912 5907 5263
17 沈十八 B 2733 2649 3402 3164
18 韩十九 C 1519 1553 1411 2091
19 杨二十 D 3268 5090 3898 4180
info()方法
我们还能通过 info() 方法查看整个表格的大致信息
例如:
import pandas as pd
df = pd.read_csv('2019年销售数据.csv')print(df.info())
运行结果及主要含义如下图所示:
通过 info() 方法我们可以对表格大致有个了解,知道有几行几列,以及哪列有多少条缺失数据。
describe()方法
我们还能通过 describe() 方法来快速查看数据的统计摘要,方便我们对数据有一个直观上的认识。
例如:
import pandas as pd
df = pd.read_csv('2019年销售数据.csv')print(df.describe())
结果:
第一季度 第二季度 第三季度 第四季度
count 20.000000 20.000000 20.000000 20.000000
mean 3969.150000 4252.250000 4309.300000 4284.700000
std 1518.736084 1352.492275 1646.188871 1286.032377
min 1501.000000 1553.000000 1272.000000 2091.000000
25% 2760.000000 3412.750000 3194.500000 3469.250000
50% 4162.000000 4392.500000 4536.000000 4120.500000
75% 4888.500000 5412.250000 5818.000000 5202.250000
max 6924.000000 6176.000000 6499.000000 6683.000000
生成的摘要从上往下分别表示数量、平均数、标准差、最小值、25% 50% 75% 位置的值和最大值。
sort_values()方法
例如:
df.sort_values('总和', ascending=False, inplace=True)
sort_values() 方法第一个参数是排序针对的列名,排序默认是升序的,因此要将 ascending 设为 False 改成降序,这样总销售额最高的会排在第一个。最后的 inplace=True 和前面的 drop() 方法中的 inplace 一样,表示修改原数据,否则只是返回排序后的数据,对原数据没影响。
继承自Series的方法
因为 DataFrame 的每一列都是一个 Series,我们还可以调用 max()、min()、mean()、sum() 等方法来计算最大值、最小值、平均值以及求和等。
例如:(根据总和列进行相关操作)
# 总销售额最大值
df['总和'].max()# 总销售额最小值
df['总和'].min()# 总销售额平均值
df['总和'].mean()# 所有人的总销售额求和
df['总和'].sum()

重要:到底如何去理解Pandas中的axis=0,axis=1
其实很多人应该已经发现了在NumPy中,例如我们求数组的平均值
- axis = 0,代表列求平均值
- axis = 1,代表行求平均值
Pandas保持了Numpy对关键字axis的用法,但是在例如我们删除列的时候发现:
- axis = 0,代表删除行
- axis = 1,代表删除列
这就让很多人摸不清楚头脑,怎么回事?
其实我们普遍的理解是:
axis = 0 代表列
axis = 1 代表行
但是更加准确的理解应该是:
axis=0表示跨行
axis=1表示跨列
作为方法动作的副词
当时我看过很多文章,我认为他们讲的其实并不是非常清楚,我在这里用一个笨办法,保证大家都可以理解。
我仍然使用经典的求最大值,和删除列举例子。
①先看求最大值: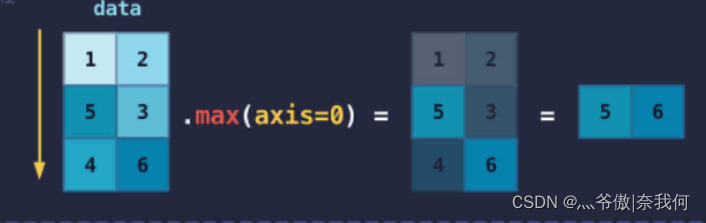
例如我们现在想求列的最大值,我们随便拿一列出来,例如
1
5
4
按照方法:
一xx的(执行的操作)
若xx为‘行行’,则axis = 1
若xx为‘列列’,则axis = 0
很明显是一列列的求最大值,而不是一行行的求最大值。故axis = 0。
②同样再看删除列
例如我们想删除面包列,那么我们就把面包列单拿出来:
面包
7
3
很显然是一行行的删除面包列,而不是一列列的删除面包列,故axis = 1
其他情况都可以这么去理解。
版权归原作者 灬爷傲|奈我何 所有, 如有侵权,请联系我们删除。